This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Beyond Scale: DataQuality for AI Infrastructure The trajectory of AI over the past decade has been driven largely by the scale of data available for training and the ability to process it with increasingly powerful compute & experimental models. Author(s): Richie Bachala Originally published on Towards AI.
This is how we came up with the DataEngine - an end-to-end solution for creating training-ready datasets and fast experimentation. Let’s explain how the DataEngine helps teams do just that. Preparing and organizing data into a format suitable for training models presents significant challenges for ML teams.
This capability allows Deep Learning models to excel in tasks such as image and speech recognition, natural language processing, and more. Job Roles and Responsibilities DataEngineering: Defining data requirements, collecting, cleaning, and preprocessing data for training Deep Learning models.
Organizations struggle in multiple aspects, especially in modern-day dataengineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. More features mean more data consumed upstream. AR : Yeah.
Organizations struggle in multiple aspects, especially in modern-day dataengineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. More features mean more data consumed upstream. AR : Yeah.
Organizations struggle in multiple aspects, especially in modern-day dataengineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. More features mean more data consumed upstream. AR : Yeah.
DataQuality and Consistency in Labeling While high dataquality and consistent labeling across the dataset are crucial, achieving them can be a little challenging if you do not follow and standardized approach, proper guidelines, and efficient tools and software.
Elementl / Dagster Labs Elementl and Dagster Labs are both companies that provide platforms for building and managing data pipelines. Elementl’s platform is designed for dataengineers, while Dagster Labs’ platform is designed for data scientists. However, there are some critical differences between the two companies.
Text labeling has enabled all sorts of frameworks and strategies in machine learning. Text Data Labeling Techniques Text data labeling is a nuanced process, where success lies in finding the right balance between human expertise and automatic efficiency for each specific use case.
Other users Some other users you may encounter include: Dataengineers , if the data platform is not particularly separate from the ML platform. Analytics engineers and data analysts , if you need to integrate third-party business intelligence tools and the data platform, is not separate. Allegro.io
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









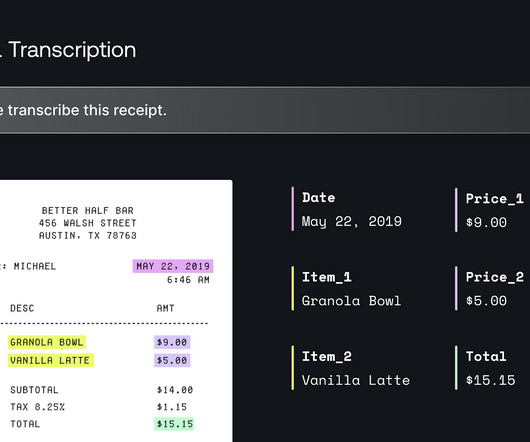







Let's personalize your content