This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon A datascientist’s ability to extract value from data is closely related to how well-developed a company’s data storage and processing infrastructure is.
For datascientists, this shift has opened up a global market of remote data science jobs, with top employers now prioritizing skills that allow remote professionals to thrive. Here’s everything you need to know to land a remote data science job, from advanced role insights to tips on making yourself an unbeatable candidate.
This article was published as a part of the Data Science Blogathon. Introduction Datascientists, engineers, and BI analysts often need to analyze, process, or query different data sources.
Top 10 Professions in Data Science: Below, we provide a list of the top data science careers along with their corresponding salary ranges: 1. DataScientistDatascientists are responsible for designing and implementing data models, analyzing and interpreting data, and communicating insights to stakeholders.
Learn the basics of dataengineering to improve your ML modelsPhoto by Mike Benna on Unsplash It is not news that developing Machine Learning algorithms requires data, often a lot of data. Collecting this data is not trivial, in fact, it is one of the most relevant and difficult parts of the entire workflow.
Navigating the World of DataEngineering: A Beginner’s Guide. A GLIMPSE OF DATAENGINEERING ❤ IMAGE SOURCE: BY AUTHOR Data or data? No matter how you read or pronounce it, data always tells you a story directly or indirectly. Dataengineering can be interpreted as learning the moral of the story.
This is part of the Full Stack DataScientist blog series. Building end-to-end data science solutions means developing data collection, feature engineering, model building and model serving processes. It’s overwhelming at first, so let’s just focus on the main part development as the ‘DataEngineer’ — DAGS.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
So why using IaC for Cloud Data Infrastructures? For Data Warehouse Systems that often require powerful (and expensive) computing resources, this level of control can translate into significant cost savings. This brings reliability to dataETL (Extract, Transform, Load) processes, query performances, and other critical data operations.
It allows datascientists to build models that can automate specific tasks. we have Databricks which is an open-source, next-generation data management platform. It focuses on two aspects of data management: ETL (extract-transform-load) and data lifecycle management.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines.
This also led to a backlog of data that needed to be ingested. Steep learning curve for datascientists: Many of Rockets datascientists did not have experience with Spark, which had a more nuanced programming model compared to other popular ML solutions like scikit-learn.
Unfolding the difference between dataengineer, datascientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a datascientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a datascientist.
ABOUT EVENTUAL Eventual is a data platform that helps datascientists and engineers build data applications across ETL, analytics and ML/AI. OUR PRODUCT IS OPEN-SOURCE AND USED AT ENTERPRISE SCALE Our distributed dataengine Daft [link] is open-sourced and runs on 800k CPU cores daily.
Team Building the right data science team is complex. With a range of role types available, how do you find the perfect balance of DataScientists , DataEngineers and Data Analysts to include in your team? The DataEngineer Not everyone working on a data science project is a datascientist.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Accordingly, one of the most demanding roles is that of Azure DataEngineer Jobs that you might be interested in. The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. How to Become an Azure DataEngineer?
Working as a DataScientist — Expectation versus Reality! 11 key differences in 2023 Photo by Jan Tinneberg on Unsplash Working in Data Science and Machine Learning (ML) professions can be a lot different from the expectation of it. As I was working on these projects, I knew I wanted to work as a DataScientist once I graduate.
Dataengineering is a rapidly growing field that designs and develops systems that process and manage large amounts of data. There are various architectural design patterns in dataengineering that are used to solve different data-related problems.
DataEngineering : Building and maintaining data pipelines, ETL (Extract, Transform, Load) processes, and data warehousing. Networking Opportunities The popularity of bootcamps has attracted a diverse audience, including aspiring datascientists and professionals transitioning into data science roles.
Enrich dataengineering skills by building problem-solving ability with real-world projects, teaming with peers, participating in coding challenges, and more. Globally several organizations are hiring dataengineers to extract, process and analyze information, which is available in the vast volumes of data sets.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Dataengineers use data warehouses, data lakes, and analytics tools to load, transform, clean, and aggregate data. Big Data Architect.
Engineering teams, in particular, can quickly get overwhelmed by the abundance of information pertaining to competition data, new product and service releases, market developments, and industry trends, resulting in information anxiety. Explosive data growth can be too much to handle. Can’t get to the data.
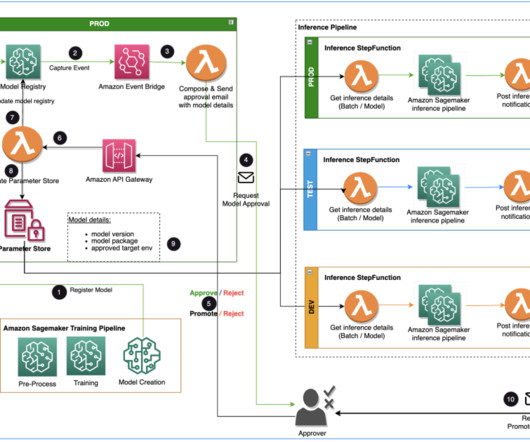
Specialist DataEngineering at Merck, and Prabakaran Mathaiyan, Sr. ML Engineer at Tiger Analytics. An ML model registered by a datascientist needs an approver to review and approve before it is used for an inference pipeline and in the next environment level (test, UAT, or production).
DataScientists and ML Engineers typically write lots and lots of code. From writing code for doing exploratory analysis, experimentation code for modeling, ETLs for creating training datasets, Airflow (or similar) code to generate DAGs, REST APIs, streaming jobs, monitoring jobs, etc.
Your dataengineers, analysts, and datascientists are working to find answers to your questions and deliver insights to help you make decisions. Click to learn more about author Helena Schwenk.
Db2 Warehouse fully supports open formats such as Parquet, Avro, ORC and Iceberg table format to share data and extract new insights across teams without duplication or additional extract, transform, load (ETL). This allows you to scale all analytics and AI workloads across the enterprise with trusted data.
With sports (and everything else) cancelled, this datascientist decided to take on COVID-19 | A Winner’s Interview with David Mezzetti When his hobbies went on hiatus, Kaggler David Mezzetti made fighting COVID-19 his mission. In August 2019, Data Works was acquired and Dave worked to ensure a successful transition.
Amazon SageMaker Studio provides a fully managed solution for datascientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow datascientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
There’s no need for developers or analysts to manually adjust table schemas or modify ETL (Extract, Transform, Load) processes whenever the source data structure changes. Time Efficiency – The automated schema detection and evolution features contribute to faster data availability.
Collaboration – Datascientists each worked on their own local Jupyter notebooks to create and train ML models. They lacked an effective method for sharing and collaborating with other datascientists. This has helped the datascientist team to create and test pipelines at a much faster pace.
Set specific, measurable targets Data science goals to “increase sales” lack the clarity needed to evaluate success and secure ongoing funding. Audit existing data assets Inventory internal datasets, ETL capabilities, past analytical initiatives, and available skill sets. Complexity limits accessibility and value creation.
Data preprocessing ensures the removal of incorrect, incomplete, and inaccurate data from datasets, leading to the creation of accurate and useful datasets for analysis ( Image Credit ) Data completeness One of the primary requirements for data preprocessing is ensuring that the dataset is complete, with minimal missing values.
Integrating helpful metadata into user workflows gives all people, from datascientists to analysts , the context they need to use data more effectively. The Benefits and Challenges of the Modern Data Stack Why are such integrations needed? Before a data user leverages any data set, they need to be able to learn about it.
It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A data warehouse. Data ingestion/integration services. Reverse ETL tools. Data orchestration tools. A Note on the Shift from ETL to ELT. Datascientists.
There are many factors, but here, we’d like to hone in on the activities that a data science team engages in. More Speakers and Sessions Announced for the 2024 DataEngineering Summit Ranging from experimentation platforms to enhanced ETL models and more, here are some more sessions coming to the 2024 DataEngineering Summit.
The Lineage & Dataflow API is a good example enabling customers to add ETL transformation logic to the lineage graph. The Open Connector Framework SDK enables engineers to custom-build data source connectors , which are indexed by Alation. Open Data Quality Initiative.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Dataengineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
Collaboration : Ensuring that all teams involved in the project, including datascientists, engineers, and operations teams, are working together effectively. Two DataScientists: Responsible for setting up the ML models training and experimentation pipelines. We primarily used ETL services offered by AWS.
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities.
Snowpark Use Cases Data Science Streamlining data preparation and pre-processing: Snowpark’s Python, Java, and Scala libraries allow datascientists to use familiar tools for wrangling and cleaning data directly within Snowflake, eliminating the need for separate ETL pipelines and reducing context switching.
Like so many data teams out there, we need to maximize our throughput whilst ensuring quality. Jason: I’m curious to learn about your modern data stack. Adrian Lievano, Senior DataScientist, Alation : Most of our data sources are connected and extracted using Fivetran , and then transported to raw storage in Snowflake.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content