This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
When needed, the system can access an ODAP datawarehouse to retrieve additional information. Document management Documents are securely stored in Amazon S3, and when new documents are added, a Lambda function processes them into chunks.
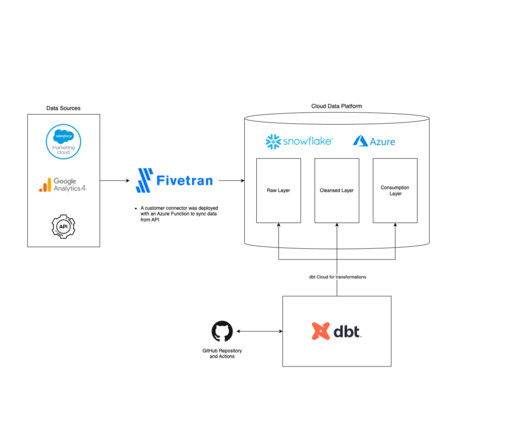
Fivetran is used by businesses to centralize data from various sources into a single, comprehensive datawarehouse. It allows organizations to easily connect their disparate data sources without having to manage any infrastructure. This frees up our dataengineers to do what they do best.
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the data pipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a datawarehouse.
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into datawarehouses or databases for analysis. Loading The transformed data is loaded into the target destination, such as a datawarehouse.
To start using OpenSearch for anomaly detection you first must index your data into OpenSearch , from there you can enable anomaly detection in OpenSearch Dashboards. To learn more, see the documentation. To learn more, see the documentation. To learn more, see the documentation.
By 2025, global data volumes are expected to reach 181 zettabytes, according to IDC. To harness this data effectively, businesses rely on ETL (Extract, Transform, Load) tools to extract, transform, and load data into centralized systems like datawarehouses.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. How to scale AL and ML with built-in governance A fit-for-purpose data store built on an open lakehouse architecture allows you to scale AI and ML while providing built-in governance tools.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse.
Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly. It promotes a disciplined approach to data modeling, making it easier to ensure data quality and consistency across the ML pipelines. Saurabh Gupta is a Principal Engineer at Zeta Global.
By incorporating metadata into the data model, users can easily discover, understand, and interpret the data stored in the lake. With the amounts of data involved, this can be crucial to utilizing a data lake effectively. However, this can be time-consuming and prone to human error, leading to misinformation.
Precisely conducted a study that found that within enterprises, data scientists spend 80% of their time cleaning, integrating and preparing data , dealing with many formats, including documents, images, and videos. Overall placing emphasis on establishing a trusted and integrated data platform for AI.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. While they require task-specific labeled data for fine tuning, they also offer clients the best cost performance trade-off for non-generative use cases.
With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based datawarehouse.
On the other hand, OLAP systems use a multidimensional database, which is created from multiple relational databases and enables complex queries involving multiple data facts from current and historical data. An OLAP database may also be organized as a datawarehouse.
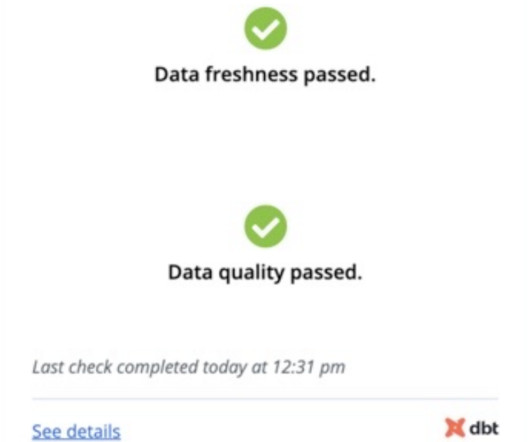
Hosted Doc Site for Documentation One of the most powerful features of dbt can be the documentation you generate. This documentation can give different users insight into where data came from, what the profile of the data is, what the SQL looked like, and the DAG to know where the data is being used.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
How to Get Started with Matillion Data Productivity Cloud That looks unbelievable, but trust me, you can get started with Matillion Data Productivity Cloud from 0 to start your first job in around 5 minutes. Creating Your Account First things first, let’s create your Matillion account in order to deploy your Data Productivity Cloud.
Typically, this data is scattered across Excel files on business users’ desktops. Typically, this data is scattered across Excel files on business users’ desktops. They usually operate outside any data governance structure; often, no documentation exists outside the user’s mind.
Alation is pleased to be named a dbt Metrics Partner and to announce the start of a partnership with dbt, which will bring dbt data into the Alation data catalog. In the modern data stack, dbt is a key tool to make data ready for analysis. Data Transformation in the Modern Data Stack.
For example, a new data scientist who is curious about which customers are most likely to be repeat buyers, might search for customer data only to discover an article documenting a previous project that answered their exact question. Modern data catalogs also facilitate data quality checks.
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This data transformation tool enables data analysts and engineers to transform, test and documentdata in the cloud datawarehouse. But what does this mean from a practitioner perspective?
Understanding Fivetran Fivetran is a user-friendly, code-free platform enabling customers to easily synchronize their data by automating extraction, transformation, and loading from many sources. Fivetran automates the time-consuming steps of the ELT process so your dataengineers can focus on more impactful projects.
Through Impact Analysis, users can determine if a problem occurred with data upstream, and locate the impacted data downstream. With robust data lineage, dataengineers can find and fix issues fast and prevent them from recurring. Similarly, analysts gain a clear view of how data is created.
Also Read: Top 10 Data Science tools for 2024. It is a process for moving and managing data from various sources to a central datawarehouse. This process ensures that data is accurate, consistent, and usable for analysis and reporting. This process helps organisations manage large volumes of data efficiently.
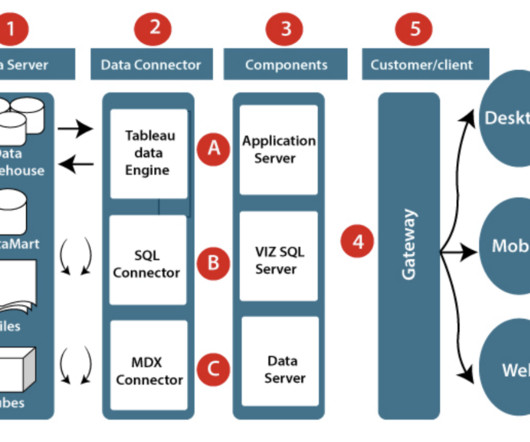
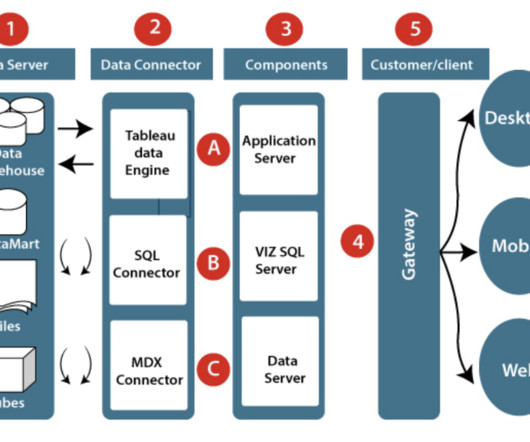
Tableau Architecture Let’s understand a bit more about Tableau architecture which will help in better knowledge of where Tableau data is stored. Data Server : These are basically the databases, files, and datawarehouses to which any dashboard connects for the rendering of visuals. Hyper is a compiling query engine.
Tableau Architecture Let’s understand a bit more about Tableau architecture which will help in better knowledge of where Tableau data is stored. Data Server : These are basically the databases, files, and datawarehouses to which any dashboard connects for the rendering of visuals. Hyper is a compiling query engine.
With the Open Data Quality Initiative, Alation introduces an Open Data Quality Framework (ODQF), which includes a starter kit for data quality partners. This kit offers an open DQ API, developer documentation, onboarding, integration best practices, and co-marketing support.
Founded in 2014 by three leading cloud engineers, phData focuses on solving real-world dataengineering, operations, and advanced analytics problems with the best cloud platforms and products. Over the years, one of our primary focuses became Snowflake and migrating customers to this leading cloud data platform.
Data Vault - Data Lifecycle Architecturally, let’s understand the data lifecycle in the data vault into the following layers, which play a key role in choosing the right pattern and tools to implement. Data Acquisition: Extracting data from source systems and making it accessible.
Text Data Labeling Techniques Text data labeling is a nuanced process, where success lies in finding the right balance between human expertise and automatic efficiency for each specific use case. Improve your data quality for better AI Easily curate and annotate your vision, audio, and documentdata with a single platform.
A data mesh is a conceptual architectural approach for managing data in large organizations. Traditional data management approaches often involve centralizing data in a datawarehouse or data lake, leading to challenges like data silos, data ownership issues, and data access and processing bottlenecks.
Alation: And you likely had plenty of data even before the acquisition. The challenge wasn’t that we had nothing to document. Data from any other brands we acquired or built were based on the same schema, so an engineering team looking for data would say, “We know about where it is, but we don’t know exactly where it is.”
The approach has shown exceptional results in specialized domains such as legal document classification and medical text analysis, where nuanced interpretation is crucial [ reference ]. Documentation Requirements Documentation serves both as a historical record and a living guide.
With Snowflake, data stewards have a choice to leverage Snowflake’s governance policies. First, stewards are dependent on datawarehouse admins to provide information and to create and edit enforcement policies in Snowflake. Alation’s data lineage helps organizations to secure their data in the Snowflake Data Cloud.
Data governance is traditionally applied to structured data assets that are most often found in databases and information systems. This blog focuses on governing spreadsheets that contain data, information, and metadata, and must themselves be governed. There are others that consider spreadsheets to be trouble.
One of the easiest ways for Snowflake to achieve this is to have analytics solutions query their datawarehouse in real-time (also known as DirectQuery). For more information on composite models, check out Microsoft’s official documentation. This ensures the maximum amount of Snowflake consumption possible.
Without partitioning, daily data activities will cost your company a fortune and a moment will come where the cost advantage of GCP BigQuery becomes questionable. There are other options you can place, and as usual, I suggest you to reference the official documentation to learn more.
Data Preparation: Cleaning, transforming, and preparing data for analysis and modelling. Collaborating with Teams: Working with dataengineers, analysts, and stakeholders to ensure data solutions meet business needs. Start by setting up your own Azure account and experimenting with various services.
Data Modeling, dbt has gradually emerged as a powerful tool that largely simplifies the process of building and handling data pipelines. dbt is an open-source command-line tool that allows dataengineers to transform, test, and document the data into one single hub which follows the best practices of software engineering.
Data Quality Monitoring implements quality checks in operational data processes to ensure that the data meets pre-defined standards and business rules. This results in poor credibility and data consistency after some time, leading businesses to mistrust the data pipelines and processes.
Another benefit of deterministic matching is that the process to build these identities is relatively simple, and tools your teams might already use, like SQL and dbt , can efficiently manage this process within your cloud datawarehouse. However, targeted web advertising may only require linkage to a browser or device ID.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content