This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Conversely, clear, well-documented requirements set the foundation for a project that meets objectives, aligns with stakeholder expectations, and delivers measurable value. This blog post explores effective strategies for gathering requirements in your data project. Document and share meeting outcomes to ensure alignment.
This article was published as a part of the Data Science Blogathon. Introduction Apache CouchDB is an open-source, document-based NoSQL database developed by Apache Software Foundation and used by big companies like Apple, GenCorp Technologies, and Wells Fargo.
ArticleVideo Book This article was published as a part of the Data Science Blogathon. Introduction MongoDB is a free open-source No-SQL document database. The post How To Create An Aggregation Pipeline In MongoDB appeared first on Analytics Vidhya.
Navigating the World of DataEngineering: A Beginner’s Guide. A GLIMPSE OF DATAENGINEERING ❤ IMAGE SOURCE: BY AUTHOR Data or data? No matter how you read or pronounce it, data always tells you a story directly or indirectly. Dataengineering can be interpreted as learning the moral of the story.
It stores and retrieves large amounts of data, including photos, movies, documents, and other files, in a durable, accessible, and scalable manner. S3 provides a simple web interface for uploading and downloading data and a powerful set of APIs for developers to integrate S3.
Whether we are analyzing IoT data streams, managing scheduled events, processing document uploads, responding to database changes, etc. Azure functions allow developers […] The post How to Develop Serverless Code Using Azure Functions? appeared first on Analytics Vidhya.
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
Building a datalake for semi-structured data or json has always been challenging. Imagine if the json documents are streaming or continuously flowing from healthcare vendors then we need a robust modern architecture that can deal with such a high volume.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. For queries earning negative feedback, less than 1% involved answers or documentation deemed irrelevant to the original question.
In today’s data-intensive business landscape, organizations face the challenge of extracting valuable insights from diverse data sources scattered across their infrastructure. Create and load sample data In this post, we use two sample datasets: a total sales dataset CSV file and a sales target document in PDF format.
collect() Next, you can visualize the size of each document to understand the volume of data you’re processing. You can generate charts and visualize your data within your PySpark notebook cell using static visualization tools like matplotlib and seaborn. latest USER root RUN dnf install python3.11 python3.11-pip
This article was co-written by Lawrence Liu & Safwan Islam While the title ‘ Machine Learning Engineer ’ may sound more prestigious than ‘DataEngineer’ to some, the reality is that these roles share a significant overlap. Generative AI has unlocked the value of unstructured text-based data.
When needed, the system can access an ODAP data warehouse to retrieve additional information. Document management Documents are securely stored in Amazon S3, and when new documents are added, a Lambda function processes them into chunks.
In a recent episode of ODSCs Ai X Podcast , we were privileged to discuss this dynamic area with Tamer Khraisha, a seasoned financial dataengineer and author of the recent book Financial DataEngineering. The Role of AI in Financial Engineering AI is set to play a transformative role in financial dataengineering.
For Data Warehouse Systems that often require powerful (and expensive) computing resources, this level of control can translate into significant cost savings. Streamlined Collaboration Among Teams Data Warehouse Systems in the cloud often involve cross-functional teams — dataengineers, data scientists, and system administrators.
With Amazon SageMaker Canvas , you can create predictions for a number of different data types beyond just tabular or time series data without writing a single line of code. These capabilities include pre-trained models for image, text, and documentdata types. For a list of supported entities, refer to Entities.
Place them in a shared document. If your database administrator has the utmost confidence in the dataengineer and vice versa due to their continuous professional growth, then team members will be apt to interact and work more closely together. Present formal long- and short-term objectives and goals.
This post shows how to configure an Amazon Q Business custom connector and derive insights by creating a generative AI-powered conversation experience on AWS using Amazon Q Business while using access control lists (ACLs) to restrict access to documents based on user permissions. Who are the data stewards for my proprietary database sources?
This post dives into key steps for preparing data to build real-world ML systems. Data ingestion ensures that all relevant data is aggregated, documented, and traceable. Connecting to Data: Data may be scattered across formats, sources, and frequencies. Join thousands of data leaders on the AI newsletter.
Be sure to check out his talk, “ Building Data Contracts with Open Source Tools ,” there! Dataengineering is a critical function in all industries. However, dataengineering grows exponentially as the company grows, acquires, or merges with others. He is passionate about software engineering and all things data.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. As a DataEngineer he was involved in applying AI/ML to fraud detection and office automation.
To generate a useful response, the chat would need to reference different data sources, including the unstructured documents in your knowledge base (such as policy documentation about what causes an account suspension) and structured data such as transaction history and real-time account activity.
Trending DataEngineering Topics, the Top AI News from 2023, and Mapping Out the Top Open-Source LLM Frameworks 10 DataEngineering Topics and Trends You Need to Know in 2024 Let’s dive in and explore 10 dataengineering trends that are expected to shape the industry in 2024 and beyond.
These vary from challenges in getting data, maintaining various data forms and kinds, and coping with inconsistent data quality to the crucial need for current information. To train language models specifically for the banking industry, proprietary models like BloombergGPT have used their exclusive access to specialized data.
ABOUT EVENTUAL Eventual is a data platform that helps data scientists and engineers build data applications across ETL, analytics and ML/AI. OUR PRODUCT IS OPEN-SOURCE AND USED AT ENTERPRISE SCALE Our distributed dataengine Daft [link] is open-sourced and runs on 800k CPU cores daily.
You can use the Amazon Q Business ServiceNow Online data source connector to connect to the ServiceNow Online platform and index ServiceNow entities such as knowledge articles, Service Catalogs, and incident entries, along with the metadata and document access control lists (ACLs).
Key Metrics Annotation Time Reduction : Reduced document annotation time by 75%. Operational Speed : Accelerated data processing pipeline, achieving a 50% increase in data processing speed. Their primary challenges included: Data inconsistencies from non-standardized documentation.
The agent knowledge base stores Amazon Bedrock service documentation, while the cache knowledge base contains curated and verified question-answer pairs. For this example, you will ingest Amazon Bedrock documentation in the form of the User Guide PDF into the Amazon Bedrock knowledge base. This will be the primary dataset.
When data leaders move to the cloud, it’s easy to get caught up in the features and capabilities of various cloud services without thinking about the day-to-day workflow of data scientists and dataengineers.
It allows organizations to easily connect their disparate data sources without having to manage any infrastructure. Fivetran’s automated data movement platform simplifies the ETL (extract, transform, load) process by automating most of the time-consuming tasks of ETL that dataengineers would typically do.
Here’s how we created the transactions table in Snowflake in our Jupyter Notebook: Next, we generated the Customers table: These snippets illustrate creating a new table in Snowflake and then inserting data from a Pandas DataFrame. You can visit Snowflake’s API Documentation for more detailed examples and documentation.
This session will also include a practical demonstration of advanced techniques for different types of data. These solutions are based on Bayesian statistical models and include robust, privacy-preserving spatial models, probabilistic insights, and novel visualizations.
With data lineage, every object in the migrated system is mapped and dependencies are documented. MANTA customers have used data lineage to complete their migration projects 40% faster with 30% fewer resources. Trust and data governance Data governance isn’t new, especially in the financial world.
Just last month, Salesforce made a major acquisition to power its Agentforce platform—just one in a number of recent investments in unstructured data management providers. “Most data being generated every day is unstructured and presents the biggest new opportunity.” What should their next steps be?
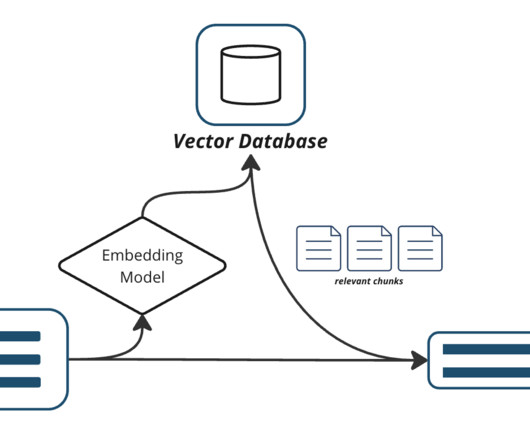
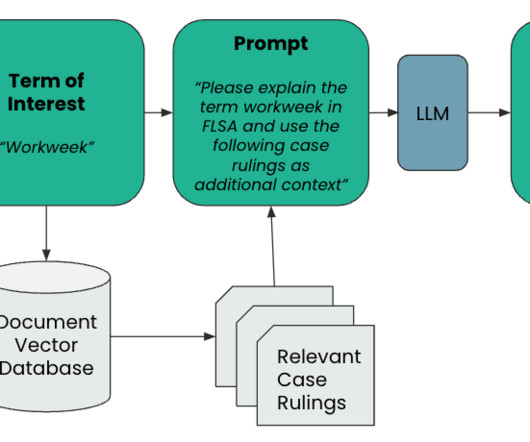
Consider the below diagram: Figure 1: HR Chatbot Pipeline with RAG Instead of just directly prompting the LLM , we provide our IT chatbot with our organization’s unique documentdata to consider before responding. Build a Knowledge Repository Start by gathering all the dynamic data sources your system needs.
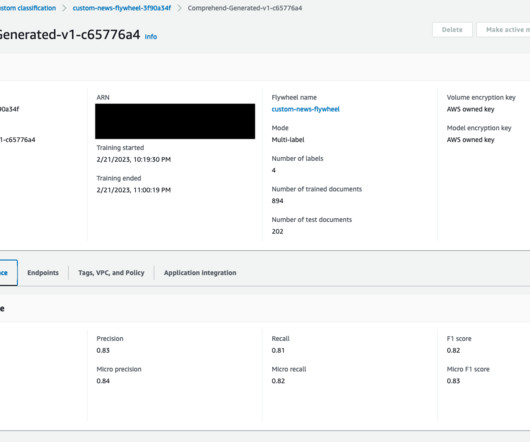
Solution overview Amazon Comprehend is a fully managed service that uses natural language processing (NLP) to extract insights about the content of documents. MLOps focuses on the intersection of data science and dataengineering in combination with existing DevOps practices to streamline model delivery across the ML development lifecycle.
This is how we came up with the DataEngine - an end-to-end solution for creating training-ready datasets and fast experimentation. Let’s explain how the DataEngine helps teams do just that. With DataEngine, ML teams can collect new data points to their storage of choice and add them into their Datasource.
To start using OpenSearch for anomaly detection you first must index your data into OpenSearch , from there you can enable anomaly detection in OpenSearch Dashboards. To learn more, see the documentation. To learn more, see the documentation. To learn more, see the documentation.
These new components separate and modularize the logic of data handling vs orchestrating. Instead, it automatically decides the chunk size based on the number of documents and other parameters. It defines an execution plan and prepares the data processing. The Slicer removes the need for manual splitting of huge files.
The question is sent through a retrieval-augmented generation (RAG) process, which finds similar documents. Each document holds an example question and information about it. The relevant documents are built as a prompt and sent to the LLM, which builds a SQL statement.
As we continue to innovate to increase data science productivity, we’re excited to announce the improved SageMaker Studio experience, which allows users to select the managed Integrated Development Environment (IDE) of their choice, while having access to the SageMaker Studio resources and tooling across the IDEs.
In August 2019, Data Works was acquired and Dave worked to ensure a successful transition. David: My technical background is in ETL, data extraction, dataengineering and data analytics. For each query, an embeddings query identifies the list of best matching documents.
Amazon Q can also help employees do more with the vast troves of data and information contained in their company’s documents, systems, and applications by answering questions, providing summaries, generating business intelligence (BI) dashboards and reports, and even generating applications that automate key tasks.
Transformers for Document Understanding Vaishali Balaji | Lead Data Scientist | Indium Software This session will introduce you to transformer models, their working mechanisms, and their applications.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content