This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data Science Dojo is offering Airbyte for FREE on Azure Marketplace packaged with a pre-configured web environment enabling you to quickly start the ELT process rather than spending time setting up the environment. Free to use. Conclusion There are a ton of small services that aren’t supported on traditional datapipeline platforms.
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Dataengineering is a hot topic in the AI industry right now. And as data’s complexity and volume grow, its importance across industries will only become more noticeable. But what exactly do dataengineers do? So let’s do a quick overview of the job of dataengineer, and maybe you might find a new interest.
We couldn’t be more excited to announce two events that will be co-located with ODSC East in Boston this April: The DataEngineering Summit and the Ai X Innovation Summit. These two co-located events represent an opportunity to dive even deeper into the topics and trends shaping these disciplines. Register for free today!
Dataengineering has become an integral part of the modern tech landscape, driving advancements and efficiencies across industries. So let’s explore the world of open-source tools for dataengineers, shedding light on how these resources are shaping the future of data handling, processing, and visualization.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference datapipeline on large datasets is a challenge many companies face. Check Tweets Batch Inference Job Status: Create an SQS listener that reads a message from the queue when the event rule publishes it.
It’s great for creating modern queue-based apps with large amounts of streamed data and modern protocols, and it reduces costs and dev time for dataengineers. Memphis has a simple UI, CLI, and SDKs, and offers features like automatic message retransmitting, storage tiering, and data-level observability.
We couldn’t be more excited to announce the first sessions for our second annual DataEngineering Summit , co-located with ODSC East this April. Join us for 2 days of talks and panels from leading experts and dataengineering pioneers. Is Gen AI A DataEngineering or Software Engineering Problem?
Additionally, imagine being a practitioner, such as a data scientist, dataengineer, or machine learning engineer, who will have the daunting task of learning how to use a multitude of different tools. A feature platform should automatically process the datapipelines to calculate that feature.
DataEngineerDataengineers are responsible for the end-to-end process of collecting, storing, and processing data. They use their knowledge of data warehousing, data lakes, and big data technologies to build and maintain datapipelines. Interested in attending an ODSC event?
If the question was Whats the schedule for AWS events in December?, AWS usually announces the dates for their upcoming # re:Invent event around 6-9 months in advance. Rajesh Nedunuri is a Senior DataEngineer within the Amazon Worldwide Returns and ReCommerce Data Services team.
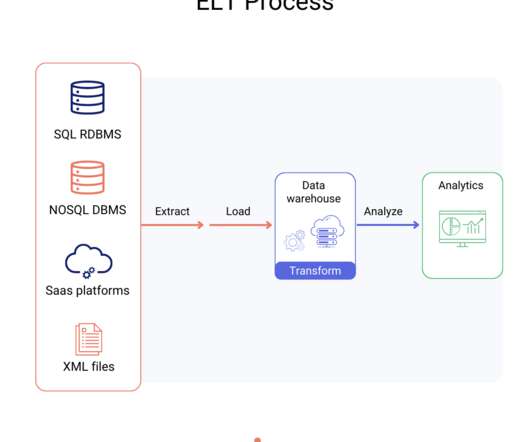
DataEngineering : Building and maintaining datapipelines, ETL (Extract, Transform, Load) processes, and data warehousing. Career Support Some bootcamps include job placement services like resume assistance, mock interviews, networking events, and partnerships with employers to aid in job placement.
Apache Kafka and Apache Flink working together Anyone who is familiar with the stream processing ecosystem is familiar with Apache Kafka: the de-facto enterprise standard for open-source event streaming. Apache Kafka streams get data to where it needs to go, but these capabilities are not maximized when Apache Kafka is deployed in isolation.
This May, were heading to Boston for ODSC East 2025, where data scientists, AI engineers, and industry leaders will gather to explore the latest advancements in AI, machine learning, and dataengineering. Lets dive into the schedule and key events that will shape this years conference.
Consequently, AIOps is designed to harness data and insight generation capabilities to help organizations manage increasingly complex IT stacks. Data characteristics and preprocessing AIOps tools handle a range of data sources and types, including system logs, performance metrics, network data and application events.
Data scientists and dataengineers want full control over every aspect of their machine learning solutions and want coding interfaces so that they can use their favorite libraries and languages. At the same time, business and data analysts want to access intuitive, point-and-click tools that use automated best practices.
In the later part of this article, we will discuss its importance and how we can use machine learning for streaming data analysis with the help of a hands-on example. What is streaming data? This will also help us observe the importance of stream data. It can be used to collect, store, and process streaming data in real-time.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. For example, neptune.ai
Elementl / Dagster Labs Elementl and Dagster Labs are both companies that provide platforms for building and managing datapipelines. Elementl’s platform is designed for dataengineers, while Dagster Labs’ platform is designed for data scientists. Interested in attending an ODSC event?
Collaboration across teams – Shared features allow disparate teams like fraud, marketing, and sales to collaborate on building ML models using the same reliable data instead of creating siloed features. Audit trail for compliance – Administrators can monitor feature usage by all accounts centrally using CloudTrail event logs.
By analyzing datasets, data scientists can better understand their potential use in an algorithm or machine learning model. The data science lifecycle Data science is iterative, meaning data scientists form hypotheses and experiment to see if a desired outcome can be achieved using available data.
Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication. Standard data science practices could also be contributing to this issue. Making dataengineering more systematic through principles and tools will be key to making AI algorithms work.
Find out how to weave data reliability and quality checks into the execution of your datapipelines and more. More Speakers and Sessions Announced for the 2024 DataEngineering Summit Ranging from experimentation platforms to enhanced ETL models and more, here are some more sessions coming to the 2024 DataEngineering Summit.
In this blog, we will highlight some of the most important upcoming features and updates for those who could not attend the events, specifically around AI and developer tools. It allows dataengineers familiar with Python and Pandas to run their Pandas code in a scalable and distributed manner. schemas["my_schema"].tables.create(my_table)
If you’re not familiar with DGIQ, it’s the world’s most comprehensive event dedicated to, you guessed it, data governance and information quality. This year’s DGIQ West will host tutorials, workshops, seminars, general conference sessions, and case studies for global data leaders.
In this post, we discuss how to bring data stored in Amazon DocumentDB into SageMaker Canvas and use that data to build ML models for predictive analytics. Without creating and maintaining datapipelines, you will be able to power ML models with your unstructured data stored in Amazon DocumentDB.
Tools such as the mentioned are critical for anyone interested in becoming a machine learning engineer. DataEngineerDataengineers are the authors of the infrastructure that stores, processes, and manages the large volumes of data an organization has. Well then, you’re in luck.
Curated foundation models, such as those created by IBM or Microsoft, help enterprises scale and accelerate the use and impact of the most advanced AI capabilities using trusted data. In addition to natural language, models are trained on various modalities, such as code, time-series, tabular, geospatial and IT eventsdata.
Methods that allow our customer data models to be as dynamic and flexible as the customers they represent. In this guide, we will explore concepts like transitional modeling for customer profiles, the power of event logs for customer behavior, persistent staging for raw customer data, real-time customer data capture, and much more.
It’s common to have terabytes of data in most data warehouses, data quality monitoring is often challenging and cost-intensive due to dependencies on multiple tools and eventually ignored. This results in poor credibility and data consistency after some time, leading businesses to mistrust the datapipelines and processes.
Founded in 2014 by three leading cloud engineers, phData focuses on solving real-world dataengineering, operations, and advanced analytics problems with the best cloud platforms and products. Over the years, one of our primary focuses became Snowflake and migrating customers to this leading cloud data platform.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
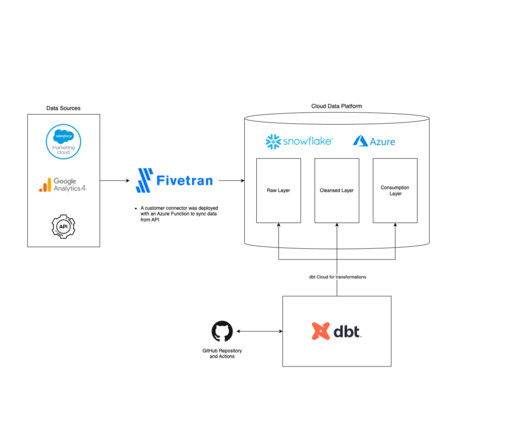
Understanding Fivetran Fivetran is a user-friendly, code-free platform enabling customers to easily synchronize their data by automating extraction, transformation, and loading from many sources. Fivetran automates the time-consuming steps of the ELT process so your dataengineers can focus on more impactful projects.
While traditional roles like data scientists and machine learning engineers remain essential, new positions like large language model (LLM) engineers and prompt engineers have gained traction. LLM Engineers: With job postings far exceeding the current talent pool, this role has become one of the hottest inAI.
So, in those projects, you have more than 70% of the engineering development resources that are tied to dataengineering activities. That is a mix of dataengineering, feature engineering work, a mix of data transformation work writ large. It is at the level of data quality and joining tasks.
Systems and data sources are more interconnected than ever before. A broken datapipeline might bring operational systems to a halt, or it could cause executive dashboards to fail, reporting inaccurate KPIs to top management. The application of this concept to data is relatively new. Complexity leads to risk.
Data Quality Dimensions Data quality dimensions are the criteria that are used to evaluate and measure the quality of data. These include the following: Accuracy indicates how correctly data reflects the real-world entities or events it represents. Datafold is a tool focused on data observability and quality.
In August 2019, Data Works was acquired and Dave worked to ensure a successful transition. David: My technical background is in ETL, data extraction, dataengineering and data analytics. David, what can you tell us about your background?
So, in those projects, you have more than 70% of the engineering development resources that are tied to dataengineering activities. That is a mix of dataengineering, feature engineering work, a mix of data transformation work writ large. It is at the level of data quality and joining tasks.
So, in those projects, you have more than 70% of the engineering development resources that are tied to dataengineering activities. That is a mix of dataengineering, feature engineering work, a mix of data transformation work writ large. It is at the level of data quality and joining tasks.
Scala is worth knowing if youre looking to branch into dataengineering and working with big data more as its helpful for scaling applications. Knowing all three frameworks covers the most ground for aspiring data science professionals, so you cover plenty of ground knowing thisgroup.
Knowing what needs to be done and in what order (the whole process and management side of data) is often overlooked , and we know sometimes keeping everyone up to date can be a bit tedious in its own way, but if you can orchestrate pipelines with dozens of steps in your sleep, you surely can take a moment to write what you’re up to, right?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content