This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in data science and dataengineering. It offers full BI-Stack Automation, from source to data warehouse through to frontend.
Top 10 Professions in Data Science: Below, we provide a list of the top data science careers along with their corresponding salary ranges: 1. Data Scientist Data scientists are responsible for designing and implementing datamodels, analyzing and interpreting data, and communicating insights to stakeholders.
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)
Key Skills Proficiency in SQL is essential, along with experience in data visualization tools such as Tableau or Power BI. Strong analytical skills and the ability to work with large datasets are critical, as is familiarity with datamodeling and ETL processes. This role builds a foundation for specialization.
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. Thats where dataengineering tools come in!
So why using IaC for Cloud Data Infrastructures? Streamlined Collaboration Among Teams Data Warehouse Systems in the cloud often involve cross-functional teams — dataengineers, data scientists, and system administrators. The post Why using Infrastructure as Code for developing Cloud-based Data Warehouse Systems?
Summary: The fundamentals of DataEngineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Accordingly, one of the most demanding roles is that of Azure DataEngineer Jobs that you might be interested in. The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. How to Become an Azure DataEngineer?
Dataengineering is a rapidly growing field that designs and develops systems that process and manage large amounts of data. There are various architectural design patterns in dataengineering that are used to solve different data-related problems.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
Enrich dataengineering skills by building problem-solving ability with real-world projects, teaming with peers, participating in coding challenges, and more. Globally several organizations are hiring dataengineers to extract, process and analyze information, which is available in the vast volumes of data sets.
Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. Apache HBase was employed to offer real-time key-based access to data. Data is stored in HDFS and is accessed via Hive, which provides a tabular interface to the data and integrates with Spark SQL.
Getting Started with AI in High-Risk Industries, How to Become a DataEngineer, and Query-Driven DataModeling How To Get Started With Building AI in High-Risk Industries This guide will get you started building AI in your organization with ease, axing unnecessary jargon and fluff, so you can start today.
However, to fully harness the potential of a data lake, effective datamodeling methodologies and processes are crucial. Datamodeling plays a pivotal role in defining the structure, relationships, and semantics of data within a data lake. Consistency of data throughout the data lake.
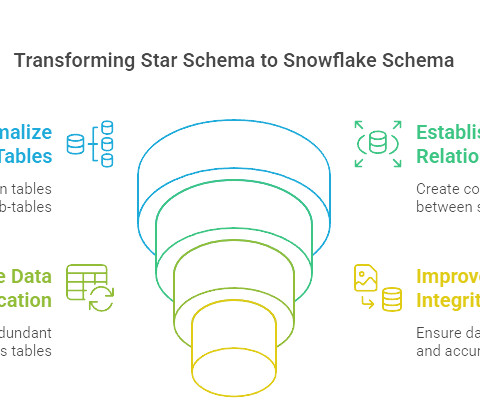
Introduction A snowflake schema is a sophisticated datamodeling technique used in data warehousing to efficiently organize and store large volumes of data. It is an extension of the star schema, designed to optimize storage, enhance data integrity, and support complex analytical queries.
An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
With the “Data Productivity Cloud” launch, Matillion has achieved a balance of simplifying source control, collaboration, and dataops by elevating Git integration to a “first-class citizen” within the framework. In Matillion ETL, the Git integration enables an organization to connect to any Git offering (e.g.,
This is where Fivetran and the Modern Data Stack come in. Fivetran is a fully-automated, zero-maintenance data pipeline tool that automates the ETL process from data sources to your cloud warehouse. Snowflake Data Cloud Replication Transferring data from a source system to a cloud data warehouse.
The first generation of data architectures represented by enterprise data warehouse and business intelligence platforms were characterized by thousands of ETL jobs, tables, and reports that only a small group of specialized dataengineers understood, resulting in an under-realized positive impact on the business.
We document these custom models in Alation Data Catalog and publish common queries that other teams can use for operational use cases or reporting needs. Contact title mappings, which are buiilt in some of datamodels, are documented within our data catalog. Jason: How do you use these models?
By the end of the consulting engagement, the team had implemented the following architecture that effectively addressed the core requirements of the customer team, including: Code Sharing – SageMaker notebooks enable data scientists to experiment and share code with other team members.
Data Vault Automation Working at scale can be challenging, especially when managing the datamodel. Automations provide extra support to small teams by having templates to automate data integration, data vault modeling, and ETL /DDL code generation. This is where automation tools come into play.
Efficient Incremental Processing with Apache Iceberg and Netflix Maestro Dimensional DataModeling in the Modern Era Building Big Data Workflows: NiFi, Hive, Trino, & Zeppelin An Introduction to Data Contracts From Data Mess to Data Mesh — Data Management in the Age of Big Data and Gen AI Introduction to Containers for Data Science / DataEngineering (..)
Slow Response to New Information: Legacy data systems often lack the computation power necessary to run efficiently and can be cost-inefficient to scale. This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data.
General Purpose Tools These tools help manage the unstructured data pipeline to varying degrees, with some encompassing data collection, storage, processing, analysis, and visualization. DagsHub's DataEngine DagsHub's DataEngine is a centralized platform for teams to manage and use their datasets effectively.
Introduction: The Customer DataModeling Dilemma You know, that thing we’ve been doing for years, trying to capture the essence of our customers in neat little profile boxes? For years, we’ve been obsessed with creating these grand, top-down customer datamodels. Yeah, that one.
MongoDB is a NoSQL database that uses a document-oriented datamodel. It stores data in flexible, JSON-like documents, allowing for dynamic schemas. Each document can have a different structure, allowing for flexibility in datamodelling. More to discover: Top 35 Data Analyst Interview Questions and Answers 2023.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content