This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
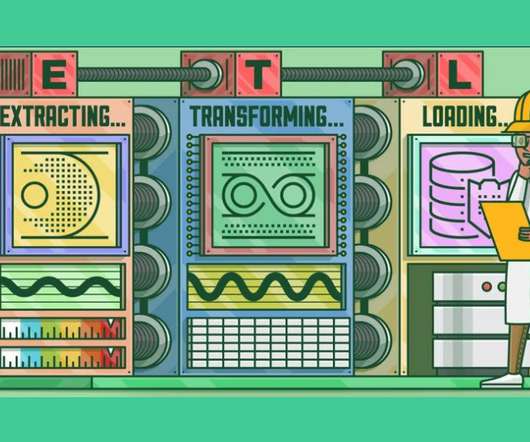
This article was published as a part of the DataScience Blogathon. Introduction At the highest level, ETL converts your data before uploading, while ELT converts data only after uploading to your repository. The post ETL & ELT – DataEngineering Essentials appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Overview: Assume the job of a DataEngineer, extracting data from. The post Implementing ETL Process Using Python to Learn DataEngineering appeared first on Analytics Vidhya.
Remote work quickly transitioned from a perk to a necessity, and datascience—already digital at heart—was poised for this change. For data scientists, this shift has opened up a global market of remote datascience jobs, with top employers now prioritizing skills that allow remote professionals to thrive.
This article was published as a part of the DataScience Blogathon A data scientist’s ability to extract value from data is closely related to how well-developed a company’s data storage and processing infrastructure is.
ArticleVideo Book This article was published as a part of the DataScience Blogathon. Introduction ETL pipelines look different today than they used to. The post Is manual ETL better than No-Code ETL: Are ETL tools dead? appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction Processing large amounts of raw data from various sources requires appropriate tools and solutions for effective data integration. Building an ETL pipeline using Apache […]. Building an ETL pipeline using Apache […].
This article was published as a part of the DataScience Blogathon. Overview ETL (Extract, Transform, and Load) is a very common technique in dataengineering. Traditionally, ETL processes are […]. The post Crafting Serverless ETL Pipeline Using AWS Glue and PySpark appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. The post ETL and Workflow Orchestration Tools appeared first on Analytics Vidhya. We’ll continue […].
This article was published as a part of the DataScience Blogathon. Introduction Organizations with a separate transactional database and data warehouse typically have many dataengineering activities. For example, they extract, transform and load data from various sources into their data warehouse.
This article was published as a part of the DataScience Blogathon. Introduction Data is ubiquitous in our modern life. Obtaining, structuring, and analyzing these data into new, relevant information is crucial in today’s world. The post ETL vs ELT in 2022: Do they matter?
This article was published as a part of the DataScience Blogathon What is ETL? ETL is a process that extracts data from multiple source systems, changes it (through calculations, concatenations, and so on), and then puts it into the Data Warehouse system. ETL stands for Extract, Transform, and Load.
This article was published as a part of the DataScience Blogathon. Introduction AWS Glue helps DataEngineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. It provides organizations with […].
Navigating the realm of datascience careers is no longer a tedious task. In the current landscape, datascience has emerged as the lifeblood of organizations seeking to gain a competitive edge. DataEngineerDataengineers are responsible for building, maintaining, and optimizing data infrastructures.
This article was published as a part of the DataScience Blogathon. Source: [link] Introduction If you are familiar with databases, or data warehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well.
This article was published as a part of the DataScience Blogathon. Introduction Data acclimates to countless shapes and sizes to complete its journey from a source to a destination. Be it a streaming job or a batch job, ETL and ELT are irreplaceable.
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in datascience and dataengineering. It supports a holistic data model, allowing for rapid prototyping of various models.
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. The source data is unstructured JSON, while the target is a structured, relational database.
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
This article was published as a part of the DataScience Blogathon. Introduction Data scientists, engineers, and BI analysts often need to analyze, process, or query different data sources.
Datascience bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of datascience. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization.
Rockets legacy datascience environment challenges Rockets previous datascience solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided DataScience Experience development tools.
This post is a bitesize walk-through of the 2021 Executive Guide to DataScience and AI — a white paper packed with up-to-date advice for any CIO or CDO looking to deliver real value through data. Team Building the right datascience team is complex. Download the free, unabridged version here.
Learn the basics of dataengineering to improve your ML modelsPhoto by Mike Benna on Unsplash It is not news that developing Machine Learning algorithms requires data, often a lot of data. Collecting this data is not trivial, in fact, it is one of the most relevant and difficult parts of the entire workflow.
DataScience Dojo is offering Meltano CLI for FREE on Azure Marketplace preconfigured with Meltano, a platform that provides flexibility and scalability. Not to worry as DataScience Dojo’s Meltano CLI instance fixes all of that. Meltano CLI stands out as a dataengineering tool. Already feeling tired?
Last Updated on March 21, 2023 by Editorial Team Author(s): DataScience meets Cyber Security Originally published on Towards AI. Navigating the World of DataEngineering: A Beginner’s Guide. A GLIMPSE OF DATAENGINEERING ❤ IMAGE SOURCE: BY AUTHOR Data or data? What are ETL and data pipelines?
In the contemporary age of Big Data, Data Warehouse Systems and DataScience Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures? appeared first on DataScience Blog.
DataScience You heard this term most of the time all over the internet, as well this is the most concerning topic for newbies who want to enter the world of data but don’t know the actual meaning of it. I’m not saying those are incorrect or wrong even though every article has its mindset behind the term ‘ DataScience ’.
Die Bedeutung effizienter und zuverlässiger Datenpipelines in den Bereichen DataScience und DataEngineering ist enorm. Data Lakes: Unterstützt MS Azure Blob Storage. Pipelines/ETL : Unterstützt Technologien wie SQL Server Integration Services und Azure Data Factory.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
Many organizations have been using a combination of on-premises and open source datascience solutions to create and manage machine learning (ML) models. Datascience and DevOps teams may face challenges managing these isolated tool stacks and systems.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Best tools and platforms for MLOPs – DataScience Dojo Google Cloud Platform Google Cloud Platform is a comprehensive offering of cloud computing services. Google Cloud Platform is a great option for businesses that need high-performance computing, such as datascience, AI, machine learning, and financial services.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
In the world of AI-driven data workflows, Brij Kishore Pandey, a Principal Engineer at ADP and a respected LinkedIn influencer, is at the forefront of integrating multi-agent systems with Generative AI for ETL pipeline orchestration. ETL ProcessBasics So what exactly is ETL? What is an Agent?
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. Extract, transform and Load Before we begin, let’s shed some light on what an ETL pipeline essentially is. ELT stands for extract, load and transform.
The advent of big data, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in datascience across industries. However, research shows that up to 85% of datascience projects fail to move beyond proofs of concept to full-scale deployment.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
Getting Started with AI in High-Risk Industries, How to Become a DataEngineer, and Query-Driven Data Modeling How To Get Started With Building AI in High-Risk Industries This guide will get you started building AI in your organization with ease, axing unnecessary jargon and fluff, so you can start today. Register here!
Depending the organization situation and data strategy, on premises or hybrid approaches should be also considered. What makes the difference is a smart ETL design capturing the nature of process mining data. By utilizing these services, organizations can store large volumes of event data without incurring substantial expenses.
The fusion of data in a central platform enables smooth analysis to optimize processes and increase business efficiency in the world of Industry 4.0 using methods from business intelligence , process mining and datascience. Cloud Data Platform for shopfloor management and data sources such like MES, ERP, PLM and machine data.
Building end-to-end datascience solutions means developing data collection, feature engineering, model building and model serving processes. It’s overwhelming at first, so let’s just focus on the main part development as the ‘DataEngineer’ — DAGS. It’s a lot of stuff to stay on top of, right?
Engineering teams, in particular, can quickly get overwhelmed by the abundance of information pertaining to competition data, new product and service releases, market developments, and industry trends, resulting in information anxiety. Explosive data growth can be too much to handle. Can’t get to the data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content