This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As the role of the dataengineer continues to grow in the field of data science, so are the many tools being developed to support wrangling all that data. Five of these tools are reviewed here (along with a few bonus tools) that you should pay attention to for your datapipeline work.
Build a streaming datapipeline using Formula 1 data, Python, Kafka, RisingWave as the streaming database, and visualize all the real-time data in Grafana.
In the data-driven world […] The post Monitoring Data Quality for Your Big DataPipelines Made Easy appeared first on Analytics Vidhya. Determine success by the precision of your charts, the equipment’s dependability, and your crew’s expertise. A single mistake, glitch, or slip-up could endanger the trip.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a DataPipeline with PySpark and AWS appeared first on Analytics Vidhya.
.- Dale Carnegie” Apache Kafka is a Software Framework for storing, reading, and analyzing streaming data. The post Build a Simple Realtime DataPipeline appeared first on Analytics Vidhya. The Internet of Things(IoT) devices can generate a large […].
Introduction to Apache Airflow “Apache Airflow is the most widely-adopted, open-source workflow management platform for dataengineeringpipelines. Most organizations today with complex datapipelines to […].
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
This article was published as a part of the Data Science Blogathon. Introduction When creating datapipelines, Software Engineers and DataEngineers frequently work with databases using Database Management Systems like PostgreSQL.
Introduction Imagine yourself as a data professional tasked with creating an efficient datapipeline to streamline processes and generate real-time information. Sounds challenging, right? That’s where Mage AI comes in to ensure that the lenders operating online gain a competitive edge.
Dataengineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and dataengineers are responsible for designing and implementing the systems and infrastructure that make this possible.
Navigating the World of DataEngineering: A Beginner’s Guide. A GLIMPSE OF DATAENGINEERING ❤ IMAGE SOURCE: BY AUTHOR Data or data? No matter how you read or pronounce it, data always tells you a story directly or indirectly. Dataengineering can be interpreted as learning the moral of the story.
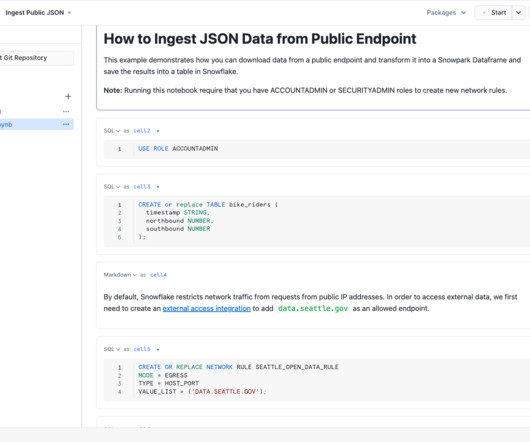
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
It is designed to assist dataengineers in transforming, converting, and validating data in a simplified manner while ensuring accuracy and reliability. The Meltano CLI can efficiently handle complex dataengineering tasks, providing a user-friendly interface that simplifies the ELT process.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Aspiring and experienced DataEngineers alike can benefit from a curated list of books covering essential concepts and practical techniques. These 10 Best DataEngineering Books for beginners encompass a range of topics, from foundational principles to advanced data processing methods. What is DataEngineering?
This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines. What is an ETL datapipeline in ML?
Dataengineering is a hot topic in the AI industry right now. And as data’s complexity and volume grow, its importance across industries will only become more noticeable. But what exactly do dataengineers do? So let’s do a quick overview of the job of dataengineer, and maybe you might find a new interest.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
Cloud Computing, APIs, and DataEngineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. DataEngineering Platforms Spark is still the leader for datapipelines but other platforms are gaining ground. Knowing some SQL is also essential.
Automation Automating datapipelines and models ➡️ 6. Team Building the right data science team is complex. With a range of role types available, how do you find the perfect balance of Data Scientists , DataEngineers and Data Analysts to include in your team? Big Ideas What to look out for in 2022 1.
Python is the top programming language used by dataengineers in almost every industry. Python has proven proficient in setting up pipelines, maintaining data flows, and transforming data with its simple syntax and proficiency in automation. Why Connect Snowflake to Python?
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference datapipeline on large datasets is a challenge many companies face. Airflow setup Apache Airflow is an open-source tool for orchestrating workflows and data processing pipelines.
We couldn’t be more excited to announce the first sessions for our second annual DataEngineering Summit , co-located with ODSC East this April. Join us for 2 days of talks and panels from leading experts and dataengineering pioneers. In the meantime, check out our first group of sessions.
Enrich dataengineering skills by building problem-solving ability with real-world projects, teaming with peers, participating in coding challenges, and more. Globally several organizations are hiring dataengineers to extract, process and analyze information, which is available in the vast volumes of data sets.
Data science bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of data science. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization.
Snowpark, offered by the Snowflake AI Data Cloud , consists of libraries and runtimes that enable secure deployment and processing of non-SQL code, such as Python, Java, and Scala. In this blog, we’ll cover the steps to get started, including: How to set up an existing Snowpark project on your local system using a Python IDE.
This doesn’t mean anything too complicated, but could range from basic Excel work to more advanced reporting to be used for data visualization later on. Computer Science and Computer Engineering Similar to knowing statistics and math, a data scientist should know the fundamentals of computer science as well.
DataEngineerDataengineers are responsible for the end-to-end process of collecting, storing, and processing data. They use their knowledge of data warehousing, data lakes, and big data technologies to build and maintain datapipelines.
The solution harnesses the capabilities of generative AI, specifically Large Language Models (LLMs), to address the challenges posed by diverse sensor data and automatically generate Python functions based on various data formats. The solution only invokes the LLM for new device data file type (code has not yet been generated).
Python Timestamp: Converting and Formatting Essentials for Beginners In this article, we will explore the different ways to work with timestamps in Python, including generating, converting, and comparing timestamps. Here are 7 AI trends that we think will define the landscape over the next year.
That’s why many organizations invest in technology to improve data processes, such as a machine learning datapipeline. However, data needs to be easily accessible, usable, and secure to be useful — yet the opposite is too often the case. How can dataengineers address these challenges directly?
Introduction Are you curious about the latest advancements in the data tech industry? Perhaps you’re hoping to advance your career or transition into this field. In that case, we invite you to check out DataHour, a series of webinars led by experts in the field.
This setup uses the AWS SDK for Python (Boto3) to interact with AWS services. Rajesh Nedunuri is a Senior DataEngineer within the Amazon Worldwide Returns and ReCommerce Data Services team. He specializes in designing, building, and optimizing large-scale data solutions.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. For example, neptune.ai and Pandas or Apache Spark DataFrames.
Snowflake AI Data Cloud is one of the most powerful platforms, including storage services supporting complex data. Integrating Snowflake with dbt adds another layer of automation and control to the datapipeline. Snowflake stored procedures and dbt Hooks are essential to modern dataengineering and analytics workflows.
Snowflake announced many new features that will enhance development and collaboration: Snowflake Notebooks: Currently available in public preview, Snowflake notebooks provide a notebook interface that enables data teams to collaborate with Python and SQL in one place. Furthermore, Snowflake Notebooks can also be run on a schedule.
Right now, most deep learning frameworks are built for Python, but this neglects the large number of Java developers and developers who have existing Java code bases they want to integrate the increasingly powerful capabilities of deep learning into. For this reason, many DJL users also use it for inference only. With v0.21.0
This blog will cover creating customized nodes in Coalesce, what new advanced features can already be used as nodes, and how to create them as part of your datapipeline. Dynamic Tables Dynamic tables , a recent feature in Snowflake, are a game changer for dataengineering.
With Cortex, business analysts, dataengineers, and developers can easily incorporate Predictive and Generative AI into their workflows using simple SQL commands and intuitive interfaces. As an example, check out our blog post on implementing a dataengineeringpipeline for Sentiment Analysis with dbt.
This May, were heading to Boston for ODSC East 2025, where data scientists, AI engineers, and industry leaders will gather to explore the latest advancements in AI, machine learning, and dataengineering. Were also going to start another AI Bootcamp cohort in April if you want to experience everything live.
Applying Machine Learning with Snowpark Now that we have our data from the Snowflake Marketplace, it’s time to leverage Snowpark to apply machine learning. Python has long been the favorite programming language of data scientists. For a short demo on Snowpark, be sure to check out the video below.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content