This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As the role of the dataengineer continues to grow in the field of datascience, so are the many tools being developed to support wrangling all that data. Five of these tools are reviewed here (along with a few bonus tools) that you should pay attention to for your datapipeline work.
This article was published as a part of the DataScience Blogathon. Introduction Data acclimates to countless shapes and sizes to complete its journey from a source to a destination. The post Developing an End-to-End Automated DataPipeline appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction These days companies seem to seek ways to integrate data from multiple sources to earn a competitive advantage over other businesses. The post Getting Started with DataPipeline appeared first on Analytics Vidhya.
Introduction The demand for data to feed machine learning models, datascience research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, datapipelines are necessary. appeared first on Analytics Vidhya.
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in datascience and dataengineering. They transform data into a consistent format for users to consume.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a DataPipeline with PySpark and AWS appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Dale Carnegie” Apache Kafka is a Software Framework for storing, reading, and analyzing streaming data. The post Build a Simple Realtime DataPipeline appeared first on Analytics Vidhya. Introduction “Learning is an active process.
This article was published as a part of the DataScience Blogathon. Introduction With the development of data-driven applications, the complexity of integrating data from multiple simple decision-making sources is often considered a significant challenge.
This article was published as a part of the DataScience Blogathon. Introduction to Apache Airflow “Apache Airflow is the most widely-adopted, open-source workflow management platform for dataengineeringpipelines. Most organizations today with complex datapipelines to […].
This article was published as a part of the DataScience Blogathon. Introduction When creating datapipelines, Software Engineers and DataEngineers frequently work with databases using Database Management Systems like PostgreSQL.
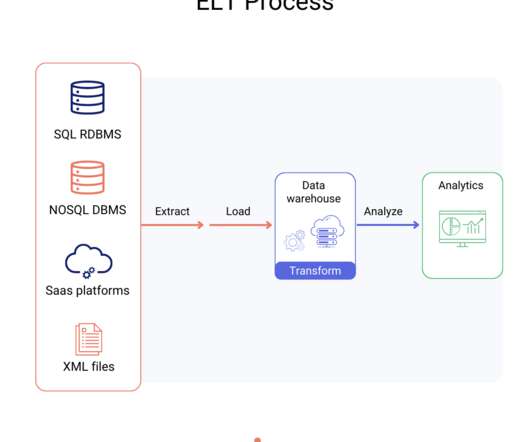
DataScience Dojo is offering Airbyte for FREE on Azure Marketplace packaged with a pre-configured web environment enabling you to quickly start the ELT process rather than spending time setting up the environment. If you can’t import all your data, you may only have a partial picture of your business.
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports.
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
Datascience bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of datascience. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization.
This post is a bitesize walk-through of the 2021 Executive Guide to DataScience and AI — a white paper packed with up-to-date advice for any CIO or CDO looking to deliver real value through data. Automation Automating datapipelines and models ➡️ 6. Team Building the right datascience team is complex.
Introduction Databricks Lakehouse Monitoring allows you to monitor all your datapipelines – from data to features to ML models – without additional too.
Are you interested in a career in datascience? The Bureau of Labor Statistics reports that there are over 105,000 data scientists in the United States. The average data scientist earns over $108,000 a year. Data Scientist. DataEngineer. This is the best time ever to pursue this career track.
Dataengineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and dataengineers are responsible for designing and implementing the systems and infrastructure that make this possible.
Now that we’re in 2024, it’s important to remember that dataengineering is a critical discipline for any organization that wants to make the most of its data. These data professionals are responsible for building and maintaining the infrastructure that allows organizations to collect, store, process, and analyze data.
Last Updated on March 21, 2023 by Editorial Team Author(s): DataScience meets Cyber Security Originally published on Towards AI. Navigating the World of DataEngineering: A Beginner’s Guide. A GLIMPSE OF DATAENGINEERING ❤ IMAGE SOURCE: BY AUTHOR Data or data? What are ETL and datapipelines?
DataScience Dojo is offering Meltano CLI for FREE on Azure Marketplace preconfigured with Meltano, a platform that provides flexibility and scalability. Not to worry as DataScience Dojo’s Meltano CLI instance fixes all of that. Meltano CLI stands out as a dataengineering tool. Already feeling tired?
Here’s what we found for both skills and platforms that are in demand for data scientist jobs. DataScience Skills and Competencies Aside from knowing particular frameworks and languages, there are various topics and competencies that any data scientist should know. Joking aside, this does infer particular skills.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
Though you may encounter the terms “datascience” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, data analytics is the act of examining datasets to extract value and find answers to specific questions.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the datapipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a data warehouse.
The chart below shows 20 in-demand skills that encompass both NLP fundamentals and broader datascience expertise. In a change from last year, there’s also a higher demand for those with data analysis skills as well. Having mastery of these two will prove that you know datascience and in turn, NLP.
Best tools and platforms for MLOPs – DataScience Dojo Google Cloud Platform Google Cloud Platform is a comprehensive offering of cloud computing services. Google Cloud Platform is a great option for businesses that need high-performance computing, such as datascience, AI, machine learning, and financial services.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
Dataengineering is a hot topic in the AI industry right now. And as data’s complexity and volume grow, its importance across industries will only become more noticeable. But what exactly do dataengineers do? So let’s do a quick overview of the job of dataengineer, and maybe you might find a new interest.
The fusion of data in a central platform enables smooth analysis to optimize processes and increase business efficiency in the world of Industry 4.0 using methods from business intelligence , process mining and datascience. Cloud Data Platform for shopfloor management and data sources such like MES, ERP, PLM and machine data.
Machine learning (ML) engineer Potential pay range – US$82,000 to 160,000/yr Machine learning engineers are the bridge between datascience and engineering. Integrating the knowledge of datascience with engineering skills, they can design, build, and deploy machine learning (ML) models.
Aspiring and experienced DataEngineers alike can benefit from a curated list of books covering essential concepts and practical techniques. These 10 Best DataEngineering Books for beginners encompass a range of topics, from foundational principles to advanced data processing methods. What is DataEngineering?
Additionally, imagine being a practitioner, such as a data scientist, dataengineer, or machine learning engineer, who will have the daunting task of learning how to use a multitude of different tools. A feature platform should automatically process the datapipelines to calculate that feature.
We couldn’t be more excited to announce two events that will be co-located with ODSC East in Boston this April: The DataEngineering Summit and the Ai X Innovation Summit. DataEngineering Summit Our second annual DataEngineering Summit will be in-person for the first time! Learn more about them below.
Dataengineering has become an integral part of the modern tech landscape, driving advancements and efficiencies across industries. So let’s explore the world of open-source tools for dataengineers, shedding light on how these resources are shaping the future of data handling, processing, and visualization.
DataEngineerDataengineers are responsible for the end-to-end process of collecting, storing, and processing data. They use their knowledge of data warehousing, data lakes, and big data technologies to build and maintain datapipelines. Get your pass today!
Conventional ML development cycles take weeks to many months and requires sparse datascience understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of dataengineering and datascience team’s bandwidth and data preparation activities.
About the Authors Emrah Kaya is DataEngineering Manager at Omron Europe and Platform Lead for ODAP Project. With his extensive background on Cloud & Data Architecture, Emrah leads key OMRONs technological advancement initiatives, including artificial intelligence, machine learning, or datascience.
We’ve just wrapped up our first-ever DataEngineering Summit. If you weren’t able to make it, don’t worry, you can watch the sessions on-demand and keep up-to-date on essential dataengineering tools and skills. It will cover why data observability matters and the tactics you can use to address it today.
The advent of big data, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in datascience across industries. However, research shows that up to 85% of datascience projects fail to move beyond proofs of concept to full-scale deployment.
We couldn’t be more excited to announce the first sessions for our second annual DataEngineering Summit , co-located with ODSC East this April. Join us for 2 days of talks and panels from leading experts and dataengineering pioneers. Is Gen AI A DataEngineering or Software Engineering Problem?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content