This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and dataengineering. They transform data into a consistent format for users to consume.
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
Dataengineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and dataengineers are responsible for designing and implementing the systems and infrastructure that make this possible.
Summary: The fundamentals of DataEngineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Welcome to Beyond the Data, a series that investigates the people behind the talent of phData. DataEngineer at phData. DataEngineer? As a Senior DataEngineer, I wear many hats. On the technical side, I clean and organize data, design storage solutions, and build transformation pipelines.
Enrich dataengineering skills by building problem-solving ability with real-world projects, teaming with peers, participating in coding challenges, and more. Globally several organizations are hiring dataengineers to extract, process and analyze information, which is available in the vast volumes of data sets.
Dataengineering is a fascinating and fulfilling career – you are at the helm of every business operation that requires data, and as long as users generate data, businesses will always need dataengineers. The journey to becoming a successful dataengineer […].
This is where Fivetran and the Modern Data Stack come in. Fivetran is a fully-automated, zero-maintenance datapipeline tool that automates the ETL process from data sources to your cloud warehouse. Snowflake Data Cloud Replication Transferring data from a source system to a cloud data warehouse.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. For example, neptune.ai Can you render audio/video?
Elementl / Dagster Labs Elementl and Dagster Labs are both companies that provide platforms for building and managing datapipelines. Elementl’s platform is designed for dataengineers, while Dagster Labs’ platform is designed for data scientists. ArangoDB is designed to be scalable, reliable, and easy to use.
By analyzing datasets, data scientists can better understand their potential use in an algorithm or machine learning model. The data science lifecycle Data science is iterative, meaning data scientists form hypotheses and experiment to see if a desired outcome can be achieved using available data.
Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication. Standard data science practices could also be contributing to this issue. Making dataengineering more systematic through principles and tools will be key to making AI algorithms work.
It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing datapipelines. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. Saurabh Gupta is a Principal Engineer at Zeta Global.
Managing datapipelines efficiently is paramount for any organization. The Snowflake Data Cloud has introduced a groundbreaking feature that promises to simplify and supercharge this process: Snowflake Dynamic Tables. Flexibility: Dynamic tables allow batch and streaming pipelines to be specified in the same way.
DagsHub is a centralized platform to host and manage machine learning projects, including code, data, models, experiments, annotations, model registry, and more! Intermediate DataPipeline : Build datapipelines using DVC for automation and versioning of Open Source Machine Learning projects.
That said, dbt provides the ability to generate data vault models and also allows you to write your data transformations using SQL and code-reusable macros powered by Jinja2 to run your datapipelines in a clean and efficient way. The most important reason for using DBT in Data Vault 2.0
Model Your Data Appropriately Once you have chosen the method to connect to your data (Import, DirectQuery, Composite), you will need to make sure that you create an efficient and optimized datamodel. Here are some of our best practices for building datamodels in Power BI to optimize your Snowflake experience: 1.
Integration: Airflow integrates seamlessly with other dataengineering and Data Science tools like Apache Spark and Pandas. IBM Infosphere DataStage IBM Infosphere DataStage is an enterprise-level ETL tool that enables users to design, develop, and run datapipelines. Read Further: Azure DataEngineer Jobs.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. A data store lets a business connect existing data with new data and discover new insights with real-time analytics and business intelligence.
The first generation of data architectures represented by enterprise data warehouse and business intelligence platforms were characterized by thousands of ETL jobs, tables, and reports that only a small group of specialized dataengineers understood, resulting in an under-realized positive impact on the business.
DataModeling, dbt has gradually emerged as a powerful tool that largely simplifies the process of building and handling datapipelines. dbt is an open-source command-line tool that allows dataengineers to transform, test, and document the data into one single hub which follows the best practices of software engineering.
Tools such as the mentioned are critical for anyone interested in becoming a machine learning engineer. DataEngineerDataengineers are the authors of the infrastructure that stores, processes, and manages the large volumes of data an organization has.
Game changer ChatGPT in Software Engineering: A Glimpse Into the Future | HackerNoon Generative AI for DevOps: A Practical View - DZone ChatGPT for DevOps: Best Practices, Use Cases, and Warnings. GPT-4 DataPipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
Team composition The team comprises domain experts, dataengineers, data scientists, and ML engineers. Team composition The team comprises datapipelineengineers, ML engineers, full-stack engineers, and data scientists.
Dataengineers, data scientists and other data professional leaders have been racing to implement gen AI into their engineering efforts. DataPipeline - Manages and processes various data sources. ML Pipeline - Focuses on training, validation and deployment. LLMOps is MLOps for LLMs.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, data lakes , data sharing, and engineering. Therefore, you’ll be empowered to truncate and reprocess data if bugs are detected and provide an excellent raw data source for data scientists.
By normalising dimension tables, the schema ensures data is stored efficiently, eliminating duplicate entries and minimising the need for repetitive data storage. This normalisation helps conserve storage space and maintain a cleaner datamodel. Explore More: Build DataPipelines: Comprehensive Step-by-Step Guide.
Enter dbt dbt provides SQL-centric transformations for your datamodeling and transformations, which is efficient for scrubbing and transforming your data while being an easy skill set to hire for and develop within your teams. It should also enable easy sharing of insights across the organization.
I suggest building out a RACI framework that assigns core activities across these key roles: (1) Data Owner; (2) Business Data Steward; (3) Technical (IT) Data Steward; (4) Enterprise Data Steward; (5) DataEngineer; and (6) Data Consumer. Communication is essential. This is a very good thing.
The reason is that most teams do not have access to a robust data ecosystem for ML development. billion is lost by Fortune 500 companies because of broken datapipelines and communications. Publishing standards for data and governance of that data is either missing or very widely far from an ideal.
The reason is that most teams do not have access to a robust data ecosystem for ML development. billion is lost by Fortune 500 companies because of broken datapipelines and communications. Publishing standards for data and governance of that data is either missing or very widely far from an ideal.
Introduction: The Customer DataModeling Dilemma You know, that thing we’ve been doing for years, trying to capture the essence of our customers in neat little profile boxes? For years, we’ve been obsessed with creating these grand, top-down customer datamodels. Yeah, that one.
Big dataengineers are essential in today’s data-driven landscape, transforming vast amounts of information into valuable insights. As businesses increasingly depend on big data to tailor their strategies and enhance decision-making, the role of these engineers becomes more crucial.
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable datapipelines. Thats where dataengineering tools come in!
Data Management, Security, and Governance Automating, scaling, versioning and productizing datapipelines Ensuring data security, lineage and risk controls Adding application security Adding real-time guardrails and hallucination protection 2. The future of Gen AI belongs to those who build with foresight.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































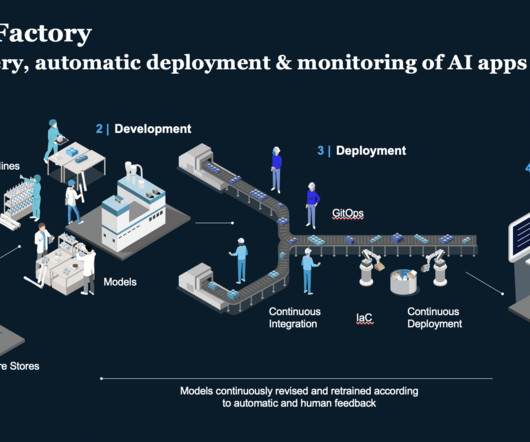






Let's personalize your content