This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Key Skills Proficiency in SQL is essential, along with experience in data visualization tools such as Tableau or Power BI. Strong analytical skills and the ability to work with large datasets are critical, as is familiarity with data modeling and ETL processes. This role builds a foundation for specialization.
ABOUT EVENTUAL Eventual is a data platform that helps data scientists and engineers build data applications across ETL, analytics and ML/AI. OUR PRODUCT IS OPEN-SOURCE AND USED AT ENTERPRISE SCALE Our distributed dataengine Daft [link] is open-sourced and runs on 800k CPU cores daily.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
Dataengineering is a rapidly growing field that designs and develops systems that process and manage large amounts of data. There are various architectural design patterns in dataengineering that are used to solve different data-related problems.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
In this representation, there is a separate store for events within the speed layer and another store for data loaded during batch processing. The serving layer acts as a mediator, enabling subsequent applications to access the data. This architectural concept relies on event streaming as the core element of data delivery.
If the question was Whats the schedule for AWS events in December?, AWS usually announces the dates for their upcoming # re:Invent event around 6-9 months in advance. Chaithanya Maisagoni is a Senior Software Development Engineer (AI/ML) in Amazons Worldwide Returns and ReCommerce organization.
Depending the organization situation and data strategy, on premises or hybrid approaches should be also considered. What makes the difference is a smart ETL design capturing the nature of process mining data. By utilizing these services, organizations can store large volumes of eventdata without incurring substantial expenses.
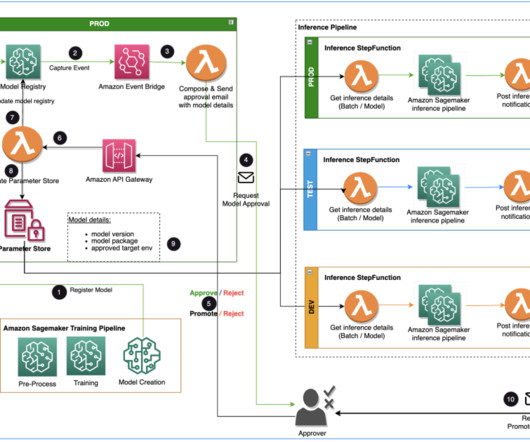
Specialist DataEngineering at Merck, and Prabakaran Mathaiyan, Sr. ML Engineer at Tiger Analytics. EventBridge monitors status change events to automatically take actions with simple rules. EventBridge monitors SageMaker for the model registration event and triggers an event rule that invokes a Lambda function.
Getting Started with AI in High-Risk Industries, How to Become a DataEngineer, and Query-Driven Data Modeling How To Get Started With Building AI in High-Risk Industries This guide will get you started building AI in your organization with ease, axing unnecessary jargon and fluff, so you can start today.
The solution consists of the following components: Data ingestion: Data is ingested into the data account from on-premises and external sources. Data access: Refined data is registered in the data accounts AWS Glue Data Catalog and exposed to other accounts via Lake Formation.
DataEngineering : Building and maintaining data pipelines, ETL (Extract, Transform, Load) processes, and data warehousing. Career Support Some bootcamps include job placement services like resume assistance, mock interviews, networking events, and partnerships with employers to aid in job placement.
By the end of the consulting engagement, the team had implemented the following architecture that effectively addressed the core requirements of the customer team, including: Code Sharing – SageMaker notebooks enable data scientists to experiment and share code with other team members.
ODSC Highlights Announcing the Keynote and Featured Speakers for ODSC East 2024 The keynotes and featured speakers for ODSC East 2024 have won numerous awards, authored books and widely cited papers, and shaped the future of data science and AI with their research. Learn more about them here!
Our activities mostly revolved around: 1 Identifying data sources 2 Collecting & Integrating data 3 Developing Analytical/ML models 4 Integrating the above into a cloud environment 5 Leveraging the cloud to automate the above processes 6 Making the deployment robust & scalable Who was involved in the project?
Finally, Tableau allows you to create custom territories using Tableau groups and overlay data with demographic information, giving you a comprehensive view of your data. You can set data quality warnings on data sources, databases, tables, flows, virtual connections, virtual connection tables, and columns.
May be useful Best Workflow and Pipeline Orchestration Tools: Machine Learning Guide Phase 1—Data pipeline: getting the house in order Once the dust was settled, we got the Architecture Canvas completed, and the plan was clear to everyone involved, the next step was to take a closer look at the architecture. What’s in the box?
To answer this question, I sat down with members of the Alation Data & Analytics team, Bindu, Adrian, and Idris. Some may be surprised to learn that this team uses dbt to serve up data to those who need it within the company. Julie : Over the years I have witnessed and worked with multiple variations of ETL/ELT architecture.
These conveniently combine key capabilities into unified services that facilitate the end-to-end lifecycle: Anaconda provides a local development environment bundling 700+ Python data packages. It enables accessing, transforming, analyzing, and visualizing data on a single workstation. So whats needed to smooth the path forward?
What Are the Best Third-Party Data Ingestion Tools for Snowflake? Fivetran Fivetran is a tool dedicated to replicating applications, databases, events, and files into a high-performance data warehouse, such as Snowflake. This may result in data inconsistency when UPDATE and DELETE operations are performed on the target database.
General Purpose Tools These tools help manage the unstructured data pipeline to varying degrees, with some encompassing data collection, storage, processing, analysis, and visualization. DagsHub's DataEngine DagsHub's DataEngine is a centralized platform for teams to manage and use their datasets effectively.
The most critical and impactful step you can take towards enterprise AI today is ensuring you have a solid data foundation built on the modern data stack with mature operational pipelines, including all your most critical operational data. This often involves software engineering, dataengineering, and system design skills.
Machine learning workflow of the Visual Search team Here’s a high-level overview of the typical ML workflow on the team: First, they would pull raw data from the producers (events, user actions in the app, etc.) These simple solutions focus more on the functionalities they know best at Brainly than on how the service works.
Modern low-code/no-code ETL tools allow dataengineers and analysts to build pipelines seamlessly using a drag-and-drop and configure approach with minimal coding. One such option is the availability of Python Components in Matillion ETL, which allows us to run Python code inside the Matillion instance. 30 minutes).
Methods that allow our customer data models to be as dynamic and flexible as the customers they represent. In this guide, we will explore concepts like transitional modeling for customer profiles, the power of event logs for customer behavior, persistent staging for raw customer data, real-time customer data capture, and much more.
In August 2019, Data Works was acquired and Dave worked to ensure a successful transition. David: My technical background is in ETL, data extraction, dataengineering and data analytics. What preprocessing and feature engineering did you do? David, what can you tell us about your background?
Change streams allow applications to access real-time data changes in MongoDB collections. They enable building reactive applications by providing a continuous stream of change events, such as insertions, updates, and deletions, which can be processed and acted upon immediately. How Does MongoDB Handle Large-Scale Data Migrations?
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. Thats where dataengineering tools come in!
30% Off ODSC East, Fan-Favorite Speakers, Foundation Models for Times Series, and ETL Pipeline Orchestration The ODSC East 2025 Schedule isLIVE! Explore the must-attend sessions and cutting-edge tracks designed to equip AI practitioners, data scientists, and engineers with the latest advancements in AI and machine learning.
Andy Bunn taking a huge jump with his fellow teammates, including Heather Coyle (to Andys right), at phDatas 2025 Kickoff Event in San Antonio. Matthew Miller Analytics Consultant As one of our Principal Consultants, Analytics Engineering, William is always there to offer guidance, answer questions, and share his expertise.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content