This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
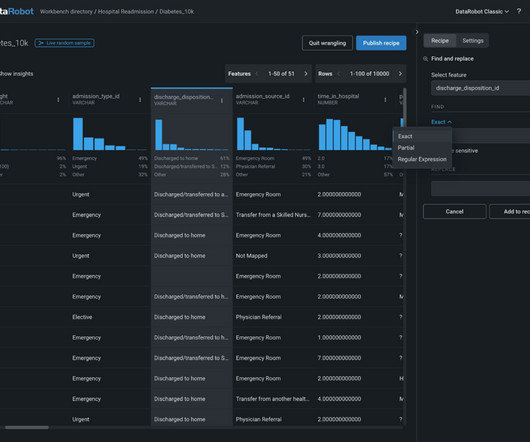
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler. Within the data flow, add an Amazon S3 destination node.
It is intended to assist organizations in simplifying the big data and analytics process by providing a consistent experience for datapreparation, administration, and discovery. Introduction Microsoft Azure Synapse Analytics is a robust cloud-based analytics solution offered as part of the Azure platform.
The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage. Also, traditional database management tasks, including backups, upgrades and routine maintenance drain valuable time and resources, hindering innovation.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Datapreparation isn’t just a part of the ML engineering process — it’s the heart of it. Photo by Myriam Jessier on Unsplash To set the stage, let’s examine the nuances between research-phase data and production-phase data. Reading Data: Aggregating all sources into a single combined dataset.
Aspiring and experienced DataEngineers alike can benefit from a curated list of books covering essential concepts and practical techniques. These 10 Best DataEngineering Books for beginners encompass a range of topics, from foundational principles to advanced data processing methods. What is DataEngineering?
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of dataengineering and data science team’s bandwidth and datapreparation activities.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Complete the following steps: On the project page, choose Data.
Data Scientists will typically help with training, validating, and maintaining foundation models that are optimized for data tasks. DataEngineer: A dataengineer sets the foundation of building any generating AI app by preparing, cleaning and validating data required to train and deploy AI models.
Online analytical processing (OLAP) database systems and artificial intelligence (AI) complement each other and can help enhance data analysis and decision-making when used in tandem. Defining OLAP today OLAP database systems have significantly evolved since their inception in the early 1990s.
In the demo, we provisioned five primary tables, all within the same database. How to use Cloud Amplifier to: Create a unified source of truth This one’s simple — by writing the enriched data back to Snowflake, we created a single, unified source of truth.
However, the majority of enterprise data remains unleveraged from an analytics and machine learning perspective, and much of the most valuable information remains in relational database schemas such as OLAP. Datapreparation happens at the entity-level first so errors and anomalies don’t make their way into the aggregated dataset.
These tools offer a wide range of functionalities to handle complex datapreparation tasks efficiently. The tool also employs AI capabilities for automatically providing attribute names and short descriptions for reports, making it easy to use and efficient for datapreparation.
The Evolving AI Development Lifecycle Despite the revolutionary capabilities of LLMs, the core development lifecycle established by traditional natural language processing remains essential: Plan, PrepareData, Engineer Model, Evaluate, Deploy, Operate, and Monitor. Previously, consultants spent weeks manually querying data.
The solution harnesses the capabilities of generative AI, specifically Large Language Models (LLMs), to address the challenges posed by diverse sensor data and automatically generate Python functions based on various data formats. This allows for data to be aggregated for further manufacturer-agnostic analysis.
JuMa is tightly integrated with a range of BMW Central IT services, including identity and access management, roles and rights management, BMW Cloud Data Hub (BMW’s data lake on AWS) and on-premises databases. He works closely with enterprise customers to design data platforms and build advanced analytics and ML use cases.
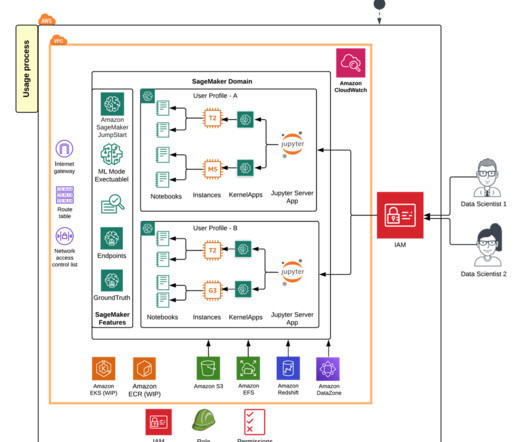
Starting today, you can connect to Amazon EMR Hive as a big data query engine to bring in large datasets for ML. Aggregating and preparing large amounts of data is a critical part of ML workflow. Solution overview With SageMaker Studio setups, data professionals can quickly identify and connect to existing EMR clusters.
Here, we predict whether an order is a high_value_order or a low_value_order based on the orderpriority as given from the TPC-H data. For more information on the TPC-H data, its database entities, relationships, and characteristics, refer to TPC Benchmark H.
Data-centric AI, in his opinion, is based on the following principles: It’s time to focus on the data — after all the progress achieved in algorithms means it’s now time to spend more time on the data Inconsistent data labels are common since reasonable, well-trained people can see things differently.
The solution focuses on the fundamental principles of developing an AI/ML application workflow of datapreparation, model training, model evaluation, and model monitoring. Amazon DynamoDB is a fast and flexible nonrelational database service for any scale. It uses Rekognition Custom Labels to predict the pet breed.
Such a pipeline encompasses the stages involved in building, testing, tuning, and deploying ML models, including but not limited to datapreparation, feature engineering, model training, evaluation, deployment, and monitoring. The following diagram illustrates the workflow.
Introduction to Containers for Data Science / DataEngineering with Michael A. Fudge’s AI slides introduced participants to using containers in data science and engineering workflows. Steven Pousty showcased how to transform unstructured data into a vector-based query system. Fudge Slides Michael A.
The starting range for a SQL Data Analyst is $61,128 per annum. How SQL Important in Data Analytics? Sincerely, SQL is used by Data Analysts for storing data in a particular type of Database and ensures flexibility in accessing or updating data. An SQL Data Analyst is vital for an organisation.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. Dolt Dolt is an open-source relational database system built on Git.
The DataRobot team has been working hard on new integrations that make data scientists more agile and meet the needs of enterprise IT, starting with Snowflake. We’ve tightened the loop between ML data prep , experimentation and testing all the way through to putting models into production.
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful data processing capabilities of EMR Serverless. He is a big supporter of Arsenal football club and spends spare time playing and watching soccer.
Snowflake stored procedures are programmable routines that allow users to encapsulate and execute complex logic directly in a Snowflake database. Snowflake stored procedures and dbt Hooks are essential to modern dataengineering and analytics workflows. What are Snowflake Stored Procedures & dbt Hooks? Why Does it Matter?
Alteryx provides organizations with an opportunity to automate access to data, analytics , data science, and process automation all in one, end-to-end platform. Its capabilities can be split into the following topics: automating inputs & outputs, datapreparation, data enrichment, and data science.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities. Later this year, it will leverage watsonx.ai
More on this topic later; but for now, keep in mind that the simplest method is to create a naming convention for database objects that allows you to identify the owner and associated budget. The extended period will allow you to perform Time Travel activities, such as undropping tables or comparing new data against historical values.
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into data warehouses or databases for analysis. The goal is to retrieve the required data efficiently without overwhelming the source systems.
In this blog, we’ll explain why you should prepare your data before use in machine learning , how to clean and preprocess the data, and a few tips and tricks about datapreparation. Why PrepareData for Machine Learning Models? It may hurt it by adding in irrelevant, noisy data.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Dataengineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
It systematically collects data from diverse sources such as databases, online repositories, sensors, and other digital platforms, ensuring a comprehensive dataset is available for subsequent analysis and insights extraction. Sources of DataData can come from multiple sources. Removing outliers is also necessary.
There are several reasons why your organization might consider migrating your data from Amazon Web Services (AWS) Redshift to the Snowflake Data Cloud. As an experienced dataengineering consulting company, phData has helped with numerous migrations to Snowflake.
Automated development: With AutoAI , beginners can quickly get started and more advanced data scientists can accelerate experimentation in AI development. AutoAI automates datapreparation, model development, feature engineering and hyperparameter optimization.
Below, we explore five popular data transformation tools, providing an overview of their features, use cases, strengths, and limitations. Apache Nifi Apache Nifi is an open-source data integration tool that automates system data flow. The right tool can significantly enhance efficiency, scalability, and data quality.
In August 2019, Data Works was acquired and Dave worked to ensure a successful transition. David: My technical background is in ETL, data extraction, dataengineering and data analytics. An ETL process was built to take the CSV, find the corresponding text articles and load the data into a SQLite database.
And that’s really key for taking data science experiments into production. The data scientists will start with experimentation, and then once they find some insights and the experiment is successful, then they hand over the baton to dataengineers and ML engineers that help them put these models into production.
And that’s really key for taking data science experiments into production. The data scientists will start with experimentation, and then once they find some insights and the experiment is successful, then they hand over the baton to dataengineers and ML engineers that help them put these models into production.
DataPreparation: Cleaning, transforming, and preparingdata for analysis and modelling. Collaborating with Teams: Working with dataengineers, analysts, and stakeholders to ensure data solutions meet business needs.
These outputs, stored in vector databases like Weaviate, allow Prompt Enginers to directly access these embeddings for tasks like semantic search, similarity analysis, or clustering. For prompt engineers, it can be used for the deployment and orchestration of LLM applications.
After your generative AI workload environment has been secured, you can layer in AI/ML-specific features, such as Amazon SageMaker Data Wrangler to identify potential bias during datapreparation and Amazon SageMaker Clarify to detect bias in ML data and models.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content