This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Meet Tajinder, a seasoned Senior DataScientist and MLEngineer who has excelled in the rapidly evolving field of data science. Tajinder’s passion for unraveling hidden patterns in complex datasets has driven impactful outcomes, transforming raw data into actionable intelligence.
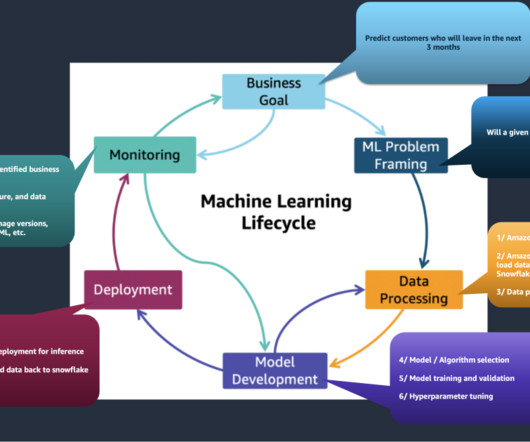
This post is part of an ongoing series about governing the machine learning (ML) lifecycle at scale. This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. The data mesh is a modern approach to data management that decentralizes data ownership and treats data as a product.
For datascientists, this shift has opened up a global market of remote data science jobs, with top employers now prioritizing skills that allow remote professionals to thrive. Here’s everything you need to know to land a remote data science job, from advanced role insights to tips on making yourself an unbeatable candidate.
If you’ve found yourself asking, “How to become a datascientist?” In this detailed guide, we’re going to navigate the exciting realm of data science, a field that blends statistics, technology, and strategic thinking into a powerhouse of innovation and insights. What is a datascientist?
How much machine learning really is in MLEngineering? There are so many different data- and machine-learning-related jobs. But what actually are the differences between a DataEngineer, DataScientist, MLEngineer, Research Engineer, Research Scientist, or an Applied Scientist?!
If you want to stay ahead in the world of big data, AI, and data-driven decision-making, Big Data & AI World 2025 is the perfect event to explore the latest innovations, strategies, and real-world applications. Thats where Data + AI Summit 2025 comes in!
As the Internet of Things (IoT) continues to revolutionize industries and shape the future, datascientists play a crucial role in unlocking its full potential. A recent article on Analytics Insight explores the critical aspect of dataengineering for IoT applications.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries.
Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing datascientists and MLengineers to build, train, and deploy ML models using geospatial data. Identify areas of interest We begin by illustrating how SageMaker can be applied to analyze geospatial data at a global scale.
In an increasingly digital and rapidly changing world, BMW Group’s business and product development strategies rely heavily on data-driven decision-making. With that, the need for datascientists and machine learning (ML) engineers has grown significantly.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Let’s learn about the services we will use to make this happen.
The growth of the AI and Machine Learning (ML) industry has continued to grow at a rapid rate over recent years. Hidden Technical Debt in Machine Learning Systems More money, more problems — Rise of too many ML tools 2012 vs 2023 — Source: Matt Turck People often believe that money is the solution to a problem.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
Machine learning (ML) is the technology that automates tasks and provides insights. It allows datascientists to build models that can automate specific tasks. It comes in many forms, with a range of tools and platforms designed to make working with ML more efficient. It also has ML algorithms built into the platform.
Learn the basics of dataengineering to improve your ML modelsPhoto by Mike Benna on Unsplash It is not news that developing Machine Learning algorithms requires data, often a lot of data. Collecting this data is not trivial, in fact, it is one of the most relevant and difficult parts of the entire workflow.
Do you need help to move your organization’s Machine Learning (ML) journey from pilot to production? Most executives think ML can apply to any business decision, but on average only half of the ML projects make it to production. Challenges Customers may face several challenges when implementing machine learning (ML) solutions.
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. This also led to a backlog of data that needed to be ingested.
In these scenarios, as you start to embrace generative AI, large language models (LLMs) and machine learning (ML) technologies as a core part of your business, you may be looking for options to take advantage of AWS AI and ML capabilities outside of AWS in a multicloud environment.
Team Building the right data science team is complex. With a range of role types available, how do you find the perfect balance of DataScientists , DataEngineers and Data Analysts to include in your team? The DataEngineer Not everyone working on a data science project is a datascientist.
The machine learning systems developed by Machine Learning Engineers are crucial components used across various big data jobs in the data processing pipeline. Additionally, Machine Learning Engineers are proficient in implementing AI or ML algorithms. Is MLengineering a stressful job?
Machine learning (ML) engineer Potential pay range – US$82,000 to 160,000/yr Machine learning engineers are the bridge between data science and engineering. Integrating the knowledge of data science with engineering skills, they can design, build, and deploy machine learning (ML) models.
ABOUT EVENTUAL Eventual is a data platform that helps datascientists and engineers build data applications across ETL, analytics and ML/AI. OUR PRODUCT IS OPEN-SOURCE AND USED AT ENTERPRISE SCALE Our distributed dataengine Daft [link] is open-sourced and runs on 800k CPU cores daily.
Amazon SageMaker Feature Store provides an end-to-end solution to automate feature engineering for machine learning (ML). For many ML use cases, raw data like log files, sensor readings, or transaction records need to be transformed into meaningful features that are optimized for model training. SageMaker Studio set up.
The role of a datascientist is in demand and 2023 will be no exception. To get a better grip on those changes we reviewed over 25,000 datascientist job descriptions from that past year to find out what employers are looking for in 2023. Data Science Of course, a datascientist should know data science!
Businesses are increasingly using machine learning (ML) to make near-real-time decisions, such as placing an ad, assigning a driver, recommending a product, or even dynamically pricing products and services. As a result, some enterprises have spent millions of dollars inventing their own proprietary infrastructure for feature management.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
This post, part of the Governing the ML lifecycle at scale series ( Part 1 , Part 2 , Part 3 ), explains how to set up and govern a multi-account ML platform that addresses these challenges. An enterprise might have the following roles involved in the ML lifecycles. This ML platform provides several key benefits.
Key Takeaways Business Analytics targets historical insights; Data Science excels in prediction and automation. Business Analytics requires business acumen; Data Science demands technical expertise in coding and ML. With added skills, professionals can shift between Business Analytics and Data Science. Masters or Ph.D.
Working as a DataScientist — Expectation versus Reality! 11 key differences in 2023 Photo by Jan Tinneberg on Unsplash Working in Data Science and Machine Learning (ML) professions can be a lot different from the expectation of it. In courses/projects, it is common to have data available.
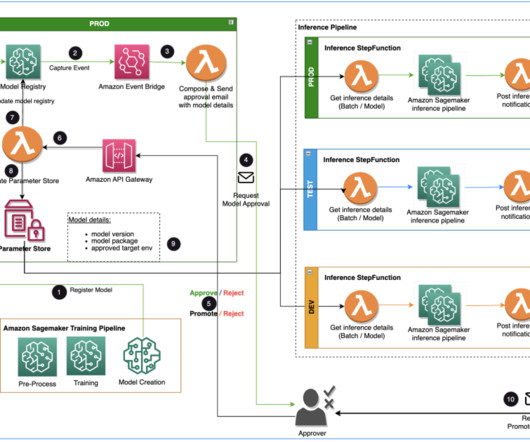
Specialist DataEngineering at Merck, and Prabakaran Mathaiyan, Sr. MLEngineer at Tiger Analytics. The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of software development. This post is co-written with Jayadeep Pabbisetty, Sr.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Dataengineers use data warehouses, data lakes, and analytics tools to load, transform, clean, and aggregate data.
Why datascientists and analysts ought to have a working knowledge of software engineering in Python? There are several good reasons why datascientists and analysts, particularly Python, need a solid grounding in software engineering ideas and techniques.
Accordingly, one of the most demanding roles is that of Azure DataEngineer Jobs that you might be interested in. The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. How to Become an Azure DataEngineer?
Showcasing the industry’s most innovative use of AI, this global event offers you the opportunity to learn from DataRobot datascientists—as well as AI pioneers from retailers like Shiseido Japan Co., DataRobot AIX has purpose-built content for business leads, datascientists, and IT leaders. Breakouts for Business Leads.
Data science and dataengineering are incredibly resource intensive. By using cloud computing, you can easily address a lot of these issues, as many data science cloud options have databases on the cloud that you can access without needing to tinker with your hardware.
It 10x’s our world-class AI platform by dramatically increasing the flexibility of DataRobot for datascientists who love to code and share their expertise across teams of all skill levels. Data Exploration, Visualization, and First-Class Integration. Put simply, Zepl helps make DataRobot easily customizable. Stay tuned.
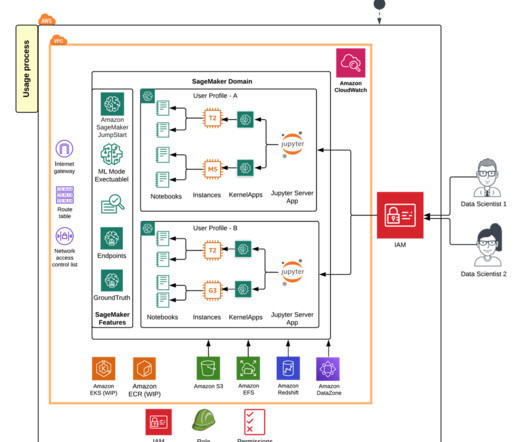
Launched in 2019, Amazon SageMaker Studio provides one place for all end-to-end machine learning (ML) workflows, from data preparation, building and experimentation, training, hosting, and monitoring. About the Authors Mair Hasco is an AI/ML Specialist for Amazon SageMaker Studio. Get started on SageMaker Studio here.
Since 2018, our team has been developing a variety of ML models to enable betting products for NFL and NCAA football. Our datascientists train the model in Python using tools like PyTorch and save the model as PyTorch scripts. They use the DJL PyTorch engine to initialize the model predictor.
Amazon SageMaker Feature Store is a fully managed, purpose-built repository to store, share, and manage features for machine learning (ML) models. Features are inputs to ML models used during training and inference. Their task is to construct and oversee efficient data pipelines.
As Artificial Intelligence (AI) and Machine Learning (ML) technologies have become mainstream, many enterprises have been successful in building critical business applications powered by ML models at scale in production.
SambaSafety’s team of datascientists has developed complex and propriety modeling solutions designed to accurately quantify this risk profile. With AWS CI/CD and AI/ML products, SambaSafety’s data science team didn’t have to change their existing development workflow to take advantage of continuous model training and inference.
With organizations increasingly investing in machine learning (ML), ML adoption has become an integral part of business transformation strategies. However, implementing ML into production comes with various considerations, notably being able to navigate the world of AI safely, strategically, and responsibly.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content