This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Overview: Assume the job of a DataEngineer, extracting data from. The post Implementing ETL Process Using Python to Learn DataEngineering appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction At the highest level, ETL converts your data before uploading, while ELT converts data only after uploading to your repository. The post ETL & ELT – DataEngineering Essentials appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon A data scientist’s ability to extract value from data is closely related to how well-developed a company’s data storage and processing infrastructure is.
Learn the dataengineering tools for data orchestration, database management, batch processing, ETL (Extract, Transform, Load), data transformation, data visualization, and data streaming.
This article was published as a part of the Data Science Blogathon. Overview ETL (Extract, Transform, and Load) is a very common technique in dataengineering. Traditionally, ETL processes are […]. The post Crafting Serverless ETL Pipeline Using AWS Glue and PySpark appeared first on Analytics Vidhya.
Introduction Processing large amounts of raw data from various sources requires appropriate tools and solutions for effective data integration. Building an ETL pipeline using Apache […]. The post ETL Pipeline with Google DataFlow and Apache Beam appeared first on Analytics Vidhya.
Introduction In this article, we attempt to capture the complexity of ETL and workflow orchestration tools, which aid in better data management and control by providing multiple alternatives for performing various operations in discrete blocks while maintaining visibility and clear goals for each action. We’ll continue […].
And so, there is no doubt that DataEngineers use it extensively to build and manage their ETL pipelines. The post DataEngineering 101– BranchPythonOperator in Apache Airflow appeared first on Analytics Vidhya. Introduction Apache Airflow is the most popular tool for workflow management.
Introduction Organizations with a separate transactional database and data warehouse typically have many dataengineering activities. For example, they extract, transform and load data from various sources into their data warehouse.
This article talks about several best practices for writing ETLs for building training datasets. It delves into several software engineering techniques and patterns applied to ML.
Obtaining, structuring, and analyzing these data into new, relevant information is crucial in today’s world. Since contextual data exposes popular patterns and trends, we have arrived at the stage where businesses take data-driven decisions to […]. The post ETL vs ELT in 2022: Do they matter?
In this article, we will discuss use cases and methods for using ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) processes along with SQL to integrate data from various sources.
This blog provided you with a comprehensive overview of ETL and JupySQL, including a brief introduction to ETLs and JupySQL. We also demonstrated how to schedule an example ETL notebook via GitHub actions, which allows you to automate the process of executing ETLs and JupySQL from Jupyter.
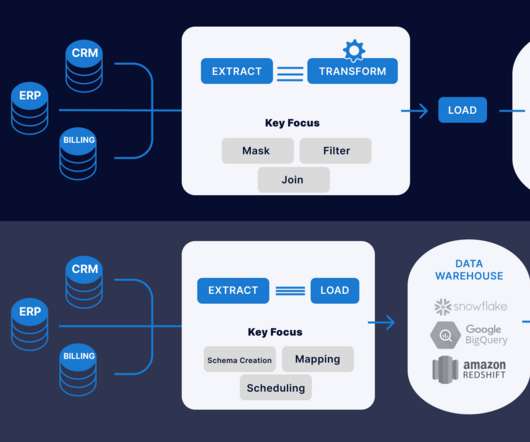
Introduction This article will explain the difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) when data transformation occurs. In ETL, data is extracted from multiple locations to meet the requirements of the target data file and then placed into the file.
This article was published as a part of the Data Science Blogathon What is ETL? ETL is a process that extracts data from multiple source systems, changes it (through calculations, concatenations, and so on), and then puts it into the Data Warehouse system. ETL stands for Extract, Transform, and Load.
The acronym ETL—Extract, Transform, Load—has long been the linchpin of modern data management, orchestrating the movement and manipulation of data across systems and databases. This methodology has been pivotal in data warehousing, setting the stage for analysis and informed decision-making.
Source: [link] Introduction If you are familiar with databases, or data warehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well. For the […].
This article was published as a part of the Data Science Blogathon. Introduction AWS Glue helps DataEngineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. It provides organizations with […].
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. The source data is unstructured JSON, while the target is a structured, relational database.
Introduction Data acclimates to countless shapes and sizes to complete its journey from a source to a destination. Be it a streaming job or a batch job, ETL and ELT are irreplaceable. Before designing an ETL job, choosing optimal, performant, and cost-efficient tools […].
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in data science and dataengineering. It supports a holistic data model, allowing for rapid prototyping of various models.
This article was published as a part of the Data Science Blogathon. Introduction Data scientists, engineers, and BI analysts often need to analyze, process, or query different data sources. The post Understand Apache Drill and its Working appeared first on Analytics Vidhya.
Learn the basics of dataengineering to improve your ML modelsPhoto by Mike Benna on Unsplash It is not news that developing Machine Learning algorithms requires data, often a lot of data. Collecting this data is not trivial, in fact, it is one of the most relevant and difficult parts of the entire workflow.
Introduction Azure data factory (ADF) is a cloud-based data ingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation.
Navigating the World of DataEngineering: A Beginner’s Guide. A GLIMPSE OF DATAENGINEERING ❤ IMAGE SOURCE: BY AUTHOR Data or data? No matter how you read or pronounce it, data always tells you a story directly or indirectly. Dataengineering can be interpreted as learning the moral of the story.
DataEngineerDataengineers are responsible for building, maintaining, and optimizing data infrastructures. They require strong programming skills, expertise in data processing, and knowledge of database management.
Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable. Dataengineers build data pipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these data pipelines in an overall workflow.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
Summary: This guide explores the top list of ETL tools, highlighting their features and use cases. It provides insights into considerations for choosing the right tool, ensuring businesses can optimize their data integration processes for better analytics and decision-making. What is ETL? What are ETL Tools?
Key Skills Proficiency in SQL is essential, along with experience in data visualization tools such as Tableau or Power BI. Strong analytical skills and the ability to work with large datasets are critical, as is familiarity with data modeling and ETL processes. This role builds a foundation for specialization.
So why using IaC for Cloud Data Infrastructures? For Data Warehouse Systems that often require powerful (and expensive) computing resources, this level of control can translate into significant cost savings. This brings reliability to dataETL (Extract, Transform, Load) processes, query performances, and other critical data operations.
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines.
He highlights innovations in data, infrastructure, and artificial intelligence and machine learning that are helping AWS customers achieve their goals faster, mine untapped potential, and create a better future. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
In the world of AI-driven data workflows, Brij Kishore Pandey, a Principal Engineer at ADP and a respected LinkedIn influencer, is at the forefront of integrating multi-agent systems with Generative AI for ETL pipeline orchestration. ETL ProcessBasics So what exactly is ETL? What is an Agent?
It is designed to assist dataengineers in transforming, converting, and validating data in a simplified manner while ensuring accuracy and reliability. The Meltano CLI can efficiently handle complex dataengineering tasks, providing a user-friendly interface that simplifies the ELT process.
Accordingly, one of the most demanding roles is that of Azure DataEngineer Jobs that you might be interested in. The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. How to Become an Azure DataEngineer?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content