This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon. Image Source: GitHub Table of Contents What is DataEngineering? The post How to Implement DataEngineering in Practice? Initially, we have the definition of Software […]. Initially, we have the definition of Software […].
This article was published as a part of the DataScience Blogathon. Introduction A datalake is a centralized repository for storing, processing, and securing massive amounts of structured, semi-structured, and unstructured data. DataLakes are an important […].
This article was published as a part of the DataScience Blogathon. Introduction Today, DataLake is most commonly used to describe an ecosystem of IT tools and processes (infrastructure as a service, software as a service, etc.) that work together to make processing and storing large volumes of data easy.
This article was published as a part of the DataScience Blogathon. Introduction Data is defined as information that has been organized in a meaningful way. Data collection is critical for businesses to make informed decisions, understand customers’ […]. The post DataLake or Data Warehouse- Which is Better?
ArticleVideo Book This article was published as a part of the DataScience Blogathon. Introduction DataLake architecture for different use cases – Elegant. The post A Guide to Build your DataLake in AWS appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction A datalake is a central data repository that allows us to store all of our structured and unstructured data on a large scale. The post A Detailed Introduction on DataLakes and Delta Lakes appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. The post How a Delta Lake is Process with Azure Synapse Analytics appeared first on Analytics Vidhya.
For example, in the bank marketing use case, the management account would be responsible for setting up the organizational structure for the bank’s data and analytics teams, provisioning separate accounts for data governance, datalakes, and datascience teams, and maintaining compliance with relevant financial regulations.
This article was published as a part of the DataScience Blogathon. Introduction Most of you would know the different approaches for building a data and analytics platform. You would have already worked on systems that used traditional warehouses or Hadoop-based datalakes. Selecting one among […].
This article was published as a part of the DataScience Blogathon. Introduction In the modern data world, Lakehouse has become one of the most discussed topics for building a data platform.
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in datascience and dataengineering. It offers full BI-Stack Automation, from source to data warehouse through to frontend.
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. Overview of One Lake Fabric features a lake-centric architecture, with a central repository known as OneLake. On the home page, select Synapse DataEngineering.
Rockets legacy datascience environment challenges Rockets previous datascience solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided DataScience Experience development tools.
A recent article on Analytics Insight explores the critical aspect of dataengineering for IoT applications. Understanding the intricacies of dataengineering empowers data scientists to design robust IoT solutions, harness data effectively, and drive innovation in the ever-expanding landscape of connected devices.
Here’s what we found for both skills and platforms that are in demand for data scientist jobs. DataScience Skills and Competencies Aside from knowing particular frameworks and languages, there are various topics and competencies that any data scientist should know. Joking aside, this does infer particular skills.
Die Bedeutung effizienter und zuverlässiger Datenpipelines in den Bereichen DataScience und DataEngineering ist enorm. Automatisierung: Erstellt SQL-Code, DACPAC-Dateien, SSIS-Pakete, Data Factory-ARM-Vorlagen und XMLA-Dateien. DataLakes: Unterstützt MS Azure Blob Storage.
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines DataLake und eines Data Warehouse kombiniert. Die Definition eines Data Lakehouse Ein Data Lakehouse ist eine moderne Datenspeicher- und -verarbeitungsarchitektur, die die Vorteile von DataLakes und Data Warehouses vereint.
Though you may encounter the terms “datascience” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, data analytics is the act of examining datasets to extract value and find answers to specific questions.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
Its designed for high-performance data streaming applications, making it an excellent choice for financial modeling, AI-driven analytics, and real-time dashboards. AiriaAI-Powered Insights Airia is leveraging AI to provide open-source tools that help organizations gain deeper insights into their data.
Big Data wurde für viele Unternehmen der traditionellen Industrie zur Enttäuschung, zum falschen Versprechen. Datenqualität hingegen, wurde zum wichtigen Faktor jeder Unternehmensbewertung, was Themen wie Reporting, Data Governance und schließlich dann das DataEngineering mehr noch anschob als die DataScience.
Today we’re excited to announce the launch of Segment DataLakes, a new turnkey customer datalake that provides the dataengineering foundation needed to power datascience and advanced analytics use cases.
Data and governance foundations – This function uses a data mesh architecture for setting up and operating the datalake, central feature store, and data governance foundations to enable fine-grained data access. This framework considers multiple personas and services to govern the ML lifecycle at scale.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
We’ve just wrapped up our first-ever DataEngineering Summit. If you weren’t able to make it, don’t worry, you can watch the sessions on-demand and keep up-to-date on essential dataengineering tools and skills. It also addresses the strategies and best practices for implementing a data mesh.
Dataengineering is a hot topic in the AI industry right now. And as data’s complexity and volume grow, its importance across industries will only become more noticeable. But what exactly do dataengineers do? So let’s do a quick overview of the job of dataengineer, and maybe you might find a new interest.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
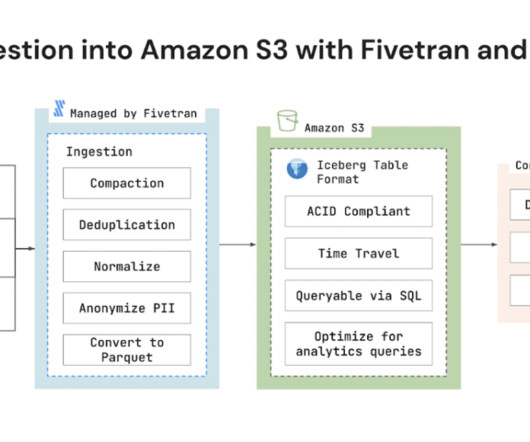
Fivetran today announced support for Amazon Simple Storage Service (Amazon S3) with Apache Iceberg datalake format. Amazon S3 is an object storage service from Amazon Web Services (AWS) that offers industry-leading scalability, data availability, security, and performance.
Managing and retrieving the right information can be complex, especially for data analysts working with large datalakes and complex SQL queries. This post highlights how Twilio enabled natural language-driven data exploration of business intelligence (BI) data with RAG and Amazon Bedrock.
We couldn’t be more excited to announce the first sessions for our second annual DataEngineering Summit , co-located with ODSC East this April. Join us for 2 days of talks and panels from leading experts and dataengineering pioneers. Is Gen AI A DataEngineering or Software Engineering Problem?
Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP. Additionally, Amazon Simple Storage Service (Amazon S3) served as the central datalake, providing a scalable and cost-effective storage solution for the diverse data types collected from different systems.
Aspiring and experienced DataEngineers alike can benefit from a curated list of books covering essential concepts and practical techniques. These 10 Best DataEngineering Books for beginners encompass a range of topics, from foundational principles to advanced data processing methods. What is DataEngineering?
5 DataEngineering and DataScience Cloud Options for 2023 AI development is incredibly resource intensive. As such, here are a few datascience cloud options to help you handle some work virtually. Here are a few things to keep an eye out for. Register by Friday to save 20%.
The Future of the Single Source of Truth is an Open DataLake Organizations that strive for high-performance data systems are increasingly turning towards the ELT (Extract, Load, Transform) model using an open datalake. Instead, use Prefect where interactive workflows are now natively supported.
Übrigens nicht mehr so stark bei den Data Scientists, auch wenn richtig gute Mitarbeiter ebenfalls rar gesät sind, den größten Bedarf haben Unternehmen eher bei den DataEngineers. Das sind die Kollegen, die die Data Warehouses oder DataLakes aufbauen und pflegen. appeared first on DataScience Blog.
DataEngineerDataengineers are responsible for the end-to-end process of collecting, storing, and processing data. They use their knowledge of data warehousing, datalakes, and big data technologies to build and maintain data pipelines. Get your pass today!
MLOps focuses on the intersection of datascience and dataengineering in combination with existing DevOps practices to streamline model delivery across the ML development lifecycle. MLOps requires the integration of software development, operations, dataengineering, and datascience.
Data Mesh More data management systems in 2023 will also shift toward a data mesh architecture. This decentralized architecture breaks datalakes into smaller domains specific to a given team or department. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
A data warehouse is a centralized and structured storage system that enables organizations to efficiently store, manage, and analyze large volumes of data for business intelligence and reporting purposes. What is a DataLake? What is the Difference Between a DataLake and a Data Warehouse?
Many teams are turning to Athena to enable interactive querying and analyze their data in the respective data stores without creating multiple data copies. Athena allows applications to use standard SQL to query massive amounts of data on an S3 datalake. Create a datalake with Lake Formation.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content