This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports. In the menu bar on the left, select Workspaces.
Unabhängiges und Nachhaltiges DataEngineering Die Arbeit hinter Process Mining kann man sich wie einen Eisberg vorstellen. Der andere Teil des Process Minings ist jedoch noch viel wesentlicher, denn es handelt sich dabei um das Fundament der Analyse: Die Datenmodellierung des Event Logs. Celonis Process Mining) übertragen.
Dabei darf gerne in Erinnerung gerufen werden, dass Process Mining im Kern eine Graphenanalyse ist, die ein Event Log in Graphen umwandelt, Aktivitäten (Events) stellen dabei die Knoten und die Prozesszeiten die Kanten dar, zumindest ist das grundsätzlich so. Es handelt sich dabei also um eine Analysemethodik und nicht um ein Tool.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Dataengineering is a hot topic in the AI industry right now. And as data’s complexity and volume grow, its importance across industries will only become more noticeable. But what exactly do dataengineers do? So let’s do a quick overview of the job of dataengineer, and maybe you might find a new interest.
Dataengineering is a rapidly growing field that designs and develops systems that process and manage large amounts of data. There are various architectural design patterns in dataengineering that are used to solve different data-related problems.
Dataengineering has become an integral part of the modern tech landscape, driving advancements and efficiencies across industries. So let’s explore the world of open-source tools for dataengineers, shedding light on how these resources are shaping the future of data handling, processing, and visualization.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
We couldn’t be more excited to announce the first sessions for our second annual DataEngineering Summit , co-located with ODSC East this April. Join us for 2 days of talks and panels from leading experts and dataengineering pioneers. Is Gen AI A DataEngineering or Software Engineering Problem?
Dataengineering in healthcare is taking a giant leap forward with rapid industrial development. However, data collection and analysis have been commonplace in the healthcare sector for ages. DataEngineering in day-to-day hospital administration can help with better decision-making and patient diagnosis/prognosis.
The new VistaPrint personalized product recommendation system Figure 1 As seen in Figure 1, the steps in how VistaPrint provides personalized product recommendations with their new cloud-native architecture are: Aggregate historical data in a datawarehouse. Transform the data to create Amazon Personalize training data.
By automating the integration of all Fabric workloads into OneLake, Microsoft eliminates the need for developers, analysts, and business users to create their own data silos. This approach not only improves performance by eliminating the need for separate datawarehouses but also results in substantial cost savings for customers.
Apache Kafka and Apache Flink working together Anyone who is familiar with the stream processing ecosystem is familiar with Apache Kafka: the de-facto enterprise standard for open-source event streaming. Apache Kafka streams get data to where it needs to go, but these capabilities are not maximized when Apache Kafka is deployed in isolation.
In this episode, James Serra, author of “Deciphering Data Architectures: Choosing Between a Modern DataWarehouse, Data Fabric, Data Lakehouse, and Data Mesh” joins us to discuss his book and dive into the current state and possible future of data architectures. Interested in attending an ODSC event?
What is an online transaction processing database: Indexed data sets are used for rapid querying in OLTP systems Regular & incremental backups for data safety Frequent backups are necessary to ensure that data is protected in the event of a system failure or other issue.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
Curated foundation models, such as those created by IBM or Microsoft, help enterprises scale and accelerate the use and impact of the most advanced AI capabilities using trusted data. In addition to natural language, models are trained on various modalities, such as code, time-series, tabular, geospatial and IT eventsdata.
For years, marketing teams across industries have turned to implementing traditional Customer Data Platforms (CDPs) as separate systems purpose-built to unlock growth with first-party data. Event Tracking : Capturing behavioral events such as page views, add-to-cart, signup, purchase, subscription, etc.
Data scientists will typically perform data analytics when collecting, cleaning and evaluating data. By analyzing datasets, data scientists can better understand their potential use in an algorithm or machine learning model. Diagnostic analytics: Diagnostic analytics helps pinpoint the reason an event occurred.
Must Read Blogs: Exploring the Power of DataWarehouse Functionality. Data Lakes Vs. DataWarehouse: Its significance and relevance in the data world. Exploring Differences: Database vs DataWarehouse. It is commonly used in datawarehouses for business analytics and reporting.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
ODSC Highlights Announcing the Keynote and Featured Speakers for ODSC East 2024 The keynotes and featured speakers for ODSC East 2024 have won numerous awards, authored books and widely cited papers, and shaped the future of data science and AI with their research. Learn more about them here!
Through Impact Analysis, users can determine if a problem occurred with data upstream, and locate the impacted data downstream. With robust data lineage, dataengineers can find and fix issues fast and prevent them from recurring. Similarly, analysts gain a clear view of how data is created.
Methods that allow our customer data models to be as dynamic and flexible as the customers they represent. In this guide, we will explore concepts like transitional modeling for customer profiles, the power of event logs for customer behavior, persistent staging for raw customer data, real-time customer data capture, and much more.
Kaggle Grandmaster Jiwei Liu and NVIDIA experts will answer all your questions about the upcoming event. HPCC Systems : Built for dataengineers, HPCC provides an open-source platform designed for fast and efficient big data processing.
Founded in 2014 by three leading cloud engineers, phData focuses on solving real-world dataengineering, operations, and advanced analytics problems with the best cloud platforms and products. Over the years, one of our primary focuses became Snowflake and migrating customers to this leading cloud data platform.
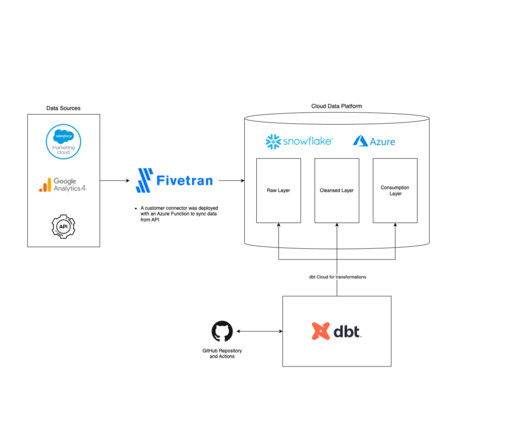
Understanding Fivetran Fivetran is a user-friendly, code-free platform enabling customers to easily synchronize their data by automating extraction, transformation, and loading from many sources. Fivetran automates the time-consuming steps of the ELT process so your dataengineers can focus on more impactful projects.
KPIs for predictive maintenance include: Equipment downtime Mean time between failures (MTBF) Mean time to repair (MTTR) All of these KPIs can be measured by tracking the amount of time that equipment is not in use due to maintenance or repair, as well as the frequency and duration of maintenance and repair events.
Andreas Kohlmaier, Head of DataEngineering at Munich Re 1. --> Ron Powell, independent analyst and industry expert for the BeyeNETWORK and executive producer of The World Transformed FastForward Series, interviews Andreas Kohlmaier, Head of DataEngineering at Munich Re.
Few actors in the modern data stack have inspired the enthusiasm and fervent support as dbt. This data transformation tool enables data analysts and engineers to transform, test and document data in the cloud datawarehouse. But what does this mean from a practitioner perspective?
Data Quality Monitoring implements quality checks in operational data processes to ensure that the data meets pre-defined standards and business rules. This results in poor credibility and data consistency after some time, leading businesses to mistrust the data pipelines and processes.
Data Preparation: Cleaning, transforming, and preparing data for analysis and modelling. Collaborating with Teams: Working with dataengineers, analysts, and stakeholders to ensure data solutions meet business needs.
Data Quality Dimensions Data quality dimensions are the criteria that are used to evaluate and measure the quality of data. These include the following: Accuracy indicates how correctly data reflects the real-world entities or events it represents. Datafold is a tool focused on data observability and quality.
Our activities mostly revolved around: 1 Identifying data sources 2 Collecting & Integrating data 3 Developing Analytical/ML models 4 Integrating the above into a cloud environment 5 Leveraging the cloud to automate the above processes 6 Making the deployment robust & scalable Who was involved in the project?
Modern low-code/no-code ETL tools allow dataengineers and analysts to build pipelines seamlessly using a drag-and-drop and configure approach with minimal coding. Matillion ETL for Snowflake is an ELT/ETL tool that allows for the ingestion, transformation, and building of analytics for data in the Snowflake AI Data Cloud.
Lambda enables serverless, event-driven data processing tasks, allowing for real-time transformations and calculations as data arrives. Step Functions complements this by orchestrating complex workflows, coordinating multiple Lambda functions, and managing error handling for sophisticated data processing pipelines.
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. Thats where dataengineering tools come in!
At the same time, global health awareness and investments in clinical research have increased as a result of motivations by major events like the COVID-19 pandemic. Instead, a core component of decentralized clinical trials is a secure, scalable data infrastructure with strong data analytics capabilities.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content