This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data science boot camps are intensive, short-term programs that teach students the skills they need to become data scientists. These programs typically cover topics such as datawrangling, statistical inference, machine learning, and Python programming.
Big data analytics is evergreen, and as more companies use big data it only makes sense that practitioners are interested in analyzing data in-house. Deeplearning is a fairly common sibling of machine learning, just going a bit more in-depth, so ML practitioners most often still work with deeplearning.
First, there’s a need for preparing the data, aka dataengineering basics. Machine learning practitioners are often working with data at the beginning and during the full stack of things, so they see a lot of workflow/pipeline development, datawrangling, and data preparation.
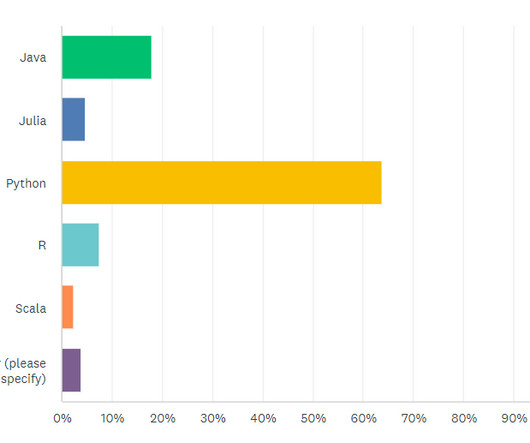
As you’ll see in the next section, data scientists will be expected to know at least one programming language, with Python, R, and SQL being the leaders. This will lead to algorithm development for any machine or deeplearning processes. Java’s still being used frequently as many frameworks run on JVM (Java Virtual Machine).
Past courses have included An Introduction to DataWrangling with SQL Programming with Data: Python and Pandas Introduction to Machine Learning Introduction to Math for Data Science Introduction to Data Visualization During the conference itself, you’ll have your choice of any of ODSC East’s training sessions, workshops, and talks.
Build Classification and Regression Models with Spark on AWS Suman Debnath | Principal Developer Advocate, DataEngineering | Amazon Web Services This immersive session will cover optimizing PySpark and best practices for Spark MLlib. Free and paid passes are available now–register here.
Past courses have included An Introduction to DataWrangling with SQL Programming with Data: Python and Pandas Introduction to Machine Learning Introduction to Math for Data Science Introduction to Data Visualization During the conference itself, you’ll have your choice of any of ODSC West’s training sessions, workshops, and talks.
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. DataWrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
Requires a solid understanding of statistics, programming, data manipulation, and machine learning algorithms. Offers career paths as data scientists, data analysts, machine learningengineers, business analysts, and dataengineers, among others.
Knowledge in these areas enables prompt engineers to understand the mechanics of language models and how to apply them effectively. DataEngineering A job role in its own right, this involves managing the modern data stack and structuring data and workflow pipelines — crucial for preparing data for use in training and running AI models.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content