This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon A data scientist’s ability to extract value from data is closely related to how well-developed a company’s data storage and processing infrastructure is.
Introduction Organizations with a separate transactional database and datawarehouse typically have many dataengineering activities. For example, they extract, transform and load data from various sources into their datawarehouse.
This article was published as a part of the Data Science Blogathon. Overview ETL (Extract, Transform, and Load) is a very common technique in dataengineering. Traditionally, ETL processes are […]. The post Crafting Serverless ETL Pipeline Using AWS Glue and PySpark appeared first on Analytics Vidhya.
Introduction Processing large amounts of raw data from various sources requires appropriate tools and solutions for effective data integration. Building an ETL pipeline using Apache […]. The post ETL Pipeline with Google DataFlow and Apache Beam appeared first on Analytics Vidhya.
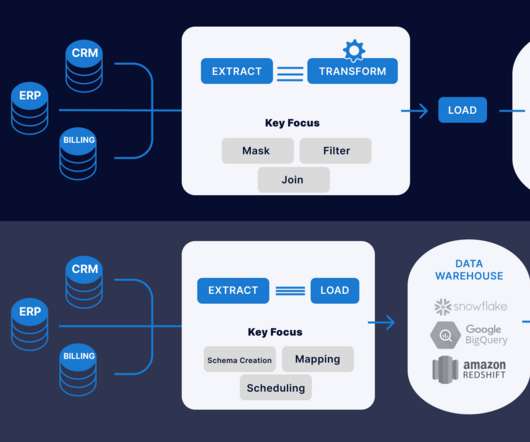
This article was published as a part of the Data Science Blogathon What is ETL? ETL is a process that extracts data from multiple source systems, changes it (through calculations, concatenations, and so on), and then puts it into the DataWarehouse system. ETL stands for Extract, Transform, and Load.
Source: [link] Introduction If you are familiar with databases, or datawarehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well. For the […].
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
Introduction This article will explain the difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) when data transformation occurs. In ETL, data is extracted from multiple locations to meet the requirements of the target data file and then placed into the file.
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in data science and dataengineering. It offers full BI-Stack Automation, from source to datawarehouse through to frontend.
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. The source data is unstructured JSON, while the target is a structured, relational database.
Introduction Data acclimates to countless shapes and sizes to complete its journey from a source to a destination. Be it a streaming job or a batch job, ETL and ELT are irreplaceable. Before designing an ETL job, choosing optimal, performant, and cost-efficient tools […].
Introduction Azure data factory (ADF) is a cloud-based data ingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation.
Die Bedeutung effizienter und zuverlässiger Datenpipelines in den Bereichen Data Science und DataEngineering ist enorm. Es bietet vollständige Automatisierung des BI-Stacks und unterstützt ein breites Spektrum an DataWarehouses, analytischen Datenbanken und Frontends.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines.
In this post, we will be particularly interested in the impact that cloud computing left on the modern datawarehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Understanding the Basics What is a DataWarehouse?
In the world of AI-driven data workflows, Brij Kishore Pandey, a Principal Engineer at ADP and a respected LinkedIn influencer, is at the forefront of integrating multi-agent systems with Generative AI for ETL pipeline orchestration. ETL ProcessBasics So what exactly is ETL? What is an Agent?
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Dataengineering is a rapidly growing field that designs and develops systems that process and manage large amounts of data. There are various architectural design patterns in dataengineering that are used to solve different data-related problems.
Fivetran is used by businesses to centralize data from various sources into a single, comprehensive datawarehouse. It allows organizations to easily connect their disparate data sources without having to manage any infrastructure. This frees up our dataengineers to do what they do best.
Accordingly, one of the most demanding roles is that of Azure DataEngineer Jobs that you might be interested in. The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. How to Become an Azure DataEngineer?
In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. Extract, transform and Load Before we begin, let’s shed some light on what an ETL pipeline essentially is. ELT stands for extract, load and transform.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Introduction Enterprises here and now catalyze vast quantities of data, which can be a high-end source of business intelligence and insight when used appropriately. Delta Lake allows businesses to access and break new data down in real time.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Big Data Architect. Zach Mitchell is a Sr.
Engineering teams, in particular, can quickly get overwhelmed by the abundance of information pertaining to competition data, new product and service releases, market developments, and industry trends, resulting in information anxiety. Explosive data growth can be too much to handle. Can’t get to the data.
Over the past few decades, the corporate data landscape has changed significantly. The shift from on-premise databases and spreadsheets to the modern era of cloud datawarehouses and AI/ LLMs has transformed what businesses can do with data. This is where Fivetran and the Modern Data Stack come in.
Best practices are a pivotal part of any software development, and dataengineering is no exception. This ensures the data pipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently. What Are Matillion Jobs and Why Do They Matter?
Scalable data pipelines: Seasoned data teams are facing increasing pressure to respond to a growing number of data requests from downstream consumers, which is compounded by the drive for users to have higher data literacy and skills shortage of experienced dataengineers.
It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse. Data ingestion/integration services. Reverse ETL tools. Data orchestration tools. A Note on the Shift from ETL to ELT.
A traditional data pipeline is a structured process that begins with gathering data from various sources and loading it into a datawarehouse or data lake. Once ingested, the data is prepared through filtering, error correction, and restructuring for ease of use.
Db2 Warehouse fully supports open formats such as Parquet, Avro, ORC and Iceberg table format to share data and extract new insights across teams without duplication or additional extract, transform, load (ETL). This allows you to scale all analytics and AI workloads across the enterprise with trusted data.
Python is the top programming language used by dataengineers in almost every industry. Python has proven proficient in setting up pipelines, maintaining data flows, and transforming data with its simple syntax and proficiency in automation. Truly a must-have tool in your dataengineering arsenal!
Typically, this data is scattered across Excel files on business users’ desktops. Snowflake can not natively read files on these services, so an ETL service is needed to upload the data. ETL applications are often expensive and require some level of expertise to run.
Using Amazon Redshift ML for anomaly detection Amazon Redshift ML makes it easy to create, train, and apply machine learning models using familiar SQL commands in Amazon Redshift datawarehouses. To capture unanticipated, less obvious data patterns, you can enable anomaly detection. To learn more, see the documentation.
As a result, Matillion is an excellent choice for businesses wishing to optimize their data operations in a scalable and user-friendly environment. Matillion’s Data Productivity Cloud is a pivotal tool for modern data teams, designed to accelerate data delivery and transform the ETL process. No problem.
This process introduces considerable time and effort into the overall data ingestion workflow, delaying the availability of data to end consumers. Fortunately, the client has opted for Snowflake Data Cloud as their target datawarehouse. This is incredibly useful for both DataEngineers and Data Scientists.
A rigid data model such as Kimball or Data Vault would ruin this flexibility and essentially transform your data lake into a datawarehouse. However, some flexible data modeling techniques can be used to allow for some organization while maintaining the ease of new data additions.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for business intelligence and data science use cases.
ODSC Highlights Announcing the Keynote and Featured Speakers for ODSC East 2024 The keynotes and featured speakers for ODSC East 2024 have won numerous awards, authored books and widely cited papers, and shaped the future of data science and AI with their research. Learn more about them here!
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content