This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
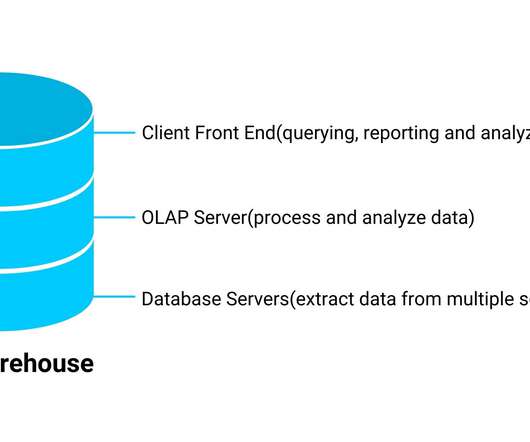
Introduction All data mining repositories have a similar purpose: to onboard data for reporting intents, analysis purposes, and delivering insights. By their definition, the types of data it stores and how it can be accessible to users differ.
Aspiring and experienced DataEngineers alike can benefit from a curated list of books covering essential concepts and practical techniques. These 10 Best DataEngineering Books for beginners encompass a range of topics, from foundational principles to advanced data processing methods. What is DataEngineering?
The field of data science is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for data science hires peak. Their insights must be in line with real-world goals.
This data mesh strategy combined with the end consumers of your data cloud enables your business to scale effectively, securely, and reliably without sacrificing speed-to-market. What is a Cloud DataWarehouse? For example, most datawarehouse workloads peak during certain times, say during business hours.
By automating the integration of all Fabric workloads into OneLake, Microsoft eliminates the need for developers, analysts, and business users to create their own data silos. This approach not only improves performance by eliminating the need for separate datawarehouses but also results in substantial cost savings for customers.
Engineering teams, in particular, can quickly get overwhelmed by the abundance of information pertaining to competition data, new product and service releases, market developments, and industry trends, resulting in information anxiety. Explosive data growth can be too much to handle. Can’t get to the data.
Governance can — and should — be the responsibility of every data user, though how that’s achieved will depend on the role within the organization. This article will focus on how dataengineers can improve their approach to data governance. How can dataengineers address these challenges directly?
Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. It promotes a disciplined approach to data modeling, making it easier to ensure data quality and consistency across the ML pipelines. The following figure shows schema definition and model which reference it.
However, with the evolution of the internet, the definition of transaction has broadened to include all types of digital interactions and engagements between a business and its customers. The core definition of transactions in the context of OLTP systems remains primarily focused on economic or financial activities.
The datawarehouse and analytical data stores moved to the cloud and disaggregated into the data mesh. Today, the brightest minds in our industry are targeting the massive proliferation of data volumes and the accompanying but hard-to-find value locked within all that data. Architectures became fabrics.
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse.
Data analysts and engineers use dbt to transform, test, and document data in the cloud datawarehouse. Making this data visible in the data catalog will let data teams share their work, support re-use, and empower everyone to better understand and trust data.
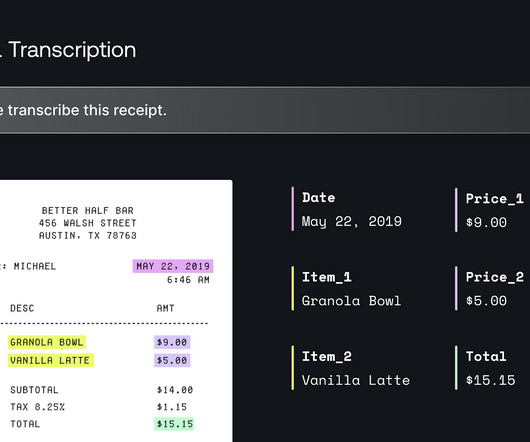
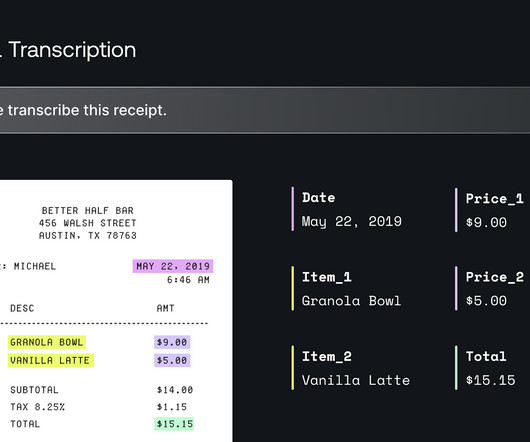
Well according to Brij Kishore Pandey, it stands for Extract, Transform, Load and is a fundamental process in dataengineering, ensuring data moves efficiently from raw sources to structured storage for analysis. The stepsinclude: Extraction : Data is collected from multiple sources (databases, APIs, flatfiles).
With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based datawarehouse.
“At Kestra Financial, we need confidence that we’re delivering trustworthy, reliable data to everyone making data-driven decisions,” said Justin Mikhalevsky, Vice President of Data Governance & Analytics, Kestra Financial. “We Robust data governance starts with understanding the definition of data.
Data mesh forgoes technology edicts and instead argues for “decentralized data ownership” and the need to treat “data as a product”. Gartner on Data Fabric. Moreover, data catalogs play a central role in both data fabric and data mesh. We’ll dig into this definition in a bit. Design concept.
This process introduces considerable time and effort into the overall data ingestion workflow, delaying the availability of data to end consumers. Fortunately, the client has opted for Snowflake Data Cloud as their target datawarehouse. This is incredibly useful for both DataEngineers and Data Scientists.
It is a process for moving and managing data from various sources to a central datawarehouse. This process ensures that data is accurate, consistent, and usable for analysis and reporting. Definition and Explanation of the ETL Process ETL is a data integration method that combines data from multiple sources.
These range from data sources , including SaaS applications like Salesforce; ELT like Fivetran; cloud datawarehouses like Snowflake; and data science and BI tools like Tableau. This expansive map of tools constitutes today’s modern data stack. But different users have different needs.
Data Quality Monitoring implements quality checks in operational data processes to ensure that the data meets pre-defined standards and business rules. This results in poor credibility and data consistency after some time, leading businesses to mistrust the data pipelines and processes.
Now, a single customer might use multiple emails or phone numbers, but matching in this way provides a precise definition that could significantly reduce or even eliminate the risk of accidentally associating the actions of multiple customers with one identity.
One of the easiest ways for Snowflake to achieve this is to have analytics solutions query their datawarehouse in real-time (also known as DirectQuery). These additional tools in the Power Platform open up more possible consumption of Snowflake data than there would be otherwise.
Moreover, DBMS systems manage data through functionalities such as indexing, which enhances retrieval speed by logically organising data. Best DataEngineering and SQL Books for Beginners. Advanced SQL Tips and Tricks for Data Analysts. This uniqueness enables efficient data management and retrieval processes.
Unsupervised learning has shown a big potential in large language models but high-quality labelled data remains the gold standard for AI systems to be accurate and aligned with human language and understanding. LabelBox LabelBox is an AI-powered dataengine platform that supports text annotation along with other data types.
Unsupervised learning has shown a big potential in large language models but high-quality labelled data remains the gold standard for AI systems to be accurate and aligned with human language and understanding. LabelBox LabelBox is an AI-powered dataengine platform that supports text annotation along with other data types.
Without partitioning, daily data activities will cost your company a fortune and a moment will come where the cost advantage of GCP BigQuery becomes questionable. By keeping the data in cloud storage instead of native BigQuery tables, you can reduce your storage costs while maintaining the ability to query the data.
While data fabric takes a product-and-tech-centric approach, data mesh takes a completely different perspective. Data mesh inverts the common model of having a centralized team (such as a dataengineering team), who manage and transform data for wider consumption. But why is such an inversion needed?
Our activities mostly revolved around: 1 Identifying data sources 2 Collecting & Integrating data 3 Developing Analytical/ML models 4 Integrating the above into a cloud environment 5 Leveraging the cloud to automate the above processes 6 Making the deployment robust & scalable Who was involved in the project?
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines Data Lake und eines DataWarehouse kombiniert. Organisationen können je nach ihren spezifischen Bedürfnissen und Anforderungen zwischen einem DataWarehouse und einem Data Lakehouse wählen.
All this raw data goes into your persistent stage. Then, if you later refine your definition of what constitutes an “engaged” customer, having the raw data in persistent staging allows for easy reprocessing of historical data with the new logic. Are people binge-watching your original series?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content