This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Alonside data management frameworks, a holistic approach to dataengineering for AI is needed along with data provenance controls and datapreparation tools.
Businesses need to understand the trends in datapreparation to adapt and succeed. If you input poor-quality data into an AI system, the results will be poor. This principle highlights the need for careful datapreparation, ensuring that the input data is accurate, consistent, and relevant.
Introduction Data science has taken over all economic sectors in recent times. To achieve maximum efficiency, every company strives to use various data at every stage of its operations.
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler. Within the data flow, add an Amazon S3 destination node.
It is intended to assist organizations in simplifying the big data and analytics process by providing a consistent experience for datapreparation, administration, and discovery. Introduction Microsoft Azure Synapse Analytics is a robust cloud-based analytics solution offered as part of the Azure platform.
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports. In the menu bar on the left, select Workspaces.
“Almost 70-80% of the work involves datapreparation, engineering, and standardisation. It’s all manual work, and frankly, the most painful activity,” said DataSwitch chief Karthikeyan Viswanathan in an exclusive interview with AIM.
The field of data science is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for data science hires peak. Their insights must be in line with real-world goals.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Aspiring and experienced DataEngineers alike can benefit from a curated list of books covering essential concepts and practical techniques. These 10 Best DataEngineering Books for beginners encompass a range of topics, from foundational principles to advanced data processing methods. What is DataEngineering?
With over 50 connectors, an intuitive Chat for data prep interface, and petabyte support, SageMaker Canvas provides a scalable, low-code/no-code (LCNC) ML solution for handling real-world, enterprise use cases. Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data.
Datapreparation isn’t just a part of the ML engineering process — it’s the heart of it. Photo by Myriam Jessier on Unsplash To set the stage, let’s examine the nuances between research-phase data and production-phase data. Reading Data: Aggregating all sources into a single combined dataset.
Additionally, these tools provide a comprehensive solution for faster workflows, enabling the following: Faster datapreparation – SageMaker Canvas has over 300 built-in transformations and the ability to use natural language that can accelerate datapreparation and making data ready for model building.
Data Scientists will typically help with training, validating, and maintaining foundation models that are optimized for data tasks. DataEngineer: A dataengineer sets the foundation of building any generating AI app by preparing, cleaning and validating data required to train and deploy AI models.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of dataengineering and data science team’s bandwidth and datapreparation activities.
We will demonstrate an example feature engineering process on an e-commerce schema and how GraphReduce deals with the complexity of feature engineering on the relational schema. Datapreparation happens at the entity-level first so errors and anomalies don’t make their way into the aggregated dataset.
These tools offer a wide range of functionalities to handle complex datapreparation tasks efficiently. The tool also employs AI capabilities for automatically providing attribute names and short descriptions for reports, making it easy to use and efficient for datapreparation.
This is how we came up with the DataEngine - an end-to-end solution for creating training-ready datasets and fast experimentation. Let’s explain how the DataEngine helps teams do just that. Data cleaning complexity, dealing with diverse data types, and preprocessing large volumes of data consumes time and resources.
The vendors evaluated for this MarketScape offer various software tools needed to support end-to-end machine learning (ML) model development, including datapreparation, model building and training, model operation, evaluation, deployment, and monitoring.
First, there’s a need for preparing the data, aka dataengineering basics. Machine learning practitioners are often working with data at the beginning and during the full stack of things, so they see a lot of workflow/pipeline development, data wrangling, and datapreparation.
Dataengineering – Identifies the data sources, sets up data ingestion and pipelines, and preparesdata using Data Wrangler. Data science – The heart of ML EBA and focuses on feature engineering, model training, hyperparameter tuning, and model validation.
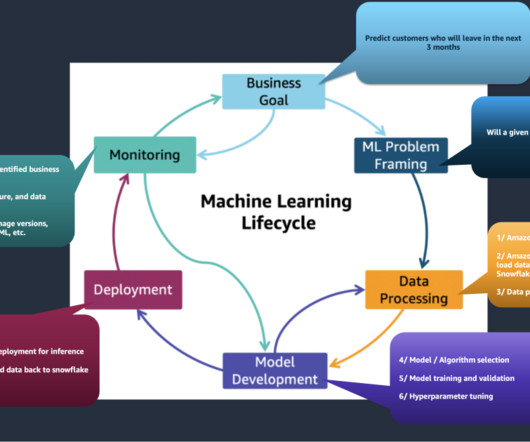
Thus, MLOps is the intersection of Machine Learning, DevOps, and DataEngineering (Figure 1). Figure 4: The ModelOps process [Wikipedia] The Machine Learning Workflow Machine learning requires experimenting with a wide range of datasets, datapreparation, and algorithms to build a model that maximizes some target metric(s).
Increased operational efficiency benefits Reduced datapreparation time : OLAP datapreparation capabilities streamline data analysis processes, saving time and resources. IBM watsonx.data is the next generation OLAP system that can help you make the most of your data.
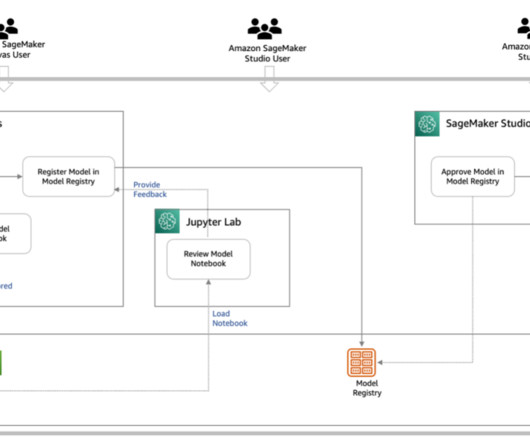
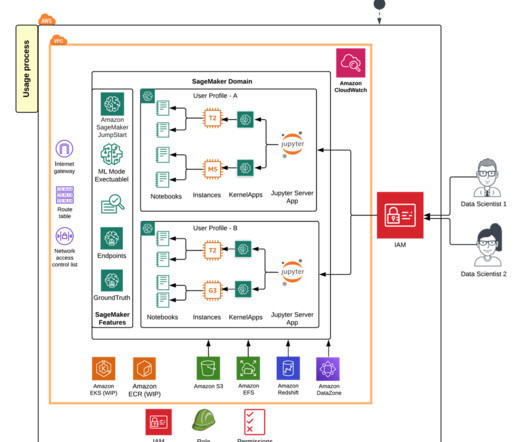
Launched in 2019, Amazon SageMaker Studio provides one place for all end-to-end machine learning (ML) workflows, from datapreparation, building and experimentation, training, hosting, and monitoring. As a web application, SageMaker Studio has improved load time, faster IDE and kernel start up times, and automatic upgrades.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services.
Catch the full demo and explore our resources Our demo’s goal was to help dataengineers see firsthand the practical ways that both Snowflake and Domo’s Cloud Amplifier via API/SDK can amplify their businesses.
Datapreparation and training The datapreparation and training pipeline includes the following steps: The training data is read from a PrestoDB instance, and any feature engineering needed is done as part of the SQL queries run in PrestoDB at retrieval time.
The Evolving AI Development Lifecycle Despite the revolutionary capabilities of LLMs, the core development lifecycle established by traditional natural language processing remains essential: Plan, PrepareData, Engineer Model, Evaluate, Deploy, Operate, and Monitor. For instance: DataPreparation: GoogleSheets.
Starting today, you can connect to Amazon EMR Hive as a big data query engine to bring in large datasets for ML. Aggregating and preparing large amounts of data is a critical part of ML workflow. Solution overview With SageMaker Studio setups, data professionals can quickly identify and connect to existing EMR clusters.
Vertex AI assimilates workflows from data science, dataengineering, and machine learning to help your teams work together with a shared toolkit and grow your apps with the help of Google Cloud. Conclusion Vertex AI is a major improvement over Google Cloud’s machine learning and data science solutions.
SageMaker Studio provides all the tools you need to take your models from datapreparation to experimentation to production while boosting your productivity. Amazon SageMaker Canvas is a powerful no-code ML tool designed for business and data teams to generate accurate predictions without writing code or having extensive ML experience.
MLOps is the intersection of Machine Learning, DevOps, and DataEngineering. The MLOps Process We can see some of the differences with MLOps which is a set of methods and techniques to deploy and maintain machine learning (ML) models in production reliably and efficiently.
Such a pipeline encompasses the stages involved in building, testing, tuning, and deploying ML models, including but not limited to datapreparation, feature engineering, model training, evaluation, deployment, and monitoring. The following diagram illustrates the workflow.
From datapreparation and model training to deployment and management, Vertex AI provides the tools and infrastructure needed to build intelligent applications. Unified ML Workflow: Vertex AI provides a simplified ML workflow, encompassing data ingestion, analysis, transformation, model training, evaluation, and deployment.
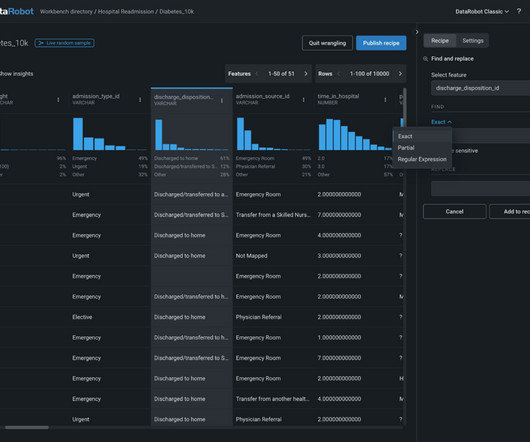
In Nick Heudecker’s session on Driving Analytics Success with DataEngineering , we learned about the rise of the dataengineer role – a jack-of-all-trades data maverick who resides either in the line of business or IT. DataRobot Data Prep. Duncan | Ehtisham Zaidi | Guido De Simoni | Douglas Laney. [5]
This happens only when a new data format is detected to avoid overburdening scarce Afri-SET resources. Having a human-in-the-loop to validate each data transformation step is optional. Automatic code generation reduces dataengineering work from months to days.
Members were encouraged to take advantage of the wide array of courses, and specialized training as well as the Associate and Professional Certifications, in Data Analysis, Data Science, and DataEngineering. She explained that not many universities in the U.S.
Data-centric AI, in his opinion, is based on the following principles: It’s time to focus on the data — after all the progress achieved in algorithms means it’s now time to spend more time on the data Inconsistent data labels are common since reasonable, well-trained people can see things differently.
Who This Book Is For This book is for practitioners in charge of building, managing, maintaining, and operationalizing the ML process end to end: Data science / AI / ML leaders: Heads of Data Science, VPs of Advanced Analytics, AI Lead etc. Exploratory data analysis (EDA) and modeling.
The DataRobot team has been working hard on new integrations that make data scientists more agile and meet the needs of enterprise IT, starting with Snowflake. We’ve tightened the loop between ML data prep , experimentation and testing all the way through to putting models into production.
Consequently, AIOps is designed to harness data and insight generation capabilities to help organizations manage increasingly complex IT stacks. MLOps prioritizes end-to-end management of machine learning models, encompassing datapreparation, model training, hyperparameter tuning and validation.
We use a test datapreparation notebook as part of this step, which is a dependency for the fine-tuning and batch inference step. When fine-tuning is complete, this notebook is run using run magic and prepares a test dataset for sample inference with the fine-tuned model.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content