This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in data science and dataengineering. It offers full BI-Stack Automation, from source to datawarehouse through to frontend.
Dataengineering is a crucial field that plays a vital role in the data pipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and dataengineers are responsible for designing and implementing the systems and infrastructure that make this possible.
Summary: The fundamentals of DataEngineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Accordingly, one of the most demanding roles is that of Azure DataEngineer Jobs that you might be interested in. The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. How to Become an Azure DataEngineer?
Dataengineering is a rapidly growing field that designs and develops systems that process and manage large amounts of data. There are various architectural design patterns in dataengineering that are used to solve different data-related problems.
However, to fully harness the potential of a data lake, effective datamodeling methodologies and processes are crucial. Datamodeling plays a pivotal role in defining the structure, relationships, and semantics of data within a data lake. Consistency of data throughout the data lake.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Dataengineering in healthcare is taking a giant leap forward with rapid industrial development. However, data collection and analysis have been commonplace in the healthcare sector for ages. DataEngineering in day-to-day hospital administration can help with better decision-making and patient diagnosis/prognosis.
Over the past few decades, the corporate data landscape has changed significantly. The shift from on-premise databases and spreadsheets to the modern era of cloud datawarehouses and AI/ LLMs has transformed what businesses can do with data. What is the Modern Data Stack? Datamodeling, data cleanup, etc.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. How to scale AL and ML with built-in governance A fit-for-purpose data store built on an open lakehouse architecture allows you to scale AI and ML while providing built-in governance tools.
Data scientists will typically perform data analytics when collecting, cleaning and evaluating data. By analyzing datasets, data scientists can better understand their potential use in an algorithm or machine learning model. Watsonx comprises of three powerful components: the watsonx.ai
With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based datawarehouse.
Must Read Blogs: Exploring the Power of DataWarehouse Functionality. Data Lakes Vs. DataWarehouse: Its significance and relevance in the data world. Exploring Differences: Database vs DataWarehouse. It is commonly used in datawarehouses for business analytics and reporting.
Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. It promotes a disciplined approach to datamodeling, making it easier to ensure data quality and consistency across the ML pipelines. Saurabh Gupta is a Principal Engineer at Zeta Global.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for business intelligence and data science use cases. Perform data quality monitoring based on pre-configured rules.
For years, marketing teams across industries have turned to implementing traditional Customer Data Platforms (CDPs) as separate systems purpose-built to unlock growth with first-party data. dbt has become the standard for modeling.
One of the easiest ways for Snowflake to achieve this is to have analytics solutions query their datawarehouse in real-time (also known as DirectQuery). Creating an efficient datamodel can be the difference between having good or bad performance, especially when using DirectQuery.
DataModeling, dbt has gradually emerged as a powerful tool that largely simplifies the process of building and handling data pipelines. dbt is an open-source command-line tool that allows dataengineers to transform, test, and document the data into one single hub which follows the best practices of software engineering.
Also Read: Top 10 Data Science tools for 2024. It is a process for moving and managing data from various sources to a central datawarehouse. This process ensures that data is accurate, consistent, and usable for analysis and reporting. This process helps organisations manage large volumes of data efficiently.
It uses advanced tools to look at raw data, gather a data set, process it, and develop insights to create meaning. Areas making up the data science field include mining, statistics, data analytics, datamodeling, machine learning modeling and programming.
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This data transformation tool enables data analysts and engineers to transform, test and document data in the cloud datawarehouse. Jason: How do you use these models?
The traditional data science workflow , as defined by Joe Blitzstein and Hanspeter Pfister of Harvard University, contains 5 key steps: Ask a question. Get the data. Explore the data. Model the data. A data catalog can assist directly with every step, but model development.
Traditionally, the tools for batch and streaming pipelines have been distinct, and as such, dataengineers have had to create and manage parallel infrastructures to leverage the benefits of batch data while still delivering low-latency streaming products for real-time use cases.
Data Vault - Data Lifecycle Architecturally, let’s understand the data lifecycle in the data vault into the following layers, which play a key role in choosing the right pattern and tools to implement. Data Acquisition: Extracting data from source systems and making it accessible.
With Snowflake, data stewards have a choice to leverage Snowflake’s governance policies. First, stewards are dependent on datawarehouse admins to provide information and to create and edit enforcement policies in Snowflake. Alation’s data lineage helps organizations to secure their data in the Snowflake Data Cloud.
One scenario could be multiple team members who will each work on ingesting and processing data from one of the source systems. Figure 3: Source Systems made into Modules DataModeling The process to prepare data for consumption by the data visualization layer follows a highly-repeatable pattern.
Introduction: The Customer DataModeling Dilemma You know, that thing we’ve been doing for years, trying to capture the essence of our customers in neat little profile boxes? For years, we’ve been obsessed with creating these grand, top-down customer datamodels. Yeah, that one.
Big dataengineers are essential in today’s data-driven landscape, transforming vast amounts of information into valuable insights. As businesses increasingly depend on big data to tailor their strategies and enhance decision-making, the role of these engineers becomes more crucial.
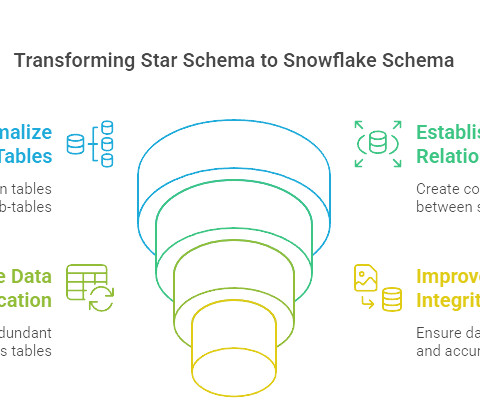
Summary: The snowflake schema in datawarehouse organizes data into normalized, hierarchical dimension tables to reduce redundancy and enhance integrity. Introduction A snowflake schema is a sophisticated datamodeling technique used in data warehousing to efficiently organize and store large volumes of data.
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. Thats where dataengineering tools come in!
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content