This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon. Introduction In this article, we will be looking for a very common yet very important topic i.e. SQL also pronounced as Ess-cue-ell. The post Introduction to SQL for DataEngineering appeared first on Analytics Vidhya.
Remote work quickly transitioned from a perk to a necessity, and datascience—already digital at heart—was poised for this change. For data scientists, this shift has opened up a global market of remote datascience jobs, with top employers now prioritizing skills that allow remote professionals to thrive.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction DataScience is a most emerging field with numerous job. The post SQL For DataScience: A Beginner’s Guide! appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction The essential element for any organization’s operation is data. Data is getting significant and gaining more traction by the day. Hence it is required to store such a large amount of data carefully.
4 Useful Intermediate SQL Queries for DataScience • How to Select Rows and Columns in Pandas Using [ ],loc, iloc,at and.iat • 3 Free Machine Learning Courses for Beginners • 7 Essential Cheat Sheets for DataEngineering • 7 Techniques to Handle Imbalanced Data.
This article was published as a part of the DataScience Blogathon. Introduction to SQL Clauses SQL clauses like HAVING and WHERE both serve to filter data based on a set of conditions. The difference between the functionality of HAVING and WHERE as SQL clauses are generally asked for in SQL interview questions.
The collection includes free courses on Python, SQL, Data Analytics, Business Intelligence, DataEngineering, Machine Learning, Deep Learning, Generative AI, and MLOps.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Overview This article provides an overview of data analysis using SQL, The post Beginner’s Guide For Data Analysis Using SQL appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction The structured data we generally deal with gets stored in a tabular format in relational databases. And stored data in these databases can be accessed by a query language called “sequel” or SQL. But, it is […].
This article was published as a part of the DataScience Blogathon. Introduction Dear DataEngineers, this article is a very interesting topic. Let me give some flashback; a few years ago, Mr.Someone in the discussion coined the new word how ACID and BASE properties of DATA. Suddenly drop silence in the room.
The Biggest DataScience Blogathon is now live! Martin Uzochukwu Ugwu Analytics Vidhya is back with the largest data-sharing knowledge competition- The DataScience Blogathon. Knowledge is power. Sharing knowledge is the key to unlocking that power.”―
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction SQL is one of the most widely used skills when. The post Understand The Basics of Data Analysis using SQL appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Introduction Pandas have come a long way on their own, and. The post Pandasql -The Best Way to Run SQL Queries in Python appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon Introduction Google’s BigQuery is an enterprise-grade cloud-native data warehouse. Since its inception, BigQuery has evolved into a more economical and fully managed data warehouse that can run lightning-fast […].
Navigating the realm of datascience careers is no longer a tedious task. In the current landscape, datascience has emerged as the lifeblood of organizations seeking to gain a competitive edge. DataEngineerDataengineers are responsible for building, maintaining, and optimizing data infrastructures.
An estimated 8,650% growth of the volume of Data to 175 zetabytes from 2010 to 2025 has created an enormous need for DataEngineers to build an organization's big data platform to be fast, efficient and scalable.
While not all of us are tech enthusiasts, we all have a fair knowledge of how DataScience works in our day-to-day lives. All of this is based on DataScience which is […]. The post Step-by-Step Roadmap to Become a DataEngineer in 2023 appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon Overview of Apache Calcite Making your own SQL database or running SQL queries against a NoSQL database seems to be a very daunting task. The post How to screw SQL to anything with Apache Calcite appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon Overview of SQL Query Optimization SQL Query optimization is defined as the iterative process of enhancing the performance of a query in terms of execution time, the number of disk accesses, and many more cost measuring criteria.
This article was published as a part of the DataScience Blogathon. The post Top 10 Mistakes to avoid in SQL Query appeared first on Analytics Vidhya. Introduction We all make mistakes and learn from them. It is a good practice to make mistakes but not repeat them in the future.
This article was published as a part of the DataScience Blogathon. Introduction SQL proficiency is crucial for the field of datascience. We’ll talk about two SQL queries that product businesses use to screen applicants for jobs as data scientists in this article.
10 Cheat Sheets You Need To Ace DataScience Interview • 7 Free Platforms for Building a Strong DataScience Portfolio • The Complete Free PyTorch Course for Deep Learning • 3 Valuable Skills That Have Doubled My Income as a Data Scientist • 25 Advanced SQL Interview Questions for Data Scientists • A DataScience Portfolio That Will Land You The Job (..)
Hey, are you the datascience geek who spends hours coding, learning a new language, or just exploring new avenues of datascience? The post DataScience Blogathon 28th Edition appeared first on Analytics Vidhya. If all of these describe you, then this Blogathon announcement is for you!
Introduction Structured Query Language is a powerful language to manage and manipulate data stored in databases. SQL is widely used in the field of datascience and is considered an essential skill to have if you work with data.
The database is the major element of a datascience project. So, we are […] The post How to Normalize Relational Databases With SQL Code? To generate actionable insights, the database must be centralized and organized efficiently. appeared first on Analytics Vidhya.
This article was published as a part of the DataScience Blogathon. Introduction to Data Warehouse SQLData Warehouse is also a cloud-based data warehouse that uses Massively Parallel Processing (MPP) to run complex queries across petabytes of data rapidly. Import big […].
What is Chebychev's Theorem and How Does it Apply to DataScience? Linux for DataScience Cheatsheet • The Complete DataEngineering Study Roadmap • 10 Amazing Machine Learning Visualizations You Should Know in 2023 • 7 SQL Concepts Needed for DataScience.
This article was published as a part of the DataScience Blogathon. Introduction When we hear the word “DATABASE”, the first thought that comes to our mind is SQL! No doubt, SQL and relational databases are widely popular and used extensively for storing data.
These sessions will cover everything from conversational intelligence to people analytics covering topics like […] The post Ace Your DataScience Skills with DataHour Sessions appeared first on Analytics Vidhya.
5 SQL Visualization Tools for DataEngineers • Free TensorFlow 2.0 Complete Course • The Importance of Probability in DataScience • 4 Ways to Rename Pandas Columns • 5 Statistical Paradoxes Data Scientists Should Know
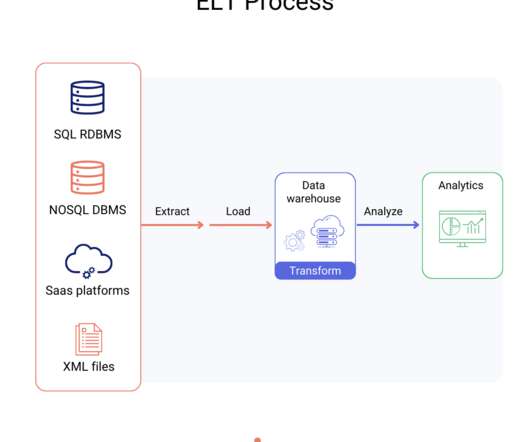
DataScience Dojo is offering Airbyte for FREE on Azure Marketplace packaged with a pre-configured web environment enabling you to quickly start the ELT process rather than spending time setting up the environment. Manual full refresh: Re-syncs all your data to start again whenever you want.
In the technology-driven world we inhabit, two skill sets have risen to prominence and are a hot topic: coding vs datascience. Coding vs DataScience Coding goes beyond just software creation, impacting fields as diverse as healthcare, finance, and entertainment. What is DataScience?
This article was published as a part of the DataScience Blogathon. Introduction Amazon Athena is an interactive query service based on open-source Apache Presto that allows you to analyze data stored in Amazon S3 using ANSI SQL directly.
This article was published as a part of the DataScience Blogathon What is the need for Hive? The official description of Hive is- ‘Apache Hive data warehouse software project built on top of Apache Hadoop for providing data query and analysis.
ArticleVideo Book This article was published as a part of the DataScience Blogathon. Introduction MongoDB is a free open-source No-SQL document database. The post How To Create An Aggregation Pipeline In MongoDB appeared first on Analytics Vidhya.
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in datascience and dataengineering. Data Lakes : It supports MS Azure Blob Storage. pipelines, Azure Data Bricks.
Rockets legacy datascience environment challenges Rockets previous datascience solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided DataScience Experience development tools.
This article was published as a part of the DataScience Blogathon Overview When Apache Cassandra first came out, it included a command-line interface for dealing with thrift. Manipulation of data in this manner was inconvenient and caused knowing the API’s intricacies.
The field of datascience is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for datascience hires peak.
This article was published as a part of the DataScience Blogathon. Introduction When creating data pipelines, Software Engineers and DataEngineers frequently work with databases using Database Management Systems like PostgreSQL.
This article was published as a part of the DataScience Blogathon Introduction Let’s look at a practical example of how to make SQL queries to a MySQL server from Python code: CREATE, SELECT, UPDATE, JOIN, etc. Most applications interact with data in some form. Therefore, programming languages ??(Python
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
Datascience bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of datascience. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content