This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Overview of Typical Tasks and Responsibilities in Data Science As a Data Scientist, your daily tasks and responsibilities will encompass many activities. You will collect and clean data from multiple sources, ensuring it is suitable for analysis.
Integration also helps avoid duplication and redundancy of data, providing a comprehensive view of the information. Exploratorydataanalysis (EDA) Before preprocessing data, conducting exploratorydataanalysis is crucial to understand the dataset’s characteristics, identify patterns, detect outliers, and validate missing values.
This session will explore the current state of model training and execution at the edge, as well as acceleration alternatives in data augmentation and data curation strategies, containerized models and applications. AI/ML, Edge Computing and 5G in Action: Anatomy of an Intelligent Agriculture Architecture! Guillaume Moutier|Sr.
Vertex AI combines dataengineering, data science, and ML engineering into a single, cohesive environment, making it easier for data scientists and ML engineers to build, deploy, and manage ML models. Data Preparation Begin by ingesting and analysing your dataset.
For instance, feature engineering and exploratorydataanalysis (EDA) often require the use of visualization libraries like Matplotlib and Seaborn. In the data science industry, effective communication and collaboration play a crucial role. Communication is essential throughout the entire project lifecycle.
Who This Book Is For This book is for practitioners in charge of building, managing, maintaining, and operationalizing the ML process end to end: Data science / AI / ML leaders: Heads of Data Science, VPs of Advanced Analytics, AI Lead etc. Exploratorydataanalysis (EDA) and modeling.
They were more from a DataEngineering angle rather than ML. As the exam tests us on DataEngineering, AWS components and expects us to design solutions. DataEngineering and Machine Learning Implementation and Operations in AWS were my weak points. I will fail — That’s all. So I revised these very well.
The inferSchema parameter is set to True to infer the data types of the columns, and header is set to True to use the first row as headers. About the Author: Suman Debnath is a Principal Developer Advocate(DataEngineering) at Amazon Web Services, primarily focusing on DataEngineering, DataAnalysis and Machine Learning.
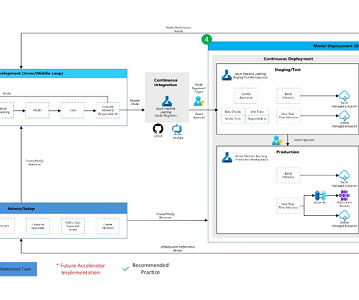
Data Estate: This element represents the organizational data estate, potential data sources, and targets for a data science project. DataEngineers would be the primary owners of this element of the MLOps v2 lifecycle. The Azure data platforms in this diagram are neither exhaustive nor prescriptive.
Data is presented to the personas that need access using a unified interface. For example, it can be used to answer questions such as “If patients have a propensity to have their wearables turned off and there is no clinical telemetry data available, can the likelihood that they are hospitalized still be accurately predicted?”
GPT-4 Data Pipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API. The data would be interesting to analyze. From DataEngineering to Prompt Engineering Prompt to do dataanalysis BI report generation/dataanalysis In BI/dataanalysis world, people usually need to query data (small/large).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content