This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP. Additionally, Amazon Simple Storage Service (Amazon S3) served as the central datalake, providing a scalable and cost-effective storage solution for the diverse data types collected from different systems.
When it was no longer a hard requirement that a physical data model be created upon the ingestion of data, there was a resulting drop in richness of the description and consistency of the data stored in Hadoop. You did not have to understand or prepare the data to get it into Hadoop, so people rarely did.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. As a DataEngineer he was involved in applying AI/ML to fraud detection and office automation.
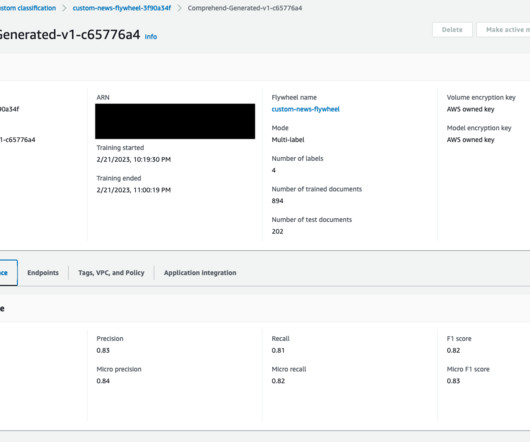
Solution overview Amazon Comprehend is a fully managed service that uses natural language processing (NLP) to extract insights about the content of documents. MLOps focuses on the intersection of data science and dataengineering in combination with existing DevOps practices to streamline model delivery across the ML development lifecycle.
The agent knowledge base stores Amazon Bedrock service documentation, while the cache knowledge base contains curated and verified question-answer pairs. For this example, you will ingest Amazon Bedrock documentation in the form of the User Guide PDF into the Amazon Bedrock knowledge base. This will be the primary dataset.
Our goal was to improve the user experience of an existing application used to explore the counters and insights data. The data is stored in a datalake and retrieved by SQL using Amazon Athena. The question is sent through a retrieval-augmented generation (RAG) process, which finds similar documents.
These teams are as follows: Advanced analytics team (datalake and data mesh) – Dataengineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
To combine the collected data, you can integrate different data producers into a datalake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the datalake.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. Check out the Kubeflow documentation. For example, neptune.ai
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. How to scale AL and ML with built-in governance A fit-for-purpose data store built on an open lakehouse architecture allows you to scale AI and ML while providing built-in governance tools.
In this post, we will explore the potential of using MongoDB’s time series data and SageMaker Canvas as a comprehensive solution. MongoDB Atlas MongoDB Atlas is a fully managed developer data platform that simplifies the deployment and scaling of MongoDB databases in the cloud.
Precisely conducted a study that found that within enterprises, data scientists spend 80% of their time cleaning, integrating and preparing data , dealing with many formats, including documents, images, and videos. Overall placing emphasis on establishing a trusted and integrated data platform for AI.
For example, a new data scientist who is curious about which customers are most likely to be repeat buyers, might search for customer data only to discover an article documenting a previous project that answered their exact question. Modern data catalogs also facilitate data quality checks.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. While they require task-specific labeled data for fine tuning, they also offer clients the best cost performance trade-off for non-generative use cases.
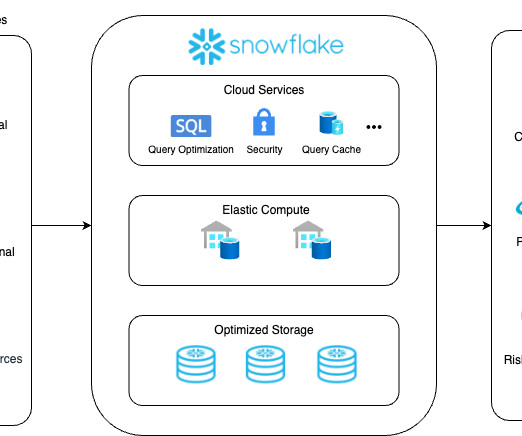
By leveraging cloud-based data platforms such as Snowflake Data Cloud , these commercial banks can aggregate and curate their data to understand individual customer preferences and offer relevant and personalized products.
Through Impact Analysis, users can determine if a problem occurred with data upstream, and locate the impacted data downstream. With robust data lineage, dataengineers can find and fix issues fast and prevent them from recurring. Similarly, analysts gain a clear view of how data is created.
Building an Effective OSS Management Layer for Your DataLake Ahead of her ODSC West session on OSS management layers, the speaker discusses how datalakes can benefit from this system. When your data consists of various patient chart document types (e.g.
This includes operations like data validation, data cleansing, data aggregation, and data normalization. The goal is to ensure that the data is consistent and ready for analysis. Loading : Storing the transformed data in a target system like a data warehouse, datalake, or even a database.
A data mesh is a conceptual architectural approach for managing data in large organizations. Traditional data management approaches often involve centralizing data in a data warehouse or datalake, leading to challenges like data silos, data ownership issues, and data access and processing bottlenecks.
Data scientists Perform data analysis, model development, model evaluation, and registering the models in a model registry. ML engineers Develop model deployment pipelines and control the model deployment processes. The platform engineer shares the two Service Catalog portfolios with workload accounts in the organization.
Cloudera Cloudera is a cloud-based platform that provides businesses with the tools they need to manage and analyze data. They offer a variety of services, including data warehousing, datalakes, and machine learning. ArangoDB ArangoDB is a company that provides a database platform for graph and documentdata.
Data profiling helps organizations understand the data they possess with an eye to its quality level, which is vital for effective data governance. Modern data profiling will also gather all the potential problems in one quick scan. Do you need to define a data quality rule and add that to the profile?
Data governance is traditionally applied to structured data assets that are most often found in databases and information systems. This blog focuses on governing spreadsheets that contain data, information, and metadata, and must themselves be governed. There are others that consider spreadsheets to be trouble.
Below, we explore five popular data transformation tools, providing an overview of their features, use cases, strengths, and limitations. Apache Nifi Apache Nifi is an open-source data integration tool that automates system data flow. Auditing helps track changes and maintain data integrity.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, datalakes , data sharing, and engineering. Simplify and Win Experienced dataengineers value simplicity. What will You Attain with Snowflake?
Without partitioning, daily data activities will cost your company a fortune and a moment will come where the cost advantage of GCP BigQuery becomes questionable. There are other options you can place, and as usual, I suggest you to reference the official documentation to learn more.
Storage Solutions: Secure and scalable storage options like Azure Blob Storage and Azure DataLake Storage. Key features and benefits of Azure for Data Science include: Scalability: Easily scale resources up or down based on demand, ideal for handling large datasets and complex computations.
As Alation worked to create a new category of enterprise data management tool, the data catalog , Aaron wanted to also use this new technology to advance the cause of academic research. Aaron turned his attention from Alation Open to launch the Alation Data Catalog. programs in Information Science and Data Analytics.
Other users Some other users you may encounter include: Dataengineers , if the data platform is not particularly separate from the ML platform. Analytics engineers and data analysts , if you need to integrate third-party business intelligence tools and the data platform, is not separate. Allegro.io
Data Collector also offers replication and Change Data Capture (CDC) to be able to accurately and efficiently get your data into Snowflake. Data Collector can use Snowflake’s native Snowpipe in its pipelines. Why not just use one of the native ingestion methods for Snowflake? The biggest reason is the ease of use.
This means bringing together one or more of: Behavioral data like website visits, purchases, engagement with emails, and ads. Store this data in a customer data platform or datalake. Connect POS systems and CRM databases to your centralized data store.
How do you get executives to understand the value of data governance? First, document your successes of good data, and how it happened. Share stories of data in good times and in bad (pictures help!). We’re planning data governance that’s primarily focused on compliance, data privacy, and protection.
For greater detail, see the Snowflake documentation. If you answer “yes” to any of these questions, you will need cloud storage, such as Amazon AWS’s S3, Azure DataLake Storage or GCP’s Google Storage. That’s why it’s so valuable to have experienced dataengineers on your side, like the ones here at phData.
When I was at Ford, we needed to hook things up to the car and telemetry it out and download all that data somewhere and make a datalake and hire a team of people to sort that data and make it usable; the blocker of doing any ML was changing cars and building datalakes and things like that.
Accelerate your security and AI/ML learning with best practices guidance, training, and certification AWS also curates recommendations from Best Practices for Security, Identity, & Compliance and AWS Security Documentation to help you identify ways to secure your training, development, testing, and operational environments.
Large language models (LLMs) are very large deep-learning models that are pre-trained on vast amounts of data. One model can perform completely different tasks such as answering questions, summarizing documents, translating languages, and completing sentences. Data must be preprocessed to enable semantic search during inference.
Much of these greenhouse gas emissions can be attributed to travel (such as air travel, hotel, meetings), distribution associated for drugs and documents, and electricity used in coordination centers. Decentralized clinical trials, however, often employ a singular datalake for all of an organization’s clinical trials.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content