This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
generally available on May 24, Alation introduces the Open DataQuality Initiative for the modern data stack, giving customers the freedom to choose the dataquality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and Data Governance application.
“Quality over Quantity” is a phrase we hear regularly in life, but when it comes to the world of data, we often fail to adhere to this rule. DataQuality Monitoring implements quality checks in operational data processes to ensure that the data meets pre-defined standards and business rules.
Additionally, imagine being a practitioner, such as a data scientist, dataengineer, or machine learning engineer, who will have the daunting task of learning how to use a multitude of different tools. Source: IBM Cloud Pak for Data MLOps teams often struggle when it comes to integrating into CI/CD pipelines.
Aspiring and experienced DataEngineers alike can benefit from a curated list of books covering essential concepts and practical techniques. These 10 Best DataEngineering Books for beginners encompass a range of topics, from foundational principles to advanced data processing methods. What is DataEngineering?
In essence, DataOps is a practice that helps organizations manage and govern data more effectively. However, there is a lot more to know about DataOps, as it has its own definition, principles, benefits, and applications in real-life companies today – which we will cover in this article! Automated testing to ensure dataquality.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
Jacomo Corbo is a Partner and Chief Scientist, and Bryan Richardson is an Associate Partner and Senior Data Scientist, for QuantumBlack AI by McKinsey. They presented “Automating DataQuality Remediation With AI” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. That is still in flux and being worked out.
Other users Some other users you may encounter include: Dataengineers , if the data platform is not particularly separate from the ML platform. Analytics engineers and data analysts , if you need to integrate third-party business intelligence tools and the data platform, is not separate. Allegro.io
A data management solution can help you make better business decisions by giving you access to the right information at the right time. Dataengineering services can analyze large amounts of data and identify trends that would otherwise be missed. Big data management increases the reliability of your data.
Governance can — and should — be the responsibility of every data user, though how that’s achieved will depend on the role within the organization. This article will focus on how dataengineers can improve their approach to data governance. How can dataengineers address these challenges directly?
For example, Tableau dataengineers want a single source of truth to help avoid creating inconsistencies in data sets, while line-of-business users are concerned with how to access the latest data for trusted analysis when they need it most. Dataquality: Gone are the days of “data is data, and we just need more.”
For example, Tableau dataengineers want a single source of truth to help avoid creating inconsistencies in data sets, while line-of-business users are concerned with how to access the latest data for trusted analysis when they need it most. Dataquality: Gone are the days of “data is data, and we just need more.”
Making this data visible in the data catalog will let data teams share their work, support re-use, and empower everyone to better understand and trust data. Data Transformation in the Modern Data Stack. Dataengineering plays a critical role in distributing data to a wide audience.
It promotes a disciplined approach to data modeling, making it easier to ensure dataquality and consistency across the ML pipelines. Moreover, it provides a straightforward way to track data lineage, so we can foresee which datasets will be affected by newly introduced changes.
For any data user in an enterprise today, data profiling is a key tool for resolving dataquality issues and building new data solutions. In this blog, we’ll cover the definition of data profiling, top use cases, and share important techniques and best practices for data profiling today.
Reichental describes data governance as the overarching layer that empowers people to manage data well ; as such, it is focused on roles & responsibilities, policies, definitions, metrics, and the lifecycle of the data. In this way, data governance is the business or process side. Communication is essential.
With Alation Anywhere launching in beta, we will meet people where they are, helping to deliver context and trustworthiness of data, from and across the modern data stack, starting with Tableau. With this integration, Alation descriptions and dataquality flags of warnings and deprecations will propagate to Tableau.
Data mesh says architectures should be decentralized because there are inherent problems with centralized architectures. For example, when we centralize, all the focus goes on the dataengineers. But there are only so many dataengineers available in the market today; there’s a big skills shortage.
Data mesh forgoes technology edicts and instead argues for “decentralized data ownership” and the need to treat “data as a product”. Gartner on Data Fabric. Moreover, data catalogs play a central role in both data fabric and data mesh. We’ll dig into this definition in a bit. Design concept.
At first, “governance progress” metrics could be utilised, such as: What % of tables have a data steward assigned? What % of tables have a definition? What % of data is or isn’t assigned to a domain? What % of columns have dataquality rules implemented? What are the benefits of reducing duplicate data?
Catalog Enhanced data trust, visibility, and discoverability Tableau Catalog automatically catalogs all your data assets and sources into one central list and provides metadata in context for fast data discovery. Included with Data Management.
Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Introduction In today’s business landscape, data integration is vital.
The next plausible question that you should be asking is, what one must define in the labeling guidelines so that the resultant annotations can be of good quality. This clear definition reduces the issues like subjectivity as each annotator will follow the same set of instructions and the produced annotations will be uniform.
This crucial stage involves data cleaning, normalisation, transformation, and integration. By addressing issues like missing values, duplicates, and inconsistencies, preprocessing enhances dataquality and reliability for subsequent analysis. Data Cleaning Data cleaning is crucial for data integrity.
One may define enterprise data analytics as the ability to find, understand, analyze, and trust data to drive strategy and decision-making. Enterprise data analytics integrates data, business, and analytics disciplines, including: Data management. Dataengineering. Evaluate and monitor dataquality.
Data governance and security Like a fortress protecting its treasures, data governance, and security form the stronghold of practical Data Intelligence. Think of data governance as the rules and regulations governing the kingdom of information. It ensures dataquality , integrity, and compliance.
American Family Insurance: Governance by Design – Not as an Afterthought Who: Anil Kumar Kunden , Information Standards, Governance and Quality Specialist at AmFam Group When: Wednesday, June 7, at 2:45 PM Why attend: Learn how to automate and accelerate data pipeline creation and maintenance with data governance, AKA metadata normalization.
Here are some challenges you might face while managing unstructured data: Storage consumption: Unstructured data can consume a large volume of storage. For instance, if you are working with several high-definition videos, storing them would take a lot of storage space, which could be costly.
DataQuality Next, dive into the details of your data. Now, a single customer might use multiple emails or phone numbers, but matching in this way provides a precise definition that could significantly reduce or even eliminate the risk of accidentally associating the actions of multiple customers with one identity.
Organizations struggle in multiple aspects, especially in modern-day dataengineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. More features mean more data consumed upstream. That is definitely a problem.
Organizations struggle in multiple aspects, especially in modern-day dataengineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. More features mean more data consumed upstream. That is definitely a problem.
Organizations struggle in multiple aspects, especially in modern-day dataengineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. More features mean more data consumed upstream. That is definitely a problem.
Unsupervised learning has shown a big potential in large language models but high-quality labelled data remains the gold standard for AI systems to be accurate and aligned with human language and understanding. LabelBox LabelBox is an AI-powered dataengine platform that supports text annotation along with other data types.
The most critical and impactful step you can take towards enterprise AI today is ensuring you have a solid data foundation built on the modern data stack with mature operational pipelines, including all your most critical operational data. This often involves software engineering, dataengineering, and system design skills.
Embracing Automation: As already mentioned, the abstraction that the Modern Data Stack provides means that most of the infrastructure maintenance that would typically be required to maintain an enterprise data platform is automated away. Testing: Dataengineering should be treated as a form of software engineering.
For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, data governance becomes crucial. This includes dataquality, privacy, and compliance. Two Data Scientists: Responsible for setting up the ML models training and experimentation pipelines.
In the rapidly evolving landscape of dataengineering, Snowflake Data Cloud has emerged as a leading cloud-based data warehousing solution, providing powerful capabilities for storing, processing, and analyzing vast amounts of data.
Key Takeaways: Trusted AI requires data integrity. For AI-ready data, focus on comprehensive data integration, dataquality and governance, and data enrichment. Building data literacy across your organization empowers teams to make better use of AI tools. The impact?
Organizational resiliency draws on and extends the definition of resiliency in the AWS Well-Architected Framework to include and prepare for the ability of an organization to recover from disruptions.
DataQuality Management : Persistent staging provides a clear demarcation between raw and processed customer data. This makes it easier to implement and manage dataquality processes, ensuring your marketing efforts are based on clean, reliable data. All this raw data goes into your persistent stage.
It serves as a vital protective measure, ensuring proper data access while managing risks like data breaches and unauthorized use. Strong data governance also lays the foundation for better model performance, cost efficiency, and improved dataquality, which directly contributes to regulatory compliance and more secure AI systems.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































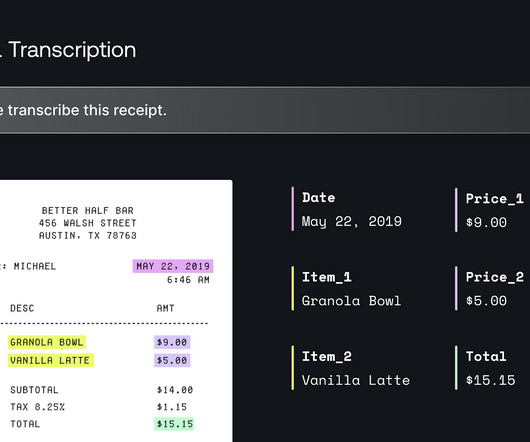















Let's personalize your content