This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
And so, there is no doubt that DataEngineers use it extensively to build and manage their ETL pipelines. The post DataEngineering 101– BranchPythonOperator in Apache Airflow appeared first on Analytics Vidhya. Introduction Apache Airflow is the most popular tool for workflow management.
The acronym ETL—Extract, Transform, Load—has long been the linchpin of modern data management, orchestrating the movement and manipulation of data across systems and databases. This methodology has been pivotal in data warehousing, setting the stage for analysis and informed decision-making.
Research Data Scientist Description : Research Data Scientists are responsible for creating and testing experimental models and algorithms. Key Skills: Mastery in machinelearning frameworks like PyTorch or TensorFlow is essential, along with a solid foundation in unsupervised learning methods.
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
Data Scientist Data scientists are responsible for designing and implementing data models, analyzing and interpreting data, and communicating insights to stakeholders. They require strong programming skills, knowledge of statistical analysis, and expertise in machinelearning.
Learn the basics of dataengineering to improve your ML modelsPhoto by Mike Benna on Unsplash It is not news that developing MachineLearning algorithms requires data, often a lot of data. The whole thing is very exciting, but where do I get the data from?
The field of data science is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for data science hires peak. Their insights must be in line with real-world goals.
These tools will help you streamline your machinelearning workflow, reduce operational overheads, and improve team collaboration and communication. Machinelearning (ML) is the technology that automates tasks and provides insights. It allows data scientists to build models that can automate specific tasks.
Navigating the World of DataEngineering: A Beginner’s Guide. A GLIMPSE OF DATAENGINEERING ❤ IMAGE SOURCE: BY AUTHOR Data or data? No matter how you read or pronounce it, data always tells you a story directly or indirectly. Dataengineering can be interpreted as learning the moral of the story.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
Customers use Amazon Redshift as a key component of their data architecture to drive use cases from typical dashboarding to self-service analytics, real-time analytics, machinelearning (ML), data sharing and monetization, and more.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machinelearning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Data Scientists and ML Engineers typically write lots and lots of code. From writing code for doing exploratory analysis, experimentation code for modeling, ETLs for creating training datasets, Airflow (or similar) code to generate DAGs, REST APIs, streaming jobs, monitoring jobs, etc. risk models vs. recommender systems).
He specializes in large language models, cloud infrastructure, and scalable data systems, focusing on building intelligent solutions that enhance automation and data accessibility across Amazons operations. Chaithanya Maisagoni is a Senior Software Development Engineer (AI/ML) in Amazons Worldwide Returns and ReCommerce organization.
ABOUT EVENTUAL Eventual is a data platform that helps data scientists and engineers build data applications across ETL, analytics and ML/AI. OUR PRODUCT IS OPEN-SOURCE AND USED AT ENTERPRISE SCALE Our distributed dataengine Daft [link] is open-sourced and runs on 800k CPU cores daily.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Machinelearning The 6 key trends you need to know in 2021 ? With a range of role types available, how do you find the perfect balance of Data Scientists , DataEngineers and Data Analysts to include in your team? The DataEngineer Not everyone working on a data science project is a data scientist.
Accordingly, one of the most demanding roles is that of Azure DataEngineer Jobs that you might be interested in. The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. How to Become an Azure DataEngineer?
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
She has experience across analytics, big data, ETL, cloud operations, and cloud infrastructure management. DataEngineer at Amazon Ads. He builds and manages data-driven solutions for recommendation systems, working together with a diverse and talented team of scientists, engineers, and product managers.
Data science bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of data science. They cover a wide range of topics, ranging from Python, R, and statistics to machinelearning and data visualization.
Dataengineering is a rapidly growing field that designs and develops systems that process and manage large amounts of data. There are various architectural design patterns in dataengineering that are used to solve different data-related problems.
Zeta’s AI innovation is powered by a proprietary machinelearning operations (MLOps) system, developed in-house. Context In early 2023, Zeta’s machinelearning (ML) teams shifted from traditional vertical teams to a more dynamic horizontal structure, introducing the concept of pods comprising diverse skill sets.
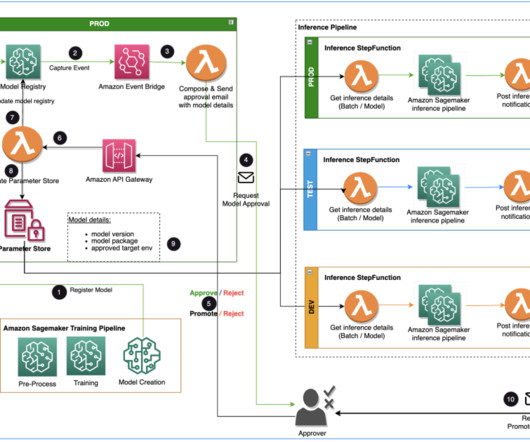
Specialist DataEngineering at Merck, and Prabakaran Mathaiyan, Sr. ML Engineer at Tiger Analytics. The large machinelearning (ML) model development lifecycle requires a scalable model release process similar to that of software development. This post is co-written with Jayadeep Pabbisetty, Sr.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
Data exploration and model development were conducted using well-known machinelearning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. Analytic data is stored in Amazon Redshift.
To start, get to know some key terms from the demo: Snowflake: The centralized source of truth for our initial data Magic ETL: Domo’s tool for combining and preparing data tables ERP: A supplemental data source from Salesforce Geographic: A supplemental data source (i.e., Instagram) used in the demo Why Snowflake?
Getting Started with AI in High-Risk Industries, How to Become a DataEngineer, and Query-Driven Data Modeling How To Get Started With Building AI in High-Risk Industries This guide will get you started building AI in your organization with ease, axing unnecessary jargon and fluff, so you can start today.
Unstructured data makes up 80% of the world's data and is growing. Managing unstructured data is essential for the success of machinelearning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. Unstructured.io
Big data management involves a series of processes, including collecting, cleaning, and standardizing data for analysis, while continuously accommodating new data streams. These procedures are central to effective data management and crucial for deploying machinelearning models and making data-driven decisions.
Amazon Lookout for Metrics is a fully managed service that uses machinelearning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required. To learn more, see the documentation.
Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machinelearning (ML) models. Data science and DevOps teams may face challenges managing these isolated tool stacks and systems. Scaling is one of the biggest issues in the machinelearning cycle.
More than 170 tech teams used the latest cloud, machinelearning and artificial intelligence technologies to build 33 solutions. LLMs excel at writing code and reasoning over text, but tend to not perform as well when interacting directly with time-series data.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Big Data Architect. Zach Mitchell is a Sr.
Just like this in Data Science we have Data Analysis , Business Intelligence , Databases , MachineLearning , Deep Learning , Computer Vision , NLP Models , Data Architecture , Cloud & many things, and the combination of these technologies is called Data Science. Data Science and AI are related?
Db2 Warehouse fully supports open formats such as Parquet, Avro, ORC and Iceberg table format to share data and extract new insights across teams without duplication or additional extract, transform, load (ETL). This allows you to scale all analytics and AI workloads across the enterprise with trusted data.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. Text data is often unstructured, making it challenging to directly apply machinelearning algorithms for sentiment analysis.
It offers the advantage of having a single ETL platform to develop and maintain. It is well-suited for developing data systems that emphasize online learning and do not require a separate batch layer. The Kappa architecture is particularly suitable when event streaming or real-time processing use cases are predominant.
Python is the top programming language used by dataengineers in almost every industry. Python has proven proficient in setting up pipelines, maintaining data flows, and transforming data with its simple syntax and proficiency in automation. Truly a must-have tool in your dataengineering arsenal!
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machinelearning (ML) models. Amazon SageMaker notebook jobs allow data scientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
Based on the McKinsey survey , 56% of orgs today are using machinelearning in at least one business function. AWS Sagemeaker is in fact a great tool for machinelearning operations (MLOps) to automate and standardize processes across the ML lifecycle. One DataEngineer: Cloud database integration with our cloud expert.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content