This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
generally available on May 24, Alation introduces the Open DataQuality Initiative for the modern data stack, giving customers the freedom to choose the dataquality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and Data Governance application.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
Organizations require reliable data for robust AI models and accurate insights, yet the current technology landscape presents unparalleled dataquality challenges. Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable.
This blog post explores effective strategies for gathering requirements in your data project. Whether you are a data analyst , project manager, or dataengineer, these approaches will help you clarify needs, engage stakeholders, and ensure requirements gathering techniques to create a roadmap for success.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
Beyond Scale: DataQuality for AI Infrastructure The trajectory of AI over the past decade has been driven largely by the scale of data available for training and the ability to process it with increasingly powerful compute & experimental models. Author(s): Richie Bachala Originally published on Towards AI.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Also Read: Top 10 Data Science tools for 2024.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Dataengineering is a rapidly growing field that designs and develops systems that process and manage large amounts of data. There are various architectural design patterns in dataengineering that are used to solve different data-related problems.
The ability to effectively deploy AI into production rests upon the strength of an organization’s data strategy because AI is only as strong as the data that underpins it. With that, a strategy that empowers less technical users and accelerates time to value for specialized data teams is critical.
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue DataQuality , Amazon Redshift ML , and Amazon QuickSight. You can review the recommendations and augment rules from over 25 included dataquality rules.
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines. He specializes in designing, building, and optimizing large-scale data solutions.
IBM’s data lineage solution for banking regulatory compliance For helping clients take advantage of data lineage, we recommend IBM Cloud Pak for Data for several reasons.
The batch views within the Lambda architecture allow for the application of more complex or resource-intensive rules, resulting in superior dataquality and reduced bias over time. On the other hand, the real-time views provide immediate access to the most current data.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning. AWS Glue AWS Glue is a fully managed ETL service provided by Amazon Web Services.
Set specific, measurable targets Data science goals to “increase sales” lack the clarity needed to evaluate success and secure ongoing funding. Audit existing data assets Inventory internal datasets, ETL capabilities, past analytical initiatives, and available skill sets.
How to become a data scientist Data transformation also plays a crucial role in dealing with varying scales of features, enabling algorithms to treat each feature equally during analysis Noise reduction As part of data preprocessing, reducing noise is vital for enhancing dataquality.
For instance, a notebook that monitors for model data drift should have a pre-step that allows extract, transform, and load (ETL) and processing of new data and a post-step of model refresh and training in case a significant drift is noticed. Run the notebooks The sample code for this solution is available on GitHub.
Catalog Enhanced data trust, visibility, and discoverability Tableau Catalog automatically catalogs all your data assets and sources into one central list and provides metadata in context for fast data discovery. Included with Data Management.
As the latest iteration in this pursuit of high-qualitydata sharing, DataOps combines a range of disciplines. It synthesizes all we’ve learned about agile, dataquality , and ETL/ELT. And it injects mature process control techniques from the world of traditional engineering.
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: DataQuality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, data governance becomes crucial. This includes dataquality, privacy, and compliance. Two Data Scientists: Responsible for setting up the ML models training and experimentation pipelines.
Machine Learning Data pipelines feed all the necessary data into machine learning algorithms, thereby making this branch of Artificial Intelligence (AI) possible. DataQuality When using a data pipeline, data consistency, quality, and reliability are often greatly improved.
Implement business rules and validations: Data Vault models often involve enforcing business rules and performing dataquality checks. Leverage dbt’s `test` macros within your models and add constraints to ensure data integrity between data vault entities. This is where automation tools come into play.
ThoughSpot can easily connect to top cloud data platforms such as Snowflake AI Data Cloud , Oracle, SAP HANA, and Google BigQuery. In that case, ThoughtSpot also leverages ELT/ETL tools and Mode, a code-first AI-powered data solution that gives data teams everything they need to go from raw data to the modern BI stack.
General Purpose Tools These tools help manage the unstructured data pipeline to varying degrees, with some encompassing data collection, storage, processing, analysis, and visualization. DagsHub's DataEngine DagsHub's DataEngine is a centralized platform for teams to manage and use their datasets effectively.
Example of Information Kept for a Simple Data Catalog Implications of Choosing the Wrong Methodology Choosing the wrong data lake methodology can have profound and lasting consequences for an organization. Inaccurate or inconsistent data can undermine decision-making and erode trust in analytics.
Machine Learning Data pipelines feed all the necessary data into machine learning algorithms, thereby making this branch of Artificial Intelligence (AI) possible. DataQuality When using a data pipeline, data consistency, quality, and reliability are often greatly improved.
If the event log is your customer’s diary, think of persistent staging as their scrapbook – a place where raw customer data is collected, organized, and kept for future reference. In traditional ETL (Extract, Transform, Load) processes in CDPs, staging areas were often temporary holding pens for data.
The most critical and impactful step you can take towards enterprise AI today is ensuring you have a solid data foundation built on the modern data stack with mature operational pipelines, including all your most critical operational data. This often involves software engineering, dataengineering, and system design skills.
In the rapidly evolving landscape of dataengineering, Snowflake Data Cloud has emerged as a leading cloud-based data warehousing solution, providing powerful capabilities for storing, processing, and analyzing vast amounts of data.
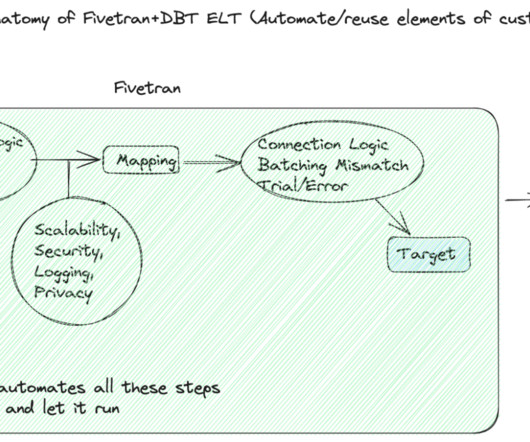
In our previous blog , we discussed how Fivetran and dbt scale for any data volume and workload, both small and large. Now, you might be wondering what these tools can do for your data team and the efficiency of your organization as a whole. Can these tools help reduce the time our dataengineers spend fixing things?
An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
Slow Response to New Information: Legacy data systems often lack the computation power necessary to run efficiently and can be cost-inefficient to scale. This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data. Read more here.
Data-driven culture cannot exist without the democratization of the data. Data democratization certainly does not mean unrestricted access to all […]. The post How a Modern DataEngineering Stack Can Help Create a Data-Driven Culture appeared first on DATAVERSITY.
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. Thats where dataengineering tools come in!
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content