This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. For Project name , enter a name (for example, demo).
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of dataengineering and data science team’s bandwidth and data preparation activities.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Mini-Bootcamp and VIP Pass holders will have access to four live virtual sessions on data science fundamentals. Confirmed sessions include: An Introduction to Data Wrangling with SQL with Sheamus McGovern, Software Architect, DataEngineer, and AI expert Programming with Data: Python and Pandas with Daniel Gerlanc, Sr.
First, there’s a need for preparing the data, aka dataengineering basics. Machine learning practitioners are often working with data at the beginning and during the full stack of things, so they see a lot of workflow/pipeline development, data wrangling, and data preparation.
Big data analytics is evergreen, and as more companies use big data it only makes sense that practitioners are interested in analyzing data in-house. Lastly, dataengineering is popular as the engineering side of AI is needed to make the most out of data, such as collection, cleaning, extracting, and so on.
You’ll also have the chance to learn about the tradeoffs of building AI from scratch or buying it from a third party at the AI Expo and Demo Hall, where Microsoft, neo4j, HPCC, and many more will be showcasing their products and services.
Krishna Maheshwari from NeuroBlade highlighted their collaboration with the Velox community, introducing NeuroBlade’s SPU (SQL Processing Unit) and its transformative impact on Velox’s computational speed and efficiency. He shared insights into Velox Wave and Accelerators, showcasing its potential for acceleration.
This functionality eliminates the need for manual schema adjustments, streamlining the data ingestion process and ensuring quicker access to data for their consumers. As you can see in the above demo, it is incredibly simple to use INFER_SCHEMA and SCHEMA EVOLUTION features to speed up data ingestion into Snowflake.
While a data analyst isn’t expected to know more nuanced skills like deep learning or NLP, a data analyst should know basic data science, machine learning algorithms, automation, and data mining as additional techniques to help further analytics. Cloud Services: Google Cloud Platform, AWS, Azure.
Snowpark, offered by the Snowflake AI Data Cloud , consists of libraries and runtimes that enable secure deployment and processing of non-SQL code, such as Python, Java, and Scala. Move inside sfguide-data-engineering-with-snowpark-python ( cd sfguide-data-engineering-with-snowpark-python ).
I did not realize as Chris demoed his prototype PhD system that it would become Tableau Desktop , a product used today by millions of people around the world to see and understand data, including in Fortune 500 companies, classrooms, and nonprofit organizations. Another key data computation moment was Hyper in v10.5 (Jan
For a short demo on Snowpark, be sure to check out the video below. Utilizing Streamlit as a Front-End At this point, we have all of our data processing, model training, inference, and model evaluation steps set up with Snowpark. What was once a SQL-based data warehousing tool is now so much more.
When you make it easier to work with events, other users like analysts and dataengineers can start gaining real-time insights and work with datasets when it matters most. As a result, you reduce the skills barrier and increase your speed of data processing by preventing important information from getting stuck in a data warehouse.
Prime examples of this in the data catalog include: Trust Flags — Allow the data community to endorse, warn, and deprecate data to signal whether data can or can’t be used. Data Profiling — Statistics such as min, max, mean, and null can be applied to certain columns to understand its shape. Book a demo today.
These include Snowflake-provided system DMFs and user-defined DMFs that can regularly check the integrity and state of data in a table or view. Currently, the functions support SQL syntax, accept one or more arguments, and must always return a NUMBER value. We will demo one of them, duplicate count, in our use cases below.
Alation is excited to unveil Alation Connected Sheets , a new product that brings trusted, fresh data directly to spreadsheet users. Now, “spreadsheet jockeys” can pull the most current, compliant data directly from a range of cloud sources, without having to know SQL or depend on a data team to deliver it.
I did not realize as Chris demoed his prototype PhD system that it would become Tableau Desktop , a product used today by millions of people around the world to see and understand data, including in Fortune 500 companies, classrooms, and nonprofit organizations. Another key data computation moment was Hyper in v10.5 (Jan
Request a live demo or start a proof of concept with Amazon RDS for Db2 Db2 Warehouse SaaS on AWS The cloud-native Db2 Warehouse fulfills your price and performance objectives for mission-critical operational analytics, business intelligence (BI) and mixed workloads. . Netezza
These combinations of Python code and SQL play a crucial role but can be challenging to keep them robust for their entire lifetime. Applying software design principles to dataengineering Dive into the integration of concrete software design principles and patterns within the realm of dataengineering.
Organizations need to ensure that data use adheres to policies (both organizational and regulatory). In an ideal world, you’d get compliance guidance before and as you use the data. Imagine writing a SQL query or using a BI dashboard with flags & warnings on compliance best practice within your natural workflow.
Generative AI can be used to automate the data modeling process by generating entity-relationship diagrams or other types of data models and assist in UI design process by generating wireframes or high-fidelity mockups. GPT-4 Data Pipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. This provides end-to-end support for dataengineering and MLOps workflows.
By then I had converted that small Heights data dictionary to the Snowflake sources. But everything CURO was still on SQL. Will: CURO was primarily a Microsoft SQL house and still is in some ways. We did have an existing data warehouse solution, but it was so rarely used by outside teams, and I can’t even remember the name.
These include the following: Introduction to Data Science Introduction to Python SQL for Data Analysis Statistics Data Visualization with Tableau 5. Data Science Program for working professionals by Pickl.AI Another popular Data Science course for working professionals is offered by Pickl.AI.
But refreshing this analysis with the latest data was impossible… unless you were proficient in SQL or Python. We wanted to make it easy for anyone to pull data and self service without the technical know-how of the underlying database or data lake. We’ve got you covered: Join a self-guided demo.
An ML platform standardizes the technology stack for your data team around best practices to reduce incidental complexities with machine learning and better enable teams across projects and workflows. We ask this during product demos, user and support calls, and on our MLOps LIVE podcast. Dataengineers are mostly in charge of it.
One of the hardest things about MLOps today is that a lot of data scientists aren’t native software engineers, but it may be possible to lower the bar to software engineering. A lot of them are demos at that point, they’re still not products. There are lots of demos out there. Build something.
I switched from analytics to data science, then to machine learning, then to dataengineering, then to MLOps. For me, it was a little bit of a longer journey because I kind of had dataengineering and cloud engineering and DevOps engineering in between. Quite fun, quite chaotic at times.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







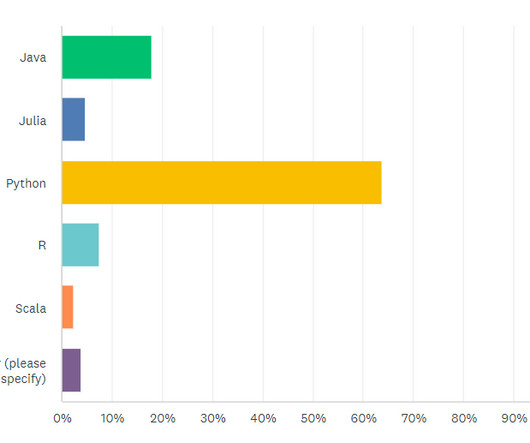





























Let's personalize your content