This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
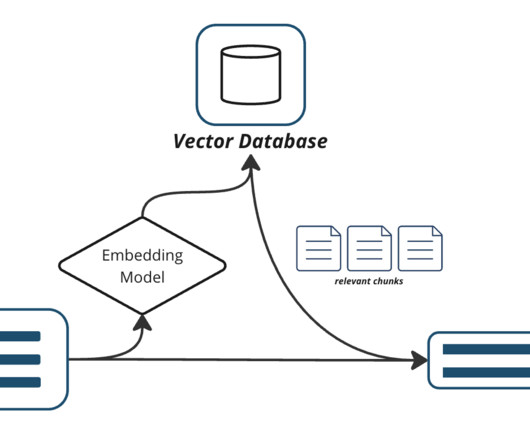
Introduction Databricks Lakehouse Monitoring allows you to monitor all your datapipelines – from data to features to ML models – without additional too.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Let’s learn about the services we will use to make this happen.
Instead, organizations are increasingly looking to take advantage of transformative technologies like machine learning (ML) and artificial intelligence (AI) to deliver innovative products, improve outcomes, and gain operational efficiencies at scale. Data is presented to the personas that need access using a unified interface.
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and MLengineers require capable tooling and sufficient compute for their work. Data scientists and MLengineers require capable tooling and sufficient compute for their work.
Dataengineers build datapipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these datapipelines in an overall workflow. Organizations can harness the full potential of their data while reducing risk and lowering costs.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and MLEngineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
The growth of the AI and Machine Learning (ML) industry has continued to grow at a rapid rate over recent years. Hidden Technical Debt in Machine Learning Systems More money, more problems — Rise of too many ML tools 2012 vs 2023 — Source: Matt Turck People often believe that money is the solution to a problem.
Machine learning (ML) is the technology that automates tasks and provides insights. It allows data scientists to build models that can automate specific tasks. It comes in many forms, with a range of tools and platforms designed to make working with ML more efficient. It also has ML algorithms built into the platform.
Automation Automating datapipelines and models ➡️ 6. Team Building the right data science team is complex. With a range of role types available, how do you find the perfect balance of Data Scientists , DataEngineers and Data Analysts to include in your team? Big Ideas What to look out for in 2022 1.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference datapipeline on large datasets is a challenge many companies face. The Batch job automatically launches an ML compute instance, deploys the model, and processes the input data in batches, producing the output predictions.
The onset of the pandemic has triggered a rapid increase in the demand and adoption of ML technology. Building ML team Following the surge in ML use cases that have the potential to transform business, the leaders are making a significant investment in ML collaboration, building teams that can deliver the promise of machine learning.
OMRONs data strategyrepresented on ODAPalso allowed the organization to unlock generative AI use cases focused on tangible business outcomes and enhanced productivity. About the Authors Emrah Kaya is DataEngineering Manager at Omron Europe and Platform Lead for ODAP Project.
Machine learning (ML) engineer Potential pay range – US$82,000 to 160,000/yr Machine learning engineers are the bridge between data science and engineering. Integrating the knowledge of data science with engineering skills, they can design, build, and deploy machine learning (ML) models.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
Cloud Computing, APIs, and DataEngineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. TensorFlow is desired for its flexibility for ML and neural networks, PyTorch for its ease of use and innate design for NLP, and scikit-learn for classification and clustering.
This article was co-written by Lawrence Liu & Safwan Islam While the title ‘ Machine Learning Engineer ’ may sound more prestigious than ‘DataEngineer’ to some, the reality is that these roles share a significant overlap. Generative AI has unlocked the value of unstructured text-based data.
Since 2018, our team has been developing a variety of ML models to enable betting products for NFL and NCAA football. These models are then pushed to an Amazon Simple Storage Service (Amazon S3) bucket using DVC, a version control tool for ML models. They use the DJL PyTorch engine to initialize the model predictor.
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines. He specializes in designing, building, and optimizing large-scale data solutions.
Amazon SageMaker Feature Store is a fully managed, purpose-built repository to store, share, and manage features for machine learning (ML) models. Features are inputs to ML models used during training and inference. Their task is to construct and oversee efficient datapipelines.
As companies continue to adopt machine learning (ML) in their workflows, the demand for scalable and efficient tools has increased. In this blog post, we will explore the performance benefits of Snowpark for ML workloads and how it can help businesses make better use of their data. Want to learn more? Can’t wait?
Instead, businesses tend to rely on advanced tools and strategies—namely artificial intelligence for IT operations (AIOps) and machine learning operations (MLOps)—to turn vast quantities of data into actionable insights that can improve IT decision-making and ultimately, the bottom line.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
Long-term ML project involves developing and sustaining applications or systems that leverage machine learning models, algorithms, and techniques. An example of a long-term ML project will be a bank fraud detection system powered by ML models and algorithms for pattern recognition. 2 Ensuring and maintaining high-quality data.
MLOps accelerates the ML model deployment process to make it more efficient and scalable. In this blog post, we detail the steps you need to take to build and run a successful MLOps pipeline. An extension of DevOps, MLOps streamlines and monitors ML workflows. MLOps pipelines support a production-first approach.
Just as a writer needs to know core skills like sentence structure, grammar, and so on, data scientists at all levels should know core data science skills like programming, computer science, algorithms, and so on. They’re looking for people who know all related skills, and have studied computer science and software engineering.
SageMaker geospatial capabilities make it straightforward for data scientists and machine learning (ML) engineers to build, train, and deploy models using geospatial data. Janosch Woschitz is a Senior Solutions Architect at AWS, specializing in AI/ML.
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machine learning (ML) solutions without writing code. Let’s add some transformations to get our data ready for training an ML model.
Purina used artificial intelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The solution focuses on the fundamental principles of developing an AI/ML application workflow of data preparation, model training, model evaluation, and model monitoring. DynamoDB is used to store the pet attributes.
Despite the challenges, Afri-SET, with limited resources, envisions a comprehensive data management solution for stakeholders seeking sensor hosting on their platform, aiming to deliver accurate data from low-cost sensors. This happens only when a new data format is detected to avoid overburdening scarce Afri-SET resources.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python MLPipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python MLPipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. His experience spans all things data across various domains and sectors.
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
Advanced-DataEngineering and ML Ops with Infrastructure as Code This member-only story is on us. Photo by Markus Winkler on Unsplash This story explains how to create and orchestrate machine learning pipelines with AWS Step Functions and deploy them using Infrastructure as Code. Upgrade to access all of Medium.
However, there are some key differences that we need to consider: Size and complexity of the data In machine learning, we are often working with much larger data. Basically, every machine learning project needs data. Given the range of tools and data types, a separate data versioning logic will be necessary.
Data Scientists and AI experts: Historically we have seen Data Scientists build and choose traditional ML models for their use cases. Data Scientists will typically help with training, validating, and maintaining foundation models that are optimized for data tasks.
Topics Include: Agentic AI DesignPatterns LLMs & RAG forAgents Agent Architectures &Chaining Evaluating AI Agent Performance Building with LangChain and LlamaIndex Real-World Applications of Autonomous Agents Who Should Attend: Data Scientists, Developers, AI Architects, and MLEngineers seeking to build cutting-edge autonomous systems.
This situation is not different in the ML world. Data Scientists and MLEngineers typically write lots and lots of code. Applying software design principles to dataengineering Dive into the integration of concrete software design principles and patterns within the realm of dataengineering.
Over the years, businesses have increasingly turned to Snowflake AI Data Cloud for various use cases beyond just data analytics and business intelligence. From dataengineering and machine learning to real-time data processing, Snowflake has become a central hub for organizations seeking to unify and leverage their data at scale.
And we at deployr , worked alongside them to find the best possible answers for everyone involved and build their Data and MLPipelines. Building data and MLpipelines: from the ground to the cloud It was the beginning of 2022, and things were looking bright after the lockdown’s end.
Data scientists and dataengineers want full control over every aspect of their machine learning solutions and want coding interfaces so that they can use their favorite libraries and languages. At the same time, business and data analysts want to access intuitive, point-and-click tools that use automated best practices.
Both computer scientists and business leaders have taken note of the potential of the data. Machine learning (ML), a subset of artificial intelligence (AI), is an important piece of data-driven innovation. MLOps is the next evolution of data analysis and deep learning. What is MLOps?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content