This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As the role of the dataengineer continues to grow in the field of data science, so are the many tools being developed to support wrangling all that data. Five of these tools are reviewed here (along with a few bonus tools) that you should pay attention to for your datapipeline work.
Building datapipelines is a very important skill that you should learn as a dataengineer. A datapipeline is just a series of procedures that transport data from one location to another, frequently changing it along the way.
In a data-driven world, behind-the-scenes heroes like dataengineers play a crucial role in ensuring smooth data flow. A dataengineer investigates the issue, identifies a glitch in the e-commerce platform’s data funnel, and swiftly implements seamless datapipelines.
The post Developing an End-to-End Automated DataPipeline appeared first on Analytics Vidhya. Be it a streaming job or a batch job, ETL and ELT are irreplaceable. Before designing an ETL job, choosing optimal, performant, and cost-efficient tools […].
The needs and requirements of a company determine what happens to data, and those actions can range from extraction or loading tasks […]. The post Getting Started with DataPipeline appeared first on Analytics Vidhya.
Introduction The demand for data to feed machine learning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, datapipelines are necessary. appeared first on Analytics Vidhya.
Real-time dashboards such as GCP provide strong data visualization and actionable information for decision-makers. Nevertheless, setting up a streaming datapipeline to power such dashboards may […] The post DataEngineering for Streaming Data on GCP appeared first on Analytics Vidhya.
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and dataengineering. They transform data into a consistent format for users to consume.
In the data-driven world […] The post Monitoring Data Quality for Your Big DataPipelines Made Easy appeared first on Analytics Vidhya. Determine success by the precision of your charts, the equipment’s dependability, and your crew’s expertise. A single mistake, glitch, or slip-up could endanger the trip.
We are proud to announce two new analyst reports recognizing Databricks in the dataengineering and data streaming space: IDC MarketScape: Worldwide Analytic.
Build a streaming datapipeline using Formula 1 data, Python, Kafka, RisingWave as the streaming database, and visualize all the real-time data in Grafana.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a DataPipeline with PySpark and AWS appeared first on Analytics Vidhya.
Introduction Datapipelines play a critical role in the processing and management of data in modern organizations. A well-designed datapipeline can help organizations extract valuable insights from their data, automate tedious manual processes, and ensure the accuracy of data processing.
.- Dale Carnegie” Apache Kafka is a Software Framework for storing, reading, and analyzing streaming data. The post Build a Simple Realtime DataPipeline appeared first on Analytics Vidhya. The Internet of Things(IoT) devices can generate a large […].
Although data forms the basis for effective and efficient analysis, large-scale data processing requires complete data-driven import and processing techniques […]. The post All About DataPipeline and Its Components appeared first on Analytics Vidhya.
Introduction to Apache Airflow “Apache Airflow is the most widely-adopted, open-source workflow management platform for dataengineeringpipelines. Most organizations today with complex datapipelines to […].
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
This article was published as a part of the Data Science Blogathon. Introduction When creating datapipelines, Software Engineers and DataEngineers frequently work with databases using Database Management Systems like PostgreSQL.
Introduction Imagine yourself as a data professional tasked with creating an efficient datapipeline to streamline processes and generate real-time information. Sounds challenging, right? That’s where Mage AI comes in to ensure that the lenders operating online gain a competitive edge.
Dataengineering startup Prophecy is giving a new turn to datapipeline creation. Known for its low-code SQL tooling, the California-based company today announced data copilot, a generative AI assistant that can create trusted datapipelines from natural language prompts and improve pipeline quality …
Introduction Databricks Lakehouse Monitoring allows you to monitor all your datapipelines – from data to features to ML models – without additional too.
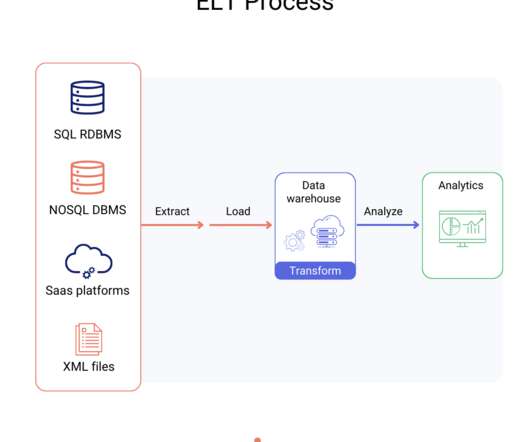
Data Science Dojo is offering Airbyte for FREE on Azure Marketplace packaged with a pre-configured web environment enabling you to quickly start the ELT process rather than spending time setting up the environment. Free to use. Conclusion There are a ton of small services that aren’t supported on traditional datapipeline platforms.
Dataengineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and dataengineers are responsible for designing and implementing the systems and infrastructure that make this possible.
Introduction Apache Airflow is a crucial component in data orchestration and is known for its capability to handle intricate workflows and automate datapipelines. Many organizations have chosen it due to its flexibility and strong scheduling capabilities.
Navigating the World of DataEngineering: A Beginner’s Guide. A GLIMPSE OF DATAENGINEERING ❤ IMAGE SOURCE: BY AUTHOR Data or data? No matter how you read or pronounce it, data always tells you a story directly or indirectly. Dataengineering can be interpreted as learning the moral of the story.
Image by author Automated harmonization, labeling, and data generation By establishing datapipelines, organizations can utilize GenAI as new data enters their systems. For instance, when new datasets come in, the API can automatically apply data harmonization algorithms or identify patterns to infer labels.
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
Dataengineers build datapipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these datapipelines in an overall workflow. Organizations can harness the full potential of their data while reducing risk and lowering costs.
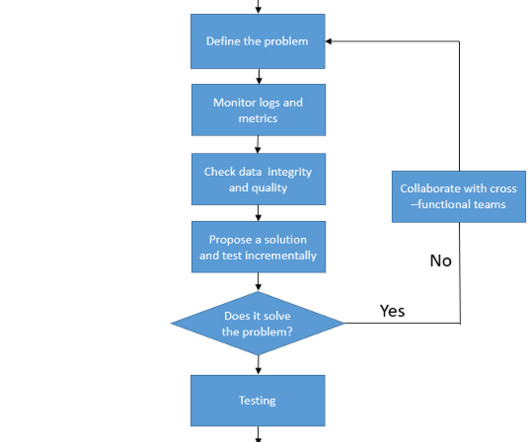
Big datapipelines are the backbone of modern data processing, enabling organizations to collect, process, and analyze vast amounts of data in real-time. Issues such as data inconsistencies, performance bottlenecks, and failures are inevitable.In Validate data format and schema compatibility.
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Where exactly within an organization does the primary responsibility lie for ensuring that a datapipeline project generates data of high quality, and who exactly holds that responsibility? Who is accountable for ensuring that the data is accurate? Is it the dataengineers? The data scientists?
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the datapipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a data warehouse.
This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines. What is an ETL datapipeline in ML?
Dataengineering is a hot topic in the AI industry right now. And as data’s complexity and volume grow, its importance across industries will only become more noticeable. But what exactly do dataengineers do? So let’s do a quick overview of the job of dataengineer, and maybe you might find a new interest.
Aspiring and experienced DataEngineers alike can benefit from a curated list of books covering essential concepts and practical techniques. These 10 Best DataEngineering Books for beginners encompass a range of topics, from foundational principles to advanced data processing methods. What is DataEngineering?
It is designed to assist dataengineers in transforming, converting, and validating data in a simplified manner while ensuring accuracy and reliability. The Meltano CLI can efficiently handle complex dataengineering tasks, providing a user-friendly interface that simplifies the ELT process.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content