This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction The article aims to empower you to create your projects. The post Download Financial Dataset Using Yahoo Finance in Python | A Complete Guide appeared first on Analytics Vidhya.
Lightning AI, the company behind PyTorch Lightning, with over 91 million downloads, announced the introduction of Lightning AI Studios, the culmination of 3 years of research into the next generation development paradigm for the age of AI.
It stores and retrieves large amounts of data, including photos, movies, documents, and other files, in a durable, accessible, and scalable manner. S3 provides a simple web interface for uploading and downloadingdata and a powerful set of APIs for developers to integrate S3.
It is designed to assist dataengineers in transforming, converting, and validating data in a simplified manner while ensuring accuracy and reliability. The Meltano CLI can efficiently handle complex dataengineering tasks, providing a user-friendly interface that simplifies the ELT process.
Variability also accounts for the inconsistent speed at which data is downloaded and stored across various systems, creating a unique experience for customers consuming the same data. [link] Veracity Veracity refers to the reliability of the data source. This is specific to the analyses being performed.
This post is a bitesize walk-through of the 2021 Executive Guide to Data Science and AI — a white paper packed with up-to-date advice for any CIO or CDO looking to deliver real value through data. Download the free, unabridged version here. Team Building the right data science team is complex.
When processing is triggered, endpoints are automatically initialized and model artifacts are downloaded from Amazon S3. Ian Thompson is a DataEngineer at Enterprise Knowledge, specializing in graph application development and data catalog solutions. The LLM endpoint is provisioned on ml.p4d.24xlarge
With the release of DataEngine, DagsHub has made it easier to create an active learning pipeline. In this tutorial, we will learn about DataEngine and see how we can use it to create an active learning pipeline for an image segmentation model using the COCO 1K. Feel free to get familiar with them.
Verify the data load by running a select statement: select count (*) from sales.total_sales_data; This should return 7,991 rows. The following screenshot shows the database table schema and the sample data in the table. She has experience across analytics, big data, ETL, cloud operations, and cloud infrastructure management.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of dataengineering and data science team’s bandwidth and data preparation activities.
The answer is data lineage. We’ve compiled six key reasons why financial organizations are turning to lineage platforms like MANTA to get control of their data. Download the Gartner® Market Guide for Active Metadata Management 1. Automated impact analysis In business, every decision contributes to the bottom line.
Data analysts sift through data and provide helpful reports and visualizations. You can think of this role as the first step on the way to a job as a data scientist or as a career path in of itself. DataEngineers. Each tool plays a different role in the data science process. How to get a Data Science Job.
With these hyperlinks, we can bypass traditional memory and storage-intensive methods of first downloading and subsequently processing images locally—a task made even more daunting by the size and scale of our dataset, spanning over 4 TB. Li Erran Li is the applied science manager at humain-in-the-loop services, AWS AI, Amazon.
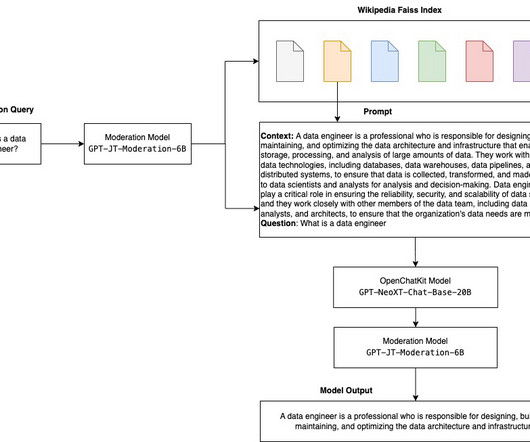
Solution overview The following steps are involved to build a chatbot using OpenChatKit models and deploy them on SageMaker: Download the chat base GPT-NeoXT-Chat-Base-20B model and package the model artifacts to be uploaded to Amazon Simple Storage Service (Amazon S3). Downloads are made concurrently to speed up the process.
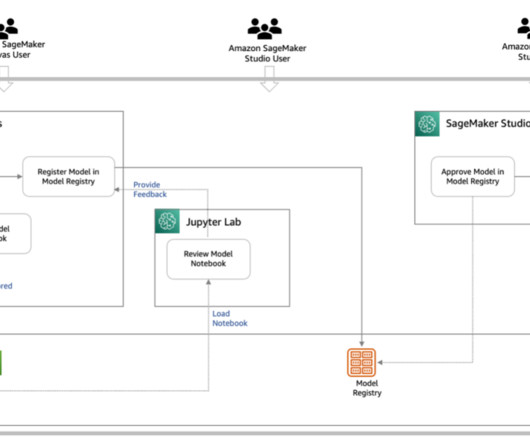
SageMaker Studio allows data scientists, ML engineers, and dataengineers to prepare data, build, train, and deploy ML models on one web interface. Our training script uses this location to download and prepare the training data, and then train the model. split('/',1) s3 = boto3.client("s3")
Extract and Transform Steps The extraction is a streaming job, downloading the data from the source APIs and directly persisting it into COS. All Chunks within the same folder share the same file prefix, allowing easy file access when transforming thedata.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. The generated images can also be downloaded as PNG or JPEG files.
In this post, we present a solution for the following types of users: Non-ML experts such as business analysts, dataengineers, or developers, who are domain experts and are interested in low-code no-code (LCNC) tools to guide them in preparing data for ML and building ML models.
Empowerment: Opening doors to new opportunities and advancing careers, especially for women in data. She highlighted various certification programs, including “Data Analyst,” “Data Scientist,” and “DataEngineer” under Career Certifications. She joined us to share her experience.
Of the organizations surveyed, 52 percent were seeking machine learning modelers and data scientists, 49 percent needed employees with a better understanding of business use cases, and 42 percent lacked people with dataengineering skills. Download Now. Process Deficiencies. “AI Your company can do that, too.
The integration eliminates the need for any coding or dataengineering to use the robust NLP models of Amazon Comprehend. You simply provide your text data and select from four commonly used capabilities: sentiment analysis, language detection, entities extraction, and personal information detection.
There are a lot of compelling reasons that Docker is becoming very valuable for data scientists and developers. If you are a Data Scientist or Big DataEngineer, you probably find the Data Science environment configuration painful. You can go to the Docker Hub and search Python environment.
The SDK provides a Python client to Planet’s APIs, as well as a no-code command line interface (CLI) solution, making it easy to incorporate satellite imagery and geospatial data into Python workflows. This example uses the Python client to identify and download imagery needed for the analysis. Shital Dhakal is a Sr.
Each step of the workflow is developed in a different notebook, which are then converted into independent notebook jobs steps and connected as a pipeline: Preprocessing – Download the public SST2 dataset from Amazon Simple Storage Service (Amazon S3) and create a CSV file for the notebook in Step 2 to run.
With ML-powered anomaly detection, customers can find outliers in their data without the need for manual analysis, custom development, or ML domain expertise. Using Amazon Glue Data Quality for anomaly detection Dataengineers and analysts can use AWS Glue Data Quality to measure and monitor their data.
You want to gather insights on this data and build an ML model to predict how new restaurants will be rated, but find it challenging to perform analytics on unstructured data. You encounter bottlenecks because you need to rely on dataengineering and data science teams to accomplish these goals.
To get the most out of the Snowflake Data Cloud , however, requires extensive knowledge of SQL and dedicated IT and dataengineering teams. Throughout the rest of this post, we will discuss how anybody can use KNIME’s database nodes to leverage the power of Snowflake’s engine. What option is there, then?
Luckily, I found several quantized versions and decided to go with the most downloaded one: bartowski/datagemma-rag-27b-it-GGUF. Here’s how I set up the Data Gemma model: Testing the Model With the model up and running, I wanted to see how well it performed. So, I had to get creative with quantized models.
Tweets inference data pipeline architecture Tweets Inference Data Pipeline Architecture (Screenshot by Author) The workflow performs the following tasks: Download Tweets Dataset: Download the tweets dataset from the S3 bucket. The task is to classify the tweets in batch mode. ?️Tweets
The no-code environment of SageMaker Canvas allows us to quickly prepare the data, engineer features, train an ML model, and deploy the model in an end-to-end workflow, without the need for coding. In this walkthrough, we will cover importing your data directly from Snowflake. You can download the dataset loans-part-1.csv
MLOps focuses on the intersection of data science and dataengineering in combination with existing DevOps practices to streamline model delivery across the ML development lifecycle. MLOps requires the integration of software development, operations, dataengineering, and data science. Choose Create job.
With over 50 connectors, an intuitive Chat for data prep interface, and petabyte support, SageMaker Canvas provides a scalable, low-code/no-code (LCNC) ML solution for handling real-world, enterprise use cases. Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data.
The Snowflake account is set up with a demo database and schema to load data. Sample CSV files (download files here ) Step 1: Load Sample CSV Files Into the Internal Stage Location Open the SQL worksheet and create a stage if it doesn’t exist. This is incredibly useful for both DataEngineers and Data Scientists.
In recent years, dataengineering teams working with the Snowflake Data Cloud platform have embraced the continuous integration/continuous delivery (CI/CD) software development process to develop data products and manage ETL/ELT workloads more efficiently. What Are the Benefits of CI/CD Pipeline For Snowflake?
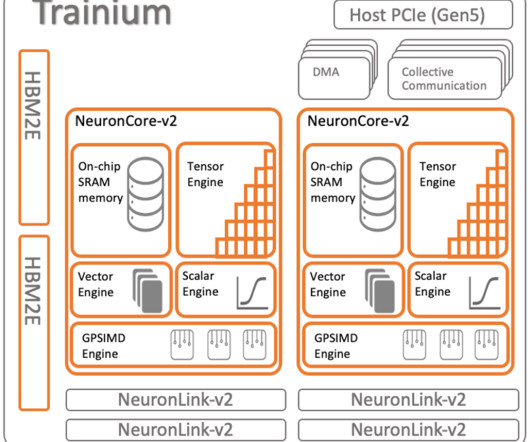
Trainium support for custom operators Trainium (and AWS Inferentia2) supports CustomOps in software through the Neuron SDK and accelerates them in hardware using the GPSIMD engine (General Purpose Single Instruction Multiple Dataengine). Download the sample code from the GitHub repository. format(loss.detach().to('cpu')))
Selecting a future-proof cloud database service with self-service capabilities is essential to automating data management and enabling data consumers, including developers, analysts, dataengineers, data scientists, and DBAs, to extract maximum value from the data and accelerate application development.
In this case, it detects the DJL PyTorch engine implementation, which will act as the bridge between the DJL API and the PyTorch Native. The engine then works to load the PyTorch Native. By default, it downloads the appropriate native binary based on your OS, CPU architecture, and CUDA version, making it almost effortless to use.
In order to scale responsible AI, organizations should implement these fundamental building blocks of data literacy: The data science and machine learning workflow: Learning about the steps required to create predictions from raw data helps stakeholders develop an understanding of AI project implementation. Download Now.
Plus, our co-located DataEngineering Summit allows you to dive deep into best practices in the essential fields of software engineering and dataengineering. Return on Investment Attending conferences and training can be a big budget item for any business, ODSC combines the best of both technical learning and community building.
You can watch the full video of this session here and download the slideshere. LLMs, while accelerating some processes, introduce complexities that require new tools and methodologies.
Thus, you can modify a model when needed without changing the pipeline that feeds into it — providing a data science improvement without any investment in dataengineering. . How to Thrive in the Age of Data Dominance. Download Now. 10 Keys to AI Success in 2022.
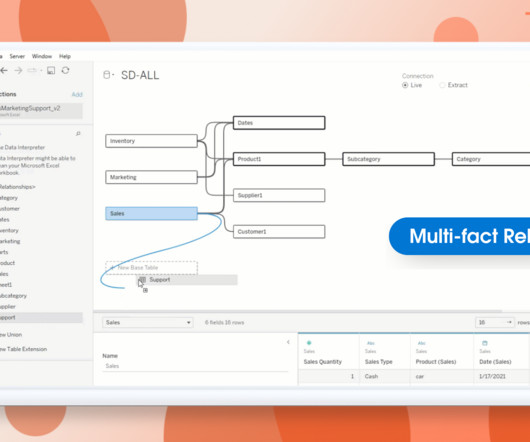
This data model enables you to explore correlations and answer more sophisticated analytical questions, such as how Marketing spend affects Sales, or how Spend actuals are tracking against Budget forecasts. Play around with the hypothetical retail store data model and explore analytics scenarios: Download the sample Tableau workbook.
At ODSC Europe 2024, you’ll find an unprecedented breadth and depth of content, with hands-on training sessions on the latest advances in Generative AI, LLMs, RAGs, Prompt Engineering, Machine Learning, Deep Learning, MLOps, DataEngineering, and much, much more. Plus, groups of 3 or more unlock our exclusive group discounts.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content