This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Streamlined Collaboration Among Teams Data Warehouse Systems in the cloud often involve cross-functional teams — dataengineers, data scientists, and system administrators. This ensures that the datamodels and queries developed by data professionals are consistent with the underlying infrastructure.
However, to fully harness the potential of a data lake, effective datamodeling methodologies and processes are crucial. Datamodeling plays a pivotal role in defining the structure, relationships, and semantics of data within a data lake. Consistency of data throughout the data lake.
Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. It promotes a disciplined approach to datamodeling, making it easier to ensure data quality and consistency across the ML pipelines. Saurabh Gupta is a Principal Engineer at Zeta Global.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. It also lets you choose the right engine for the right workload at the right cost, potentially reducing your data warehouse costs by optimizing workloads. Increase trust in AI outcomes.
This allows you to explore features spanning more than 40 Tableau releases, including links to release documentation. . A diamond mark can be selected to list the features in that release, and selecting a colored square in the feature list will open release documentation in your browser. The Salesforce purchase in 2019.
For example, Tableau dataengineers want a single source of truth to help avoid creating inconsistencies in data sets, while line-of-business users are concerned with how to access the latest data for trusted analysis when they need it most. How should this be documented and communicated? Datamodeling.
Leverage dbt’s `test` macros within your models and add constraints to ensure data integrity between data vault entities. Maintain lineage and documentation: Data Vault emphasizes documenting the data lineage and providing clear documentation for each model.
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This data transformation tool enables data analysts and engineers to transform, test and documentdata in the cloud data warehouse. This graph is an example of one analysis, documented in our internal catalog.
For example, Tableau dataengineers want a single source of truth to help avoid creating inconsistencies in data sets, while line-of-business users are concerned with how to access the latest data for trusted analysis when they need it most. How should this be documented and communicated? Datamodeling.
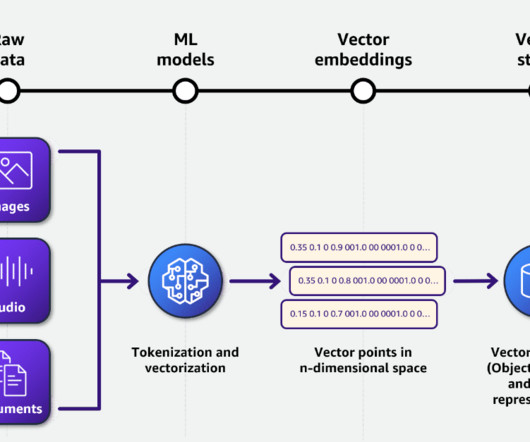
Data Preprocessing Here, you can process the unstructured data into a format that can be used for the other downstream tasks. For instance, if the collected data was a text document in the form of a PDF, the data preprocessing—or preparation stage —can extract tables from this document. Unstructured.io
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. Check out the Kubeflow documentation. For example, neptune.ai
What do machine learning engineers do: They implement and train machine learning modelsDatamodeling One of the primary tasks in machine learning is to analyze unstructured datamodels, which requires a solid foundation in datamodeling. How dataengineers tame Big Data?
The traditional data science workflow , as defined by Joe Blitzstein and Hanspeter Pfister of Harvard University, contains 5 key steps: Ask a question. Get the data. Explore the data. Model the data. A data catalog can assist directly with every step, but model development.
Even with a composite model, the same respective considerations for Import and DirectQuery hold true. For more information on composite models, check out Microsoft’s official documentation. Creating an efficient datamodel can be the difference between having good or bad performance, especially when using DirectQuery.
It leads to gaps in communicating the requirements, which are neither understood well nor documented properly. Team composition The team comprises domain experts, dataengineers, data scientists, and ML engineers. Understanding requirements Quite often, the ML collaborati aspect is often not paid much attention to.
Functional and non-functional requirements need to be documented clearly, which architecture design will be based on and support. Game changer ChatGPT in Software Engineering: A Glimpse Into the Future | HackerNoon Generative AI for DevOps: A Practical View - DZone ChatGPT for DevOps: Best Practices, Use Cases, and Warnings.
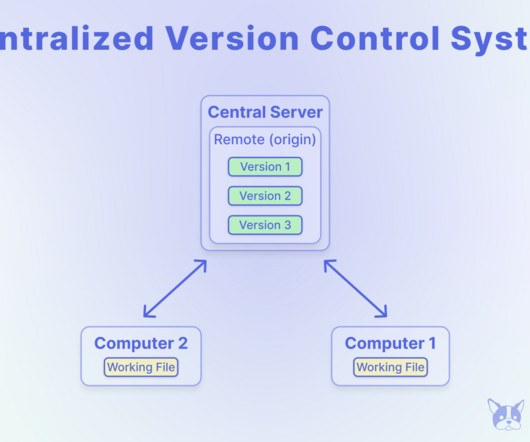
Why Version Control is Essential in ML Version control is an indispensable practice in machine learning (ML) for several crucial reasons: Reproducibility: ML projects are often iterative and involve numerous experiments with different data, models, and hyperparameters.
DataModeling, dbt has gradually emerged as a powerful tool that largely simplifies the process of building and handling data pipelines. dbt is an open-source command-line tool that allows dataengineers to transform, test, and document the data into one single hub which follows the best practices of software engineering.
Business Analyst Though in many respects, quite similar to data analysts, you’ll find that business analysts most often work with a greater focus on industries such as finance, marketing, retail, and consulting. Tools such as the mentioned are critical for anyone interested in becoming a machine learning engineer.
By changing the cost structure of collecting data, it increased the volume of data stored in every organization. Additionally, Hadoop removed the requirement to model or structure data when writing to a physical store. You did not have to understand or prepare the data to get it into Hadoop, so people rarely did.
This allows you to explore features spanning more than 40 Tableau releases, including links to release documentation. . A diamond mark can be selected to list the features in that release, and selecting a colored square in the feature list will open release documentation in your browser. The Salesforce purchase in 2019.
Therefore, you’ll be empowered to truncate and reprocess data if bugs are detected and provide an excellent raw data source for data scientists. Use Multiple DataModels With on-premise data warehouses, storing multiple copies of data can be too expensive. What will You Attain with Snowflake?
Elementl / Dagster Labs Elementl and Dagster Labs are both companies that provide platforms for building and managing data pipelines. Elementl’s platform is designed for dataengineers, while Dagster Labs’ platform is designed for data scientists. However, there are some critical differences between the two companies.
Integration: Airflow integrates seamlessly with other dataengineering and Data Science tools like Apache Spark and Pandas. Open-Source Community: Airflow benefits from an active open-source community and extensive documentation. Read Further: Azure DataEngineer Jobs.
Dataengineers, data scientists and other data professional leaders have been racing to implement gen AI into their engineering efforts. Data Pipeline - Manages and processes various data sources. Application Pipeline - Manages requests and data/model validations. What is MLOps?
Transformation tools of old often lacked easy orchestration, were difficult to test/verify, required specialized knowledge of the tool, and the documentation of your transformations dependent on the willingness of the developer to document. It should also enable easy sharing of insights across the organization.
When a new entrant to ETL development reads this article, they could easily have mastered Matillion Designer’s methods or read through the Matillion Versioning Documentation to develop their own approach to ZDLC. One scenario could be multiple team members who will each work on ingesting and processing data from one of the source systems.
Alation’s data lineage helps organizations to secure their data in the Snowflake Data Cloud. Operationalize data governance at scale. Alation’s Analytics Stewardship enables data stewards to prioritize data based on importance. In Summary.
How do you get executives to understand the value of data governance? First, document your successes of good data, and how it happened. Share stories of data in good times and in bad (pictures help!). We’re planning data governance that’s primarily focused on compliance, data privacy, and protection.
MongoDB is a NoSQL database that handles large-scale data and modern application requirements. Unlike traditional relational databases, MongoDB stores data in flexible, JSON-like documents, allowing for dynamic schemas. In contrast, MongoDB’s document-based model allows for a more flexible and scalable approach.
I switched from analytics to data science, then to machine learning, then to dataengineering, then to MLOps. For me, it was a little bit of a longer journey because I kind of had dataengineering and cloud engineering and DevOps engineering in between. You’re hunting down the data.
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. Thats where dataengineering tools come in!
A dataengineers primary role in ThoughtSpot is to establish data connections for their business and end users to utilize. They are responsible for the design, build, and maintenance of the data infrastructure that powers the analytics platform. Click Upload Uploaded files appear on the Data > Connections page.
You can now register machine learning (ML) models in Amazon SageMaker Model Registry with Amazon SageMaker Model Cards , making it straightforward to manage governance information for specific model versions directly in SageMaker Model Registry in just a few clicks. Also, you can update the model’s deploy status.
With 7 years of experience in developing data solutions, he possesses profound expertise in data visualization, datamodeling, and dataengineering. streamlit run app.py To visit the application using your browser, navigate to the localhost. About the Author Rajendra Choudhary is a Sr.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content