This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Navigating the World of DataEngineering: A Beginner’s Guide. A GLIMPSE OF DATAENGINEERING ❤ IMAGE SOURCE: BY AUTHOR Data or data? No matter how you read or pronounce it, data always tells you a story directly or indirectly. Dataengineering can be interpreted as learning the moral of the story.
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
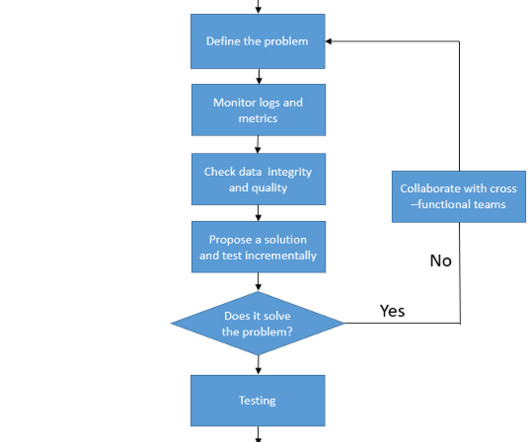
Big datapipelines are the backbone of modern data processing, enabling organizations to collect, process, and analyze vast amounts of data in real-time. Issues such as data inconsistencies, performance bottlenecks, and failures are inevitable.In Validate data format and schema compatibility.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the datapipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a data warehouse.
When needed, the system can access an ODAP data warehouse to retrieve additional information. Document management Documents are securely stored in Amazon S3, and when new documents are added, a Lambda function processes them into chunks. Emel Mendoza is a Senior Solutions Architect at AWS based in the Netherlands.
This article was co-written by Lawrence Liu & Safwan Islam While the title ‘ Machine Learning Engineer ’ may sound more prestigious than ‘DataEngineer’ to some, the reality is that these roles share a significant overlap. Generative AI has unlocked the value of unstructured text-based data.
It seems straightforward at first for batch data, but the engineering gets even more complicated when you need to go from batch data to incorporating real-time and streaming data sources, and from batch inference to real-time serving.
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference datapipeline on large datasets is a challenge many companies face. For example, a company may enrich documents in bulk to translate documents, identify entities and categorize those documents, etc.
But with automated lineage from MANTA, financial organizations have seen as much as a 40% increase in engineering teams’ productivity after adopting lineage. Increased datapipeline observability As discussed above, there are countless threats to your organization’s bottom line.
Key Metrics Annotation Time Reduction : Reduced document annotation time by 75%. Operational Speed : Accelerated data processing pipeline, achieving a 50% increase in data processing speed. Their primary challenges included: Data inconsistencies from non-standardized documentation.
When data leaders move to the cloud, it’s easy to get caught up in the features and capabilities of various cloud services without thinking about the day-to-day workflow of data scientists and dataengineers.
It allows organizations to easily connect their disparate data sources without having to manage any infrastructure. Fivetran’s automated data movement platform simplifies the ETL (extract, transform, load) process by automating most of the time-consuming tasks of ETL that dataengineers would typically do.
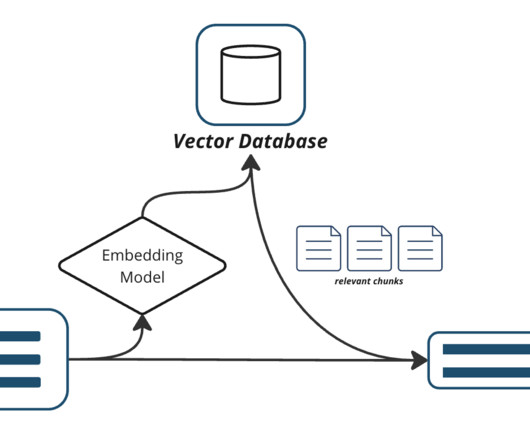
The agent knowledge base stores Amazon Bedrock service documentation, while the cache knowledge base contains curated and verified question-answer pairs. For this example, you will ingest Amazon Bedrock documentation in the form of the User Guide PDF into the Amazon Bedrock knowledge base. This will be the primary dataset.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. Check out the Kubeflow documentation. For example, neptune.ai
It is the practice of monitoring, tracking, and ensuring data quality, reliability, and performance as it moves through an organization’s datapipelines and systems. Data quality tools help maintain high data quality standards. Tools Used in Data Observability?
This is where our Data Generation Tool shines. What is the Data Generation Tool? The Data Generation Tool creates ultra-realistic-looking synthetic relational data for analytics, dataengineering, and AI use cases. Test datapipelines without needing access to sensitive data.
Data scientists and dataengineers want full control over every aspect of their machine learning solutions and want coding interfaces so that they can use their favorite libraries and languages. At the same time, business and data analysts want to access intuitive, point-and-click tools that use automated best practices.
This section outlines key practices focused on automation, monitoring and optimisation, scalability, documentation, and governance. Automation Automation plays a pivotal role in streamlining ETL processes, reducing the need for manual intervention, and ensuring consistent data availability.
This May, were heading to Boston for ODSC East 2025, where data scientists, AI engineers, and industry leaders will gather to explore the latest advancements in AI, machine learning, and dataengineering. This is your chance to gain insights from some of the brightest minds in the industry.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date. Storage tools help with this.
Elementl / Dagster Labs Elementl and Dagster Labs are both companies that provide platforms for building and managing datapipelines. Elementl’s platform is designed for dataengineers, while Dagster Labs’ platform is designed for data scientists. ArangoDB is designed to be scalable, reliable, and easy to use.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. A data store lets a business connect existing data with new data and discover new insights with real-time analytics and business intelligence. Increase trust in AI outcomes.
Precisely conducted a study that found that within enterprises, data scientists spend 80% of their time cleaning, integrating and preparing data , dealing with many formats, including documents, images, and videos. Overall placing emphasis on establishing a trusted and integrated data platform for AI.
Cortex Search : This feature provides a search solution that Snowflake fully manages from data ingestion, embedding, retrieval, reranking, and generation. Use cases for this feature include needle-in-a-haystack lookups and multi-document synthesis and reasoning. schemas["my_schema"].tables.create(my_table) schemas["my_schema"].tables.create(my_table)
It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing datapipelines. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. Saurabh Gupta is a Principal Engineer at Zeta Global.
That said, dbt provides the ability to generate data vault models and also allows you to write your data transformations using SQL and code-reusable macros powered by Jinja2 to run your datapipelines in a clean and efficient way. The most important reason for using DBT in Data Vault 2.0
As a Data Analyst, you’ve honed your skills in data wrangling, analysis, and communication. But the allure of tackling large-scale projects, building robust models for complex problems, and orchestrating datapipelines might be pushing you to transition into Data Science architecture.
Snowflake AI Data Cloud is one of the most powerful platforms, including storage services supporting complex data. Integrating Snowflake with dbt adds another layer of automation and control to the datapipeline. Snowflake stored procedures and dbt Hooks are essential to modern dataengineering and analytics workflows.
Amazon DocumentDB is a fully managed native JSON document database that makes it straightforward and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. You encounter bottlenecks because you need to rely on dataengineering and data science teams to accomplish these goals.
In July 2023, Matillion launched their fully SaaS platform called Data Productivity Cloud, aiming to create a future-ready, everyone-ready, and AI-ready environment that companies can easily adopt and start automating their datapipelines coding, low-coding, or even no-coding at all.
Assembling the Cross-Functional Team Data science combines specialized technical skills in statistics, coding, and algorithms with softer skills in interpreting noisy data and collaborating across functions. Usability Do interfaces and documentation enable business analysts and data scientists to leverage systems?
Integration: Airflow integrates seamlessly with other dataengineering and Data Science tools like Apache Spark and Pandas. Open-Source Community: Airflow benefits from an active open-source community and extensive documentation. Read Further: Azure DataEngineer Jobs.
For enterprises, the value-add of applications built on top of large language models is realized when domain knowledge from internal databases and documents is incorporated to enhance a model’s ability to answer questions, generate content, and any other intended use cases.
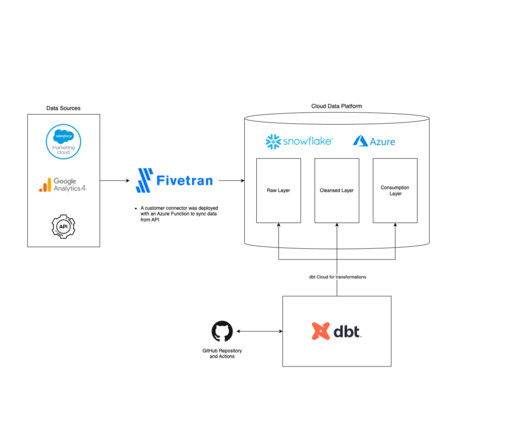
Understanding Fivetran Fivetran is a user-friendly, code-free platform enabling customers to easily synchronize their data by automating extraction, transformation, and loading from many sources. Fivetran automates the time-consuming steps of the ELT process so your dataengineers can focus on more impactful projects.
It leads to gaps in communicating the requirements, which are neither understood well nor documented properly. Team composition The team comprises domain experts, dataengineers, data scientists, and ML engineers. Understanding requirements Quite often, the ML collaborati aspect is often not paid much attention to.
After reading a few blog posts and DJL’s official documentation, we were sure DJL would provide the best solution to our problem. Follow our GitHub repo , demo repository , Slack channel , and Twitter for more documentation and examples of the DJL! When we did our research online, the Deep Java Library showed up on the top.
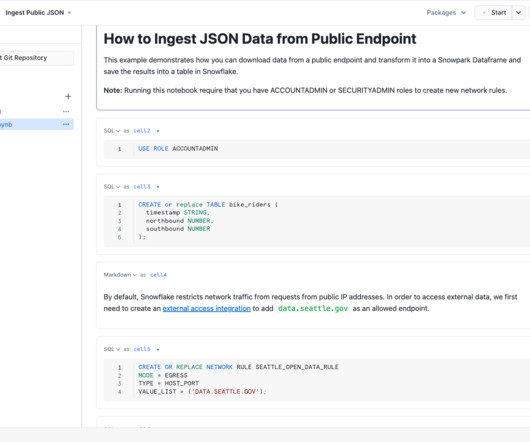
For greater detail, see the Snowflake documentation. DataPipelines “Datapipeline” means moving data in a consistent, secure, and reliable way at some frequency that meets your requirements. Datapipelines can be built with third-party tools alone or in conjunction with Snowflake’s tools.
However, in scenarios where dataset versioning solutions are leveraged, there can still be various challenges experienced by ML/AI/Data teams. Data aggregation: Data sources could increase as more data points are required to train ML models. Existing datapipelines will have to be modified to accommodate new data sources.
It’s common to have terabytes of data in most data warehouses, data quality monitoring is often challenging and cost-intensive due to dependencies on multiple tools and eventually ignored. This results in poor credibility and data consistency after some time, leading businesses to mistrust the datapipelines and processes.
This, in turn, helps them to build new datapipelines, solutions, and products, or clean up the data that’s there. It bears mentioning data profiling has evolved tremendously. Modern data profiling will also gather all the potential problems in one quick scan. Data migration Digital transformation is ongoing.
Business Analyst Though in many respects, quite similar to data analysts, you’ll find that business analysts most often work with a greater focus on industries such as finance, marketing, retail, and consulting. Tools such as the mentioned are critical for anyone interested in becoming a machine learning engineer.
Functional and non-functional requirements need to be documented clearly, which architecture design will be based on and support. Game changer ChatGPT in Software Engineering: A Glimpse Into the Future | HackerNoon Generative AI for DevOps: A Practical View - DZone ChatGPT for DevOps: Best Practices, Use Cases, and Warnings.
Founded in 2014 by three leading cloud engineers, phData focuses on solving real-world dataengineering, operations, and advanced analytics problems with the best cloud platforms and products. Over the years, one of our primary focuses became Snowflake and migrating customers to this leading cloud data platform.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content