This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
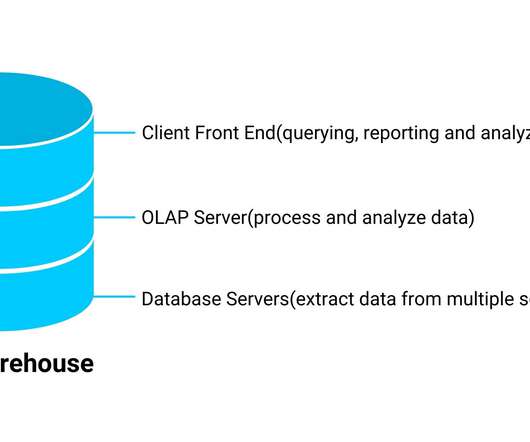
Image Source: GitHub Table of Contents What is DataEngineering? Components of DataEngineering Object Storage Object Storage MinIO Install Object Storage MinIO Data Lake with Buckets Demo Data Lake Management Conclusion References What is DataEngineering?
Introduction All data mining repositories have a similar purpose: to onboard data for reporting intents, analysis purposes, and delivering insights. By their definition, the types of data it stores and how it can be accessible to users differ.
Aspiring and experienced DataEngineers alike can benefit from a curated list of books covering essential concepts and practical techniques. These 10 Best DataEngineering Books for beginners encompass a range of topics, from foundational principles to advanced data processing methods. What is DataEngineering?
Additionally, imagine being a practitioner, such as a data scientist, dataengineer, or machine learning engineer, who will have the daunting task of learning how to use a multitude of different tools. Source: IBM Cloud Pak for Data MLOps teams often struggle when it comes to integrating into CI/CD pipelines.
Other users Some other users you may encounter include: Dataengineers , if the data platform is not particularly separate from the ML platform. Analytics engineers and data analysts , if you need to integrate third-party business intelligence tools and the data platform, is not separate. Allegro.io
In essence, DataOps is a practice that helps organizations manage and govern data more effectively. However, there is a lot more to know about DataOps, as it has its own definition, principles, benefits, and applications in real-life companies today – which we will cover in this article! What Is DataOps? It’s a Team Sport.
I did my research about this idea and hoped my insight could inspire more data science practitioners. Definition of a full-stack data scientist The sibling relationship between data science and software development has led to the borrowing of many concepts from the software development domain into data science practice.
Governance can — and should — be the responsibility of every data user, though how that’s achieved will depend on the role within the organization. This article will focus on how dataengineers can improve their approach to data governance. How can dataengineers address these challenges directly?
The vector field should be represented as an array of numbers (BSON int32, int64, or double data types only). Query the vector data store You can query the vector data store using the Vector Search aggregation pipeline. It uses the Vector Search index and performs a semantic search on the vector data store.
Introducing knowledge graphs and LLMs Before we understand the impact and methods of integrating KGs and LLMs, let’s visit the definition of the two concepts. They are a visual web of information that focuses on connecting factual data in a meaningful manner. What are knowledge graphs (KGs)?
The creation of this data model requires the data connection to the source system (e.g. SAP ERP), the extraction of the data and, above all, the data modeling for the event log. So whenever you hear that Process Mining can prepare RPA definitions you can expect that Task Mining is the real deal.
Engineering teams, in particular, can quickly get overwhelmed by the abundance of information pertaining to competition data, new product and service releases, market developments, and industry trends, resulting in information anxiety. Explosive data growth can be too much to handle. Unable to properly govern data.
To get a better grip on those changes we reviewed over 25,000 data scientist job descriptions from that past year to find out what employers are looking for in 2023. Much of what we found was to be expected, though there were definitely a few surprises. You’ll see specific tools in the next section.
It’s overwhelming at first, so let’s just focus on the main part development as the ‘DataEngineer’ — DAGS. link] We finally have the definition of the DAG. Let’s look at the joke_collector_task definition now. Take a quick look at the architecture diagram below, from the Airflow documentation.
Instead of relying on a central data management team, this architecture empowers your subject matter experts and domain owners to curate, maintain, and share data products that impact their domain. This complexity requires a mature dataengineering team to design, implement, and manage it effectively.
Von Big Data über Data Science zu AI Einer der Gründe, warum Big Data insbesondere nach der Euphorie wieder aus der Diskussion verschwand, war der Leitspruch “S**t in, s**t out” und die Kernaussage, dass Daten in großen Mengen nicht viel wert seien, wenn die Datenqualität nicht stimme.
Aber Moment mal, was ist eigentlich ein Data Lakehouse? Der Artikel beginnt mit einer Definition, was ein Lakehouse ist, gibt einen kurzen geschichtlichen Abriss, wie das Lakehouse entstanden ist und zeigt, warum und wie man ein Data Lakehouse aufbauen sollte. Databricks ist auf AWS, Azure und Google Cloud Platform verfügbar.
- a beginner question Let’s start with the basic thing if I talk about the formal definition of Data Science so it’s like “Data science encompasses preparing data for analysis, including cleansing, aggregating, and manipulating the data to perform advanced data analysis” , is the definition enough explanation of data science?
Moreover, it provides a straightforward way to track data lineage, so we can foresee which datasets will be affected by newly introduced changes. The following figure shows schema definition and model which reference it. Saurabh Gupta is a Principal Engineer at Zeta Global.
To create a UDN, we’ll need a node definition that defines how the node should function and templates for how the object will be created and run. Node Definition The Node Definition defines the UI elements and other shared attributes available to that Node Type.
In most cases, there is no definitive right or wrong answer, he says. Each one represents a specific skill: exploratory data analysis and visualization, data storytelling, statistics, programming, experimentation, modeling, machine learning operations, and dataengineering.
A data management solution can help you make better business decisions by giving you access to the right information at the right time. Dataengineering services can analyze large amounts of data and identify trends that would otherwise be missed. A big data management solution helps your business run more efficiently.
For example, Tableau dataengineers want a single source of truth to help avoid creating inconsistencies in data sets, while line-of-business users are concerned with how to access the latest data for trusted analysis when they need it most. Data certification: Duplicated data can create inconsistency and trust issues.
Making this data visible in the data catalog will let data teams share their work, support re-use, and empower everyone to better understand and trust data. Data Transformation in the Modern Data Stack. Dataengineering plays a critical role in distributing data to a wide audience.
For example, Tableau dataengineers want a single source of truth to help avoid creating inconsistencies in data sets, while line-of-business users are concerned with how to access the latest data for trusted analysis when they need it most. Data certification: Duplicated data can create inconsistency and trust issues.
When we take the Microsoft Fabric price into account, bringing all these features together under a pay-as-you-go model is definitely a great opportunity for users. You can try this platform that can handle all your data-related tasks without even paying the Microsoft Fabric price.
However, with the evolution of the internet, the definition of transaction has broadened to include all types of digital interactions and engagements between a business and its customers. The core definition of transactions in the context of OLTP systems remains primarily focused on economic or financial activities.
Yes, these things are part of any job in technology, and they can definitely be super fun, but you have to be strategic about how you spend your time and always be aware of your value proposition. Secondly, to be a successful ML engineer in the real world, you cannot just understand the technology; you must understand the business.
Data mesh says architectures should be decentralized because there are inherent problems with centralized architectures. For example, when we centralize, all the focus goes on the dataengineers. But there are only so many dataengineers available in the market today; there’s a big skills shortage.
Thus, MLOps is the intersection of Machine Learning, DevOps, and DataEngineering (Figure 1). A better definition would make use of the directed acyclic graph (DAG) since it may not be a linear process. Figure 1: Venn diagram showing the relationship among the MLOps-related fields [Wikipedia].
The downside of this approach is that we want small bins to have a high definition picture of the distribution, but small bins mean fewer data points per bin and our distribution, especially the tails, may be poorly estimated and irregular. Outside of work, he enjoys cycling in Los Angeles and hiking in the Sierras.
Data mesh forgoes technology edicts and instead argues for “decentralized data ownership” and the need to treat “data as a product”. Gartner on Data Fabric. Moreover, data catalogs play a central role in both data fabric and data mesh. We’ll dig into this definition in a bit. Design concept.
Problem definition Traditionally, the recommendation service was mainly provided by identifying the relationship between products and providing products that were highly relevant to the product selected by the customer. You can also check out the NCF and MLOps configuration for hands-on practice on our GitHub repo (Korean).
This is incredibly useful for both DataEngineers and Data Scientists. During the development phase, Dataengineers can quickly use INFER_SCHEMA to scan text files and generate DDLs. Once the table is created, the data load is as simple as using the COPY command.
Reichental describes data governance as the overarching layer that empowers people to manage data well ; as such, it is focused on roles & responsibilities, policies, definitions, metrics, and the lifecycle of the data. In this way, data governance is the business or process side. Communication is essential.
“At Kestra Financial, we need confidence that we’re delivering trustworthy, reliable data to everyone making data-driven decisions,” said Justin Mikhalevsky, Vice President of Data Governance & Analytics, Kestra Financial. “We Robust data governance starts with understanding the definition of data.
These estimates are based on data collected from Glassdoor’s proprietary Total Pay Estimate model and reflect the midpoint of the salary ranges. The “Most Likely Range” represents the values that fall within the 25th and 75th percentile of all pay data available for this role. How dataengineers tame Big Data?
Introduction to Containers for Data Science/DataEngineering Michael A Fudge | Professor of Practice, MSIS Program Director | Syracuse University’s iSchool In this hands-on session, you’ll learn how to leverage the benefits of containers for DS and dataengineering workflows.
Invited by dataengineer and WiBD mentor Srabasti Banerjee, Deborah addressed the topic for the learners of the joint program between Women in Big Data and DataCamp in January. Deborah Sgro began by explaining what career development is, with a brief definition.
The Evolving AI Development Lifecycle Despite the revolutionary capabilities of LLMs, the core development lifecycle established by traditional natural language processing remains essential: Plan, Prepare Data, Engineer Model, Evaluate, Deploy, Operate, and Monitor.
SageMaker Studio allows data scientists, ML engineers, and dataengineers to prepare data, build, train, and deploy ML models on one web interface. The following excerpt from the code shows the model definition and the train function: # define network class Net(nn.Module): def __init__(self): super(Net, self).__init__()
Transition to the Data Cloud With multiple ways to interact with your company’s data, Snowflake has built a common access point that handles data lake access, data warehouse access, and data sharing access into one protocol. What kinds of Workloads Does Snowflake Handle?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content