This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in data science and dataengineering. It offers full BI-Stack Automation, from source to datawarehouse through to frontend.
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines Data Lake und eines DataWarehouse kombiniert. Organisationen können je nach ihren spezifischen Bedürfnissen und Anforderungen zwischen einem DataWarehouse und einem Data Lakehouse wählen.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
generally available on May 24, Alation introduces the Open Data Quality Initiative for the modern data stack, giving customers the freedom to choose the data quality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and DataGovernance application.
Die Bedeutung effizienter und zuverlässiger Datenpipelines in den Bereichen Data Science und DataEngineering ist enorm. Es bietet vollständige Automatisierung des BI-Stacks und unterstützt ein breites Spektrum an DataWarehouses, analytischen Datenbanken und Frontends.
These data requirements could be satisfied with a strong datagovernance strategy. Governance can — and should — be the responsibility of every data user, though how that’s achieved will depend on the role within the organization. How can dataengineers address these challenges directly?
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Unabhängiges und Nachhaltiges DataEngineering Die Arbeit hinter Process Mining kann man sich wie einen Eisberg vorstellen. Diese AI ist in noch keiner Process Mining Software zu finden, kann jedoch bausteinartig dem Process Mining DataWarehouse vorgeschaltet werden.
In the previous blog , we discussed how Alation provides a platform for data scientists and analysts to complete projects and analysis at speed. In this blog we will discuss how Alation helps minimize risk with active datagovernance. So why are organizations not able to scale governance? Meet Governance Requirements.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
We also made the case that query and reporting, provided by big dataengines such as Presto, need to work with the Spark infrastructure framework to support advanced analytics and complex enterprise data decision-making. To do so, Presto and Spark need to readily work with existing and modern datawarehouse infrastructures.
Prinzipielle Architektur-Darstellung eines Data Lakehouse Systems unter Einsatz von Databricks auf der Goolge / Amazon / Microsoft Azure Cloud nach dem Data Mesh Konzept zur Bereitstellung von Data Products für Process Mining, BI und Data Science Applikationen. Müssen Rohdatentabellen in die Analyse-Tools wie z.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Engineering teams, in particular, can quickly get overwhelmed by the abundance of information pertaining to competition data, new product and service releases, market developments, and industry trends, resulting in information anxiety. Explosive data growth can be too much to handle. Can’t get to the data.
Datagovernance is traditionally applied to structured data assets that are most often found in databases and information systems. The ability to connect straight to the source allows knowledge workers to work natively in spreadsheets, pulling data directly from true data sources like the datawarehouse or data lake.
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into datawarehouses or databases for analysis. Loading The transformed data is loaded into the target destination, such as a datawarehouse.
“I think one of the most important things I see people do right, is to make sure that you build the data foundation from the ground up correctly,” said Ali Ghodsi, CEO of Databricks. The data lakehouse is one such architecture—with “lake” from data lake and “house” from datawarehouse.
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse.
Cost reduction by minimizing data redundancy, improving data storage efficiency, and reducing the risk of errors and data-related issues. DataGovernance and Security By defining data models, organizations can establish policies, access controls, and security measures to protect sensitive data.
Data classification, standardization, normalization, verification, validation, and deduplication are all examples of data processing tasks. Data Storage The data storage component of a pipeline provides secure, scalable storage for the data. You also want to make sure that there aren’t any issues with the data.
“I think one of the most important things I see people do right, is to make sure that you build the data foundation from the ground up correctly,” said Ali Ghodsi, CEO of Databricks. The data lakehouse is one such architecture—with “lake” from data lake and “house” from datawarehouse.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
we are introducing Alation Anywhere, extending data intelligence directly to the tools in your modern data stack, starting with Tableau. We continue to make deep investments in governance, including new capabilities in the Stewardship Workbench, a core part of the DataGovernance App. Datagovernance at scale.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for business intelligence and data science use cases. Perform data quality monitoring based on pre-configured rules.
The datawarehouse and analytical data stores moved to the cloud and disaggregated into the data mesh. Today, the brightest minds in our industry are targeting the massive proliferation of data volumes and the accompanying but hard-to-find value locked within all that data. Architectures became fabrics.
Typically, this data is scattered across Excel files on business users’ desktops. They usually operate outside any datagovernance structure; often, no documentation exists outside the user’s mind. This allows for easy sharing and collaboration on the data. Plus, it is a familiar interface for business users.
It uses metadata and data management tools to organize all data assets within your organization. It synthesizes the information across your data ecosystem—from data lakes, datawarehouses, and other data repositories—to empower authorized users to search for and access business-ready data for their projects and initiatives.
They will focus on organizing data for quicker queries, optimizing virtual datawarehouses, and refining query processes. The result is a datawarehouse offering faster query responses, improved performance, and cost efficiency throughout your Snowflake account.
Through Impact Analysis, users can determine if a problem occurred with data upstream, and locate the impacted data downstream. With robust data lineage, dataengineers can find and fix issues fast and prevent them from recurring. Similarly, analysts gain a clear view of how data is created. In 2022.1,
One of the most common formats for storing large amounts of data is Apache Parquet due to its compact and highly efficient format. This means that business analysts who want to extract insights from the large volumes of data in their datawarehouse must frequently use data stored in Parquet.
For years, marketing teams across industries have turned to implementing traditional Customer Data Platforms (CDPs) as separate systems purpose-built to unlock growth with first-party data.
We already know that a data quality framework is basically a set of processes for validating, cleaning, transforming, and monitoring data. DataGovernanceDatagovernance is the foundation of any data quality framework. It primarily caters to large organizations with complex data environments.
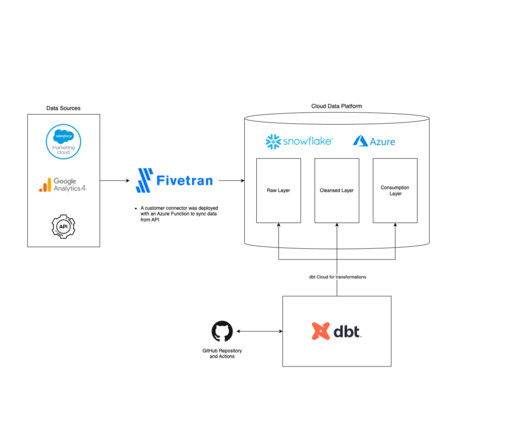
Understanding Fivetran Fivetran is a user-friendly, code-free platform enabling customers to easily synchronize their data by automating extraction, transformation, and loading from many sources. Fivetran automates the time-consuming steps of the ELT process so your dataengineers can focus on more impactful projects.
Data mesh forgoes technology edicts and instead argues for “decentralized data ownership” and the need to treat “data as a product”. Gartner on Data Fabric. Moreover, data catalogs play a central role in both data fabric and data mesh. Let’s turn our attention now to data mesh.
Data classification, standardization, normalization, verification, validation, and deduplication are all examples of data processing tasks. Data Storage The data storage component of a pipeline provides secure, scalable storage for the data. You also want to make sure that there aren’t any issues with the data.
A data mesh is a conceptual architectural approach for managing data in large organizations. Traditional data management approaches often involve centralizing data in a datawarehouse or data lake, leading to challenges like data silos, data ownership issues, and data access and processing bottlenecks.
Data Quality Monitoring implements quality checks in operational data processes to ensure that the data meets pre-defined standards and business rules. This results in poor credibility and data consistency after some time, leading businesses to mistrust the data pipelines and processes. Contact phData Today!
After its 2021 acquisition of Heights Finance Corporation, CURO needed to catalog and tag its legacy data while integrating Heights’ data — quickly. Bringing together companies — and their data Alation: For you guys in data, it sounds like the acquisition was the easy part. Who’s using Alation Data Catalog now?
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This data transformation tool enables data analysts and engineers to transform, test and document data in the cloud datawarehouse. But what does this mean from a practitioner perspective? Happy to chat.
While data fabric takes a product-and-tech-centric approach, data mesh takes a completely different perspective. Data mesh inverts the common model of having a centralized team (such as a dataengineering team), who manage and transform data for wider consumption. But why is such an inversion needed?
In data vault implementations, critical components encompass the storage layer, ELT technology, integration platforms, data observability tools, Business Intelligence and Analytics tools, DataGovernance , and Metadata Management solutions. Data Acquisition: Extracting data from source systems and making it accessible.
Here’s how a composable CDP might incorporate the modeling approaches we’ve discussed: Data Storage and Processing : This is your foundation. You might choose a cloud datawarehouse like the Snowflake AI Data Cloud or BigQuery. Building a composable CDP requires some serious dataengineering chops.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content