This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports. In the menu bar on the left, select Workspaces.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of dataengineering and data science team’s bandwidth and datapreparation activities.
Organizations in which AI developers or software engineers are involved in the stage of developing AI use cases are much more likely to reach mature levels of AI implementation. DataScientists and AI experts: Historically we have seen DataScientists build and choose traditional ML models for their use cases.
Summary: This blog provides a comprehensive roadmap for aspiring Azure DataScientists, outlining the essential skills, certifications, and steps to build a successful career in Data Science using Microsoft Azure. This roadmap aims to guide aspiring Azure DataScientists through the essential steps to build a successful career.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Aspiring and experienced DataEngineers alike can benefit from a curated list of books covering essential concepts and practical techniques. These 10 Best DataEngineering Books for beginners encompass a range of topics, from foundational principles to advanced data processing methods. What is DataEngineering?
In an increasingly digital and rapidly changing world, BMW Group’s business and product development strategies rely heavily on data-driven decision-making. With that, the need for datascientists and machine learning (ML) engineers has grown significantly. JuMa automatically provisions a new AWS account for the workspace.
From data collection and cleaning to feature engineering, model building, tuning, and deployment, ML projects often take months for developers to complete. And experienced datascientists can be hard to come by. Datapreparation is typically the most time-intensive phase of the ML workflow.
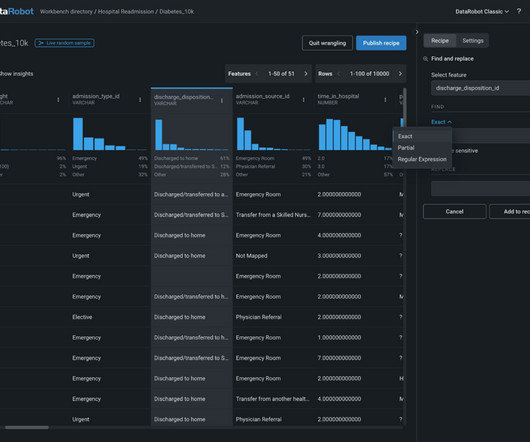
Data preprocessing ensures the removal of incorrect, incomplete, and inaccurate data from datasets, leading to the creation of accurate and useful datasets for analysis ( Image Credit ) Data completeness One of the primary requirements for data preprocessing is ensuring that the dataset is complete, with minimal missing values.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Dataengineers use data warehouses, data lakes, and analytics tools to load, transform, clean, and aggregate data.
The vendors evaluated for this MarketScape offer various software tools needed to support end-to-end machine learning (ML) model development, including datapreparation, model building and training, model operation, evaluation, deployment, and monitoring. AI life-cycle tools are essential to productize AI/ML solutions.
Data-centric AI, in his opinion, is based on the following principles: It’s time to focus on the data — after all the progress achieved in algorithms means it’s now time to spend more time on the data Inconsistent data labels are common since reasonable, well-trained people can see things differently. The choice is yours.
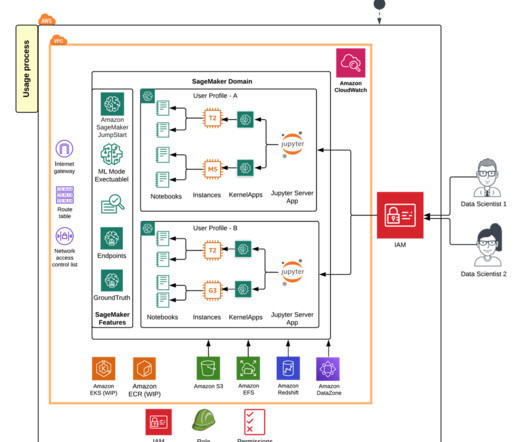
Launched in 2019, Amazon SageMaker Studio provides one place for all end-to-end machine learning (ML) workflows, from datapreparation, building and experimentation, training, hosting, and monitoring. As a web application, SageMaker Studio has improved load time, faster IDE and kernel start up times, and automatic upgrades.
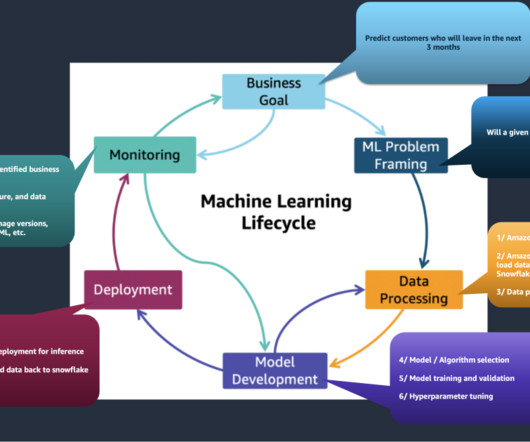
Thus, MLOps is the intersection of Machine Learning, DevOps, and DataEngineering (Figure 1). Figure 4: The ModelOps process [Wikipedia] The Machine Learning Workflow Machine learning requires experimenting with a wide range of datasets, datapreparation, and algorithms to build a model that maximizes some target metric(s).
The Evolving AI Development Lifecycle Despite the revolutionary capabilities of LLMs, the core development lifecycle established by traditional natural language processing remains essential: Plan, PrepareData, Engineer Model, Evaluate, Deploy, Operate, and Monitor. For instance: DataPreparation: GoogleSheets.
Such a pipeline encompasses the stages involved in building, testing, tuning, and deploying ML models, including but not limited to datapreparation, feature engineering, model training, evaluation, deployment, and monitoring. The following diagram illustrates the workflow.
Vertex AI assimilates workflows from data science, dataengineering, and machine learning to help your teams work together with a shared toolkit and grow your apps with the help of Google Cloud. Conclusion Vertex AI is a major improvement over Google Cloud’s machine learning and data science solutions.
Datascientists run experiments. To work effectively, datascientists need agility in the form of access to enterprise data, streamlined tooling, and infrastructure that just works. We’ve tightened the loop between ML data prep , experimentation and testing all the way through to putting models into production.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. For example, neptune.ai Check out the Kubeflow documentation.
The first is by using low-code or no-code ML services such as Amazon SageMaker Canvas , Amazon SageMaker Data Wrangler , Amazon SageMaker Autopilot , and Amazon SageMaker JumpStart to help data analysts preparedata, build models, and generate predictions. Conduct exploratory analysis and datapreparation.
This post is co-written with Swagata Ashwani, Senior DataScientist at Boomi. Boomi is an enterprise-level software as a service (SaaS) independent software vendor (ISV) that creates developer enablement tooling for software engineers. Her interests include MLOps, natural language processing, and data visualization.
Amazon SageMaker Studio provides a fully managed solution for datascientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow datascientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
Consequently, AIOps is designed to harness data and insight generation capabilities to help organizations manage increasingly complex IT stacks. MLOps prioritizes end-to-end management of machine learning models, encompassing datapreparation, model training, hyperparameter tuning and validation.
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful data processing capabilities of EMR Serverless.
Datapreparation and training The datapreparation and training pipeline includes the following steps: The training data is read from a PrestoDB instance, and any feature engineering needed is done as part of the SQL queries run in PrestoDB at retrieval time.
Starting today, you can connect to Amazon EMR Hive as a big data query engine to bring in large datasets for ML. Aggregating and preparing large amounts of data is a critical part of ML workflow. Solution overview With SageMaker Studio setups, data professionals can quickly identify and connect to existing EMR clusters.
From datapreparation and model training to deployment and management, Vertex AI provides the tools and infrastructure needed to build intelligent applications. Unified ML Workflow: Vertex AI provides a simplified ML workflow, encompassing data ingestion, analysis, transformation, model training, evaluation, and deployment.
Because the machine learning lifecycle has many complex components that reach across multiple teams, it requires close-knit collaboration to ensure that hand-offs occur efficiently, from datapreparation and model training to model deployment and monitoring. Generative AI relies on foundation models to create a scalable process.
These modern tools will auto-profile the data, detect joins and overlaps, and offer recommendations. With AI infused throughout, the industry is moving towards a place where data analytics is far less biased, and where citizen datascientists will have greater power and agility to accomplish more in less time. Free Trial.
Studio provides all the tools you need to take your models from datapreparation to experimentation to production while boosting your productivity. The main benefit is that a datascientist can choose which script to run to customize the container with new packages.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Dataengineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
It brings together DataEngineering, Data Science, and Data Analytics. Thus providing a collaborative and interactive environment for teams to work on data-intensive projects. Databricks and offers a collaborative workspace where dataengineers, datascientists, and analysts can work together seamlessly.
With sports (and everything else) cancelled, this datascientist decided to take on COVID-19 | A Winner’s Interview with David Mezzetti When his hobbies went on hiatus, Kaggler David Mezzetti made fighting COVID-19 his mission. In August 2019, Data Works was acquired and Dave worked to ensure a successful transition.
At Tableau, we wanted to understand use cases and common issues from our most advanced datascientists to general data consumers. While not exhaustive, here are additional capabilities to consider as part of your data management and governance solution: Datapreparation. Data modeling.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities.
With newfound support for open formats such as Parquet and Apache Iceberg, Netezza enables dataengineers, datascientists and data analysts to share data and run complex workloads without duplicating or performing additional ETL.
Who This Book Is For This book is for practitioners in charge of building, managing, maintaining, and operationalizing the ML process end to end: Data science / AI / ML leaders: Heads of Data Science, VPs of Advanced Analytics, AI Lead etc. Exploratory data analysis (EDA) and modeling.
At Tableau, we wanted to understand use cases and common issues from our most advanced datascientists to general data consumers. While not exhaustive, here are additional capabilities to consider as part of your data management and governance solution: Datapreparation. Data modeling.
By exploring data from different perspectives with visualizations, you can identify patterns, connections, insights and relationships within that data and quickly understand large amounts of information. AutoAI automates datapreparation, model development, feature engineering and hyperparameter optimization.
And that’s really key for taking data science experiments into production. And one of the biggest challenges that we see is taking an idea, an experiment, or an ML experiment that datascientists might be running in their notebooks and putting that into production.
And that’s really key for taking data science experiments into production. And one of the biggest challenges that we see is taking an idea, an experiment, or an ML experiment that datascientists might be running in their notebooks and putting that into production.
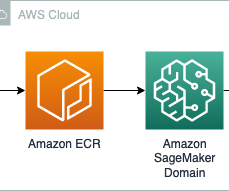
It supports all stages of ML development—from datapreparation to deployment, and allows you to launch a preconfigured JupyterLab IDE for efficient coding within seconds. Amazon ECR is a managed container registry that facilitates the storage, management, and deployment of container images.
Introduction to Containers for Data Science / DataEngineering with Michael A. Fudge’s AI slides introduced participants to using containers in data science and engineering workflows. Steven Pousty showcased how to transform unstructured data into a vector-based query system. Fudge Slides Michael A.
SageMaker Studio allows datascientists, ML engineers, and dataengineers to preparedata, build, train, and deploy ML models on one web interface. Key concepts Amazon SageMaker Studio is a web-based, integrated development environment (IDE) for machine learning.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content