This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction A datamodel is an abstraction of real-world events that we use to create, capture, and store data in a database that user applications require, omitting unnecessary details.
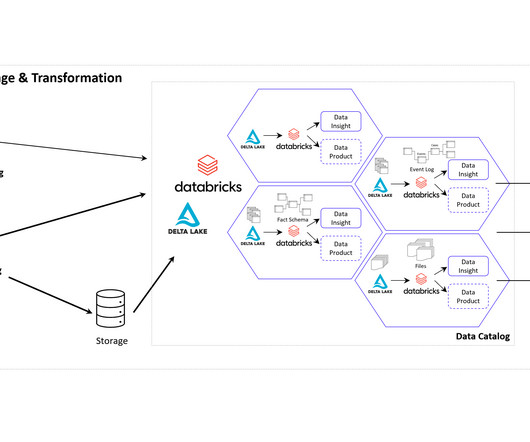
New big data architectures and, above all, data sharing concepts such as Data Mesh are ideal for creating a common database for many data products and applications. The Event Log DataModel for Process Mining Process Mining as an analytical system can very well be imagined as an iceberg.
Key Skills Proficiency in SQL is essential, along with experience in data visualization tools such as Tableau or Power BI. Strong analytical skills and the ability to work with large datasets are critical, as is familiarity with datamodeling and ETL processes. This role builds a foundation for specialization.
Summary: The fundamentals of DataEngineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Dataengineering is a rapidly growing field that designs and develops systems that process and manage large amounts of data. There are various architectural design patterns in dataengineering that are used to solve different data-related problems.
Dataengineering in healthcare is taking a giant leap forward with rapid industrial development. However, data collection and analysis have been commonplace in the healthcare sector for ages. DataEngineering in day-to-day hospital administration can help with better decision-making and patient diagnosis/prognosis.
Getting Started with AI in High-Risk Industries, How to Become a DataEngineer, and Query-Driven DataModeling How To Get Started With Building AI in High-Risk Industries This guide will get you started building AI in your organization with ease, axing unnecessary jargon and fluff, so you can start today.
Introduction: The Customer DataModeling Dilemma You know, that thing we’ve been doing for years, trying to capture the essence of our customers in neat little profile boxes? For years, we’ve been obsessed with creating these grand, top-down customer datamodels. Yeah, that one.
Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. Apache HBase was employed to offer real-time key-based access to data. Data is stored in HDFS and is accessed via Hive, which provides a tabular interface to the data and integrates with Spark SQL.
By the end of the consulting engagement, the team had implemented the following architecture that effectively addressed the core requirements of the customer team, including: Code Sharing – SageMaker notebooks enable data scientists to experiment and share code with other team members.
By acquiring expertise in statistical techniques, machine learning professionals can develop more advanced and sophisticated algorithms, which can lead to better outcomes in data analysis and prediction. These techniques can be utilized to estimate the likelihood of future events and inform the decision-making process.
Data-centric AI, in his opinion, is based on the following principles: It’s time to focus on the data — after all the progress achieved in algorithms means it’s now time to spend more time on the data Inconsistent data labels are common since reasonable, well-trained people can see things differently.
Data scientists will typically perform data analytics when collecting, cleaning and evaluating data. By analyzing datasets, data scientists can better understand their potential use in an algorithm or machine learning model. Diagnostic analytics: Diagnostic analytics helps pinpoint the reason an event occurred.
Event Tracking : Capturing behavioral events such as page views, add-to-cart, signup, purchase, subscription, etc. Identity Resolution : Merging behavioral events and customer identifiers in an identity graph to create a single comprehensive customer profile. dbt has become the standard for modeling.
Collectively, these modules address governance across various dimensions, such as infrastructure, data, model, and cost. Security OU The accounts in this OU are managed by the organization’s cloud admin or security team for monitoring, identifying, protecting, detecting, and responding to security events.
As models become more complex and the needs of the organization evolve and demand greater predictive abilities, you’ll also find that machine learning engineers use specialized tools such as Hadoop and Apache Spark for large-scale data processing and distributed computing. Well then, you’re in luck. So, what are you waiting for?
For example, Tableau dataengineers want a single source of truth to help avoid creating inconsistencies in data sets, while line-of-business users are concerned with how to access the latest data for trusted analysis when they need it most. Datamodeling. Data migration . Data architecture.
For example, Tableau dataengineers want a single source of truth to help avoid creating inconsistencies in data sets, while line-of-business users are concerned with how to access the latest data for trusted analysis when they need it most. Datamodeling. Data migration . Data architecture.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. Curated foundation models, such as those created by IBM or Microsoft, help enterprises scale and accelerate the use and impact of the most advanced AI capabilities using trusted data.
To answer this question, I sat down with members of the Alation Data & Analytics team, Bindu, Adrian, and Idris. Some may be surprised to learn that this team uses dbt to serve up data to those who need it within the company. Contact title mappings, which are buiilt in some of datamodels, are documented within our data catalog.
Who This Book Is For This book is for practitioners in charge of building, managing, maintaining, and operationalizing the ML process end to end: Data science / AI / ML leaders: Heads of Data Science, VPs of Advanced Analytics, AI Lead etc. Readers learn how to: Build and register the model for use in the production application.
Elementl / Dagster Labs Elementl and Dagster Labs are both companies that provide platforms for building and managing data pipelines. Elementl’s platform is designed for dataengineers, while Dagster Labs’ platform is designed for data scientists. Interested in attending an ODSC event?
Dataengineers, data scientists and other data professional leaders have been racing to implement gen AI into their engineering efforts. Data Pipeline - Manages and processes various data sources. Application Pipeline - Manages requests and data/model validations.
Use Multiple DataModels With on-premise data warehouses, storing multiple copies of data can be too expensive. You can use Snowflake cloud computing to store raw data in structured or variant format, using various datamodels to meet the needs. What will You Attain with Snowflake?
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. This provides end-to-end support for dataengineering and MLOps workflows.
General Purpose Tools These tools help manage the unstructured data pipeline to varying degrees, with some encompassing data collection, storage, processing, analysis, and visualization. DagsHub's DataEngine DagsHub's DataEngine is a centralized platform for teams to manage and use their datasets effectively.
Utilize libraries such as Pandas for data manipulation, NumPy for numerical computations, and Scikit-Learn for Machine Learning tasks. Leverage these libraries to preprocess stock market data, engineer relevant features, and train predictive models.
Surrounding it are dimension tables that provide context to the data, such as time, product, or customer details. Components In a Star Schema, the fact table is the core element, containing measurable data, often called facts. This normalisation helps conserve storage space and maintain a cleaner datamodel.
MongoDB is a NoSQL database that uses a document-oriented datamodel. It stores data in flexible, JSON-like documents, allowing for dynamic schemas. Each document can have a different structure, allowing for flexibility in datamodelling. How Does MongoDB Handle Large-Scale Data Migrations? What Is MongoDB?
Data Mesh on Azure Cloud with Databricks and Delta Lake for Applications of Business Intelligence, Data Science and Process Mining. With the concept of Data Mesh you will be able to access all your organizational internal and external data sources once and provides the data as several datamodels for all your analytical applications.
Four reference lines on the x-axis indicate key events in Tableau’s almost two-decade history: The first Tableau Conference in 2008. April 2018), which focused on users who do understand joins and curating federated data sources. Another key data computation moment was Hyper in v10.5 (Jan Release v1.0 IPO in 2013.
Four reference lines on the x-axis indicate key events in Tableau’s almost two-decade history: The first Tableau Conference in 2008. April 2018), which focused on users who do understand joins and curating federated data sources. Another key data computation moment was Hyper in v10.5 (Jan Release v1.0 IPO in 2013.
With the integration of SageMaker and Amazon DataZone, it enables collaboration between ML builders and dataengineers for building ML use cases. ML builders can request access to data published by dataengineers. Also, you can update the model’s deploy status. medium", "ml.m5.large"], medium", "ml.m5.xlarge"],
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content