This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Developing NLP tools isn’t so straightforward, and requires a lot of background knowledge in machine & deeplearning, among others. In a change from last year, there’s also a higher demand for those with data analysis skills as well. Having mastery of these two will prove that you know data science and in turn, NLP.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
DataEngineer. In this role, you would perform batch processing or real-time processing on data that has been collected and stored. As a dataengineer, you could also build and maintain datapipelines that create an interconnected data ecosystem that makes information available to data scientists.
Machine learning The 6 key trends you need to know in 2021 ? Automation Automating datapipelines and models ➡️ 6. Team Building the right data science team is complex. With a range of role types available, how do you find the perfect balance of Data Scientists , DataEngineers and Data Analysts to include in your team?
Introduction Are you curious about the latest advancements in the data tech industry? Perhaps you’re hoping to advance your career or transition into this field. In that case, we invite you to check out DataHour, a series of webinars led by experts in the field.
As you’ll see in the next section, data scientists will be expected to know at least one programming language, with Python, R, and SQL being the leaders. This will lead to algorithm development for any machine or deeplearning processes. Java’s still being used frequently as many frameworks run on JVM (Java Virtual Machine).
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. For example, neptune.ai
If the data sources are additionally expanded to include the machines of production and logistics, much more in-depth analyses for error detection and prevention as well as for optimizing the factory in its dynamic environment become possible.
The DJL is a deeplearning framework built from the ground up to support users of Java and JVM languages like Scala, Kotlin, and Clojure. With the DJL, integrating this deeplearning is simple. The architecture of DJL is engine agnostic. Business requirements We are the US squad of the Sportradar AI department.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deeplearning. Tools and frameworks like Scikit-Learn, TensorFlow, and Keras are often covered. Ensure that the bootcamp of your choice covers these specific topics.
AI Engineering TrackBuild Scalable AISystems Learn how to bridge the gap between AI development and software engineering. This track will focus on AI workflow orchestration, efficient datapipelines, and deploying robust AI solutions. Join Us at ODSC 2025Secure Your Spot in the AI Revolution.
Data scientists and ML engineers require capable tooling and sufficient compute for their work. Therefore, BMW established a centralized ML/deeplearning infrastructure on premises several years ago and continuously upgraded it. He has a record of working with distributed teams across the globe within large enterprises.
Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication. Standard data science practices could also be contributing to this issue. Feature engineering activities frequently focus on single-table data transformations, leading to the infamous “yawn factor.”
Find out how to weave data reliability and quality checks into the execution of your datapipelines and more. New Tool Thunder Hopes to Accelerate AI Development Thunder is a new compiler designed to turbocharge the training process for deeplearning models within the PyTorch ecosystem. Learn more about them here!
Machine Learning As machine learning is one of the most notable disciplines under data science, most employers are looking to build a team to work on ML fundamentals like algorithms, automation, and so on. DeepLearningDeeplearning is a cornerstone of modern AI, and its applications are expanding rapidly.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
Because ML is becoming more integrated into daily business operations, data science teams are looking for faster, more efficient ways to manage ML initiatives, increase model accuracy and gain deeper insights. MLOps is the next evolution of data analysis and deeplearning. How MLOps will be used within the organization.
Before diving into the world of data science, it is essential to familiarize yourself with certain key aspects. The process or lifecycle of machine learning and deeplearning tends to follow a similar pattern in most companies. In the data science industry, effective communication and collaboration play a crucial role.
He has worked with multiple federal agencies to advance their data and AI goals. Nitin’s other focus areas include natural language processing (NLP), datapipelines, and generative AI. He applies his knowledge of cutting-edge research methods to the federal sector to deliver innovative technical papers, POCs, and MVPs.
Data Preparation: Cleaning, transforming, and preparing data for analysis and modelling. Collaborating with Teams: Working with dataengineers, analysts, and stakeholders to ensure data solutions meet business needs. Azure’s GPU and TPU instances further accelerate the training of deeplearning models.
Datafold is a tool focused on data observability and quality. It is particularly popular among dataengineers as it integrates well with modern datapipelines (e.g., Source: [link] Monte Carlo is a code-free data observability platform that focuses on data reliability across datapipelines.
The most critical and impactful step you can take towards enterprise AI today is ensuring you have a solid data foundation built on the modern data stack with mature operational pipelines, including all your most critical operational data. AI models can range from simple linear regressions to complex deep neural networks.
Dataengineers, data scientists and other data professional leaders have been racing to implement gen AI into their engineering efforts. LLM models are large deeplearning models that are trained on vast datasets, are adaptable to various tasks and specialize in NLP tasks. LLMOps is MLOps for LLMs.
Machine learning, particularly its subsets, deeplearning, and generative ML, is currently in the spotlight. Seamless integration into the workflow: Kolena can be integrated into existing datapipelines and CI systems using the kolena-client Python client, ensuring that data and models remain under user control at all times.
Machine learning, particularly its subsets, deeplearning, and generative ML, is currently in the spotlight. Seamless integration into the workflow: Kolena can be integrated into existing datapipelines and CI systems using the kolena-client Python client, ensuring that data and models remain under user control at all times.
This section delves into the common stages in most ML pipelines, regardless of industry or business function. 1 Data Ingestion (e.g., Apache Kafka, Amazon Kinesis) 2 Data Preprocessing (e.g., pandas, NumPy) 3 Feature Engineering and Selection (e.g., Scikit-learn, Feature Tools) 4 Model Training (e.g.,
Zeta’s AI innovations over the past few years span 30 pending and issued patents, primarily related to the application of deeplearning and generative AI to marketing technology. It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing datapipelines.
It also can minimize the risks of miscommunication in the process since the analyst and customer can align on the prototype before proceeding to the build phase Design: DALL-E, another deeplearning model developed by OpenAI to generate digital images from natural language descriptions, can contribute to the design of applications.
Other users Some other users you may encounter include: Dataengineers , if the data platform is not particularly separate from the ML platform. Analytics engineers and data analysts , if you need to integrate third-party business intelligence tools and the data platform, is not separate. Allegro.io
Large language models (LLMs) are very large deep-learning models that are pre-trained on vast amounts of data. LLMs have the potential to revolutionize content creation and the way people use search engines and virtual assistants. Data must be preprocessed to enable semantic search during inference.
20212024: Interest declined as deeplearning and pre-trained models took over, automating many tasks previously handled by classical ML techniques. While traditional machine learning remains fundamental, its dominance has waned in the face of deeplearning and automated machine learning (AutoML).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











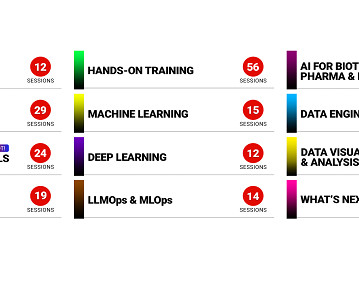






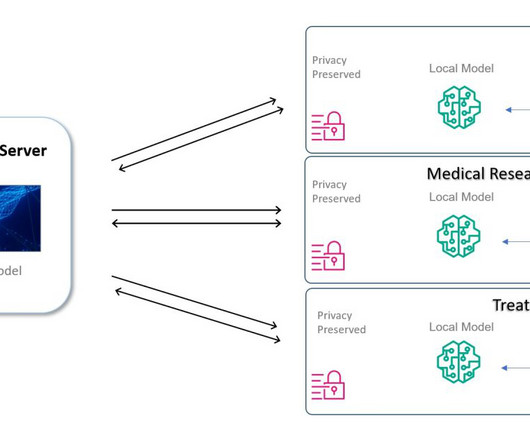


















Let's personalize your content