This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
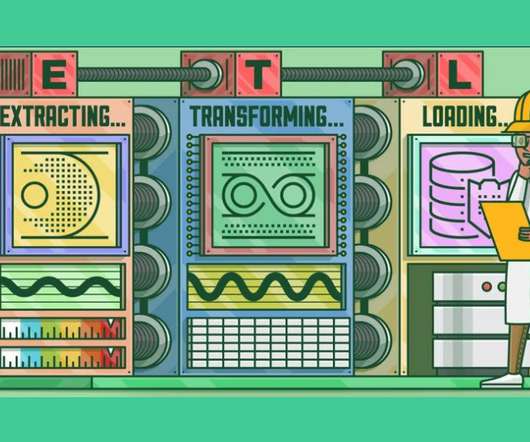
ArticleVideo Book This article was published as a part of the Data Science Blogathon Overview: Assume the job of a DataEngineer, extracting data from. The post Implementing ETL Process Using Python to Learn DataEngineering appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Overview ETL (Extract, Transform, and Load) is a very common technique in dataengineering. Traditionally, ETL processes are […]. The post Crafting Serverless ETL Pipeline Using AWS Glue and PySpark appeared first on Analytics Vidhya.
And so, there is no doubt that DataEngineers use it extensively to build and manage their ETL pipelines. The post DataEngineering 101– BranchPythonOperator in Apache Airflow appeared first on Analytics Vidhya. Introduction Apache Airflow is the most popular tool for workflow management.
This article was published as a part of the Data Science Blogathon What is ETL? ETL is a process that extracts data from multiple source systems, changes it (through calculations, concatenations, and so on), and then puts it into the Data Warehouse system. ETL stands for Extract, Transform, and Load.
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
Key Skills Proficiency in SQL is essential, along with experience in data visualization tools such as Tableau or Power BI. Strong analytical skills and the ability to work with large datasets are critical, as is familiarity with data modeling and ETL processes. This role builds a foundation for specialization.
So why using IaC for Cloud Data Infrastructures? For Data Warehouse Systems that often require powerful (and expensive) computing resources, this level of control can translate into significant cost savings. This brings reliability to dataETL (Extract, Transform, Load) processes, query performances, and other critical data operations.
DataEngineerDataengineers are responsible for building, maintaining, and optimizing data infrastructures. They require strong programming skills, expertise in data processing, and knowledge of database management.
Navigating the World of DataEngineering: A Beginner’s Guide. A GLIMPSE OF DATAENGINEERING ❤ IMAGE SOURCE: BY AUTHOR Data or data? No matter how you read or pronounce it, data always tells you a story directly or indirectly. Dataengineering can be interpreted as learning the moral of the story.
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)
In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. Extract, transform and Load Before we begin, let’s shed some light on what an ETL pipeline essentially is. ELT stands for extract, load and transform.
ABOUT EVENTUAL Eventual is a data platform that helps data scientists and engineers build data applications across ETL, analytics and ML/AI. OUR PRODUCT IS OPEN-SOURCE AND USED AT ENTERPRISE SCALE Our distributed dataengine Daft [link] is open-sourced and runs on 800k CPU cores daily.
It is designed to assist dataengineers in transforming, converting, and validating data in a simplified manner while ensuring accuracy and reliability. The Meltano CLI can efficiently handle complex dataengineering tasks, providing a user-friendly interface that simplifies the ELT process.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines.
To start, get to know some key terms from the demo: Snowflake: The centralized source of truth for our initial data Magic ETL: Domo’s tool for combining and preparing data tables ERP: A supplemental data source from Salesforce Geographic: A supplemental data source (i.e., Instagram) used in the demo Why Snowflake?
Accordingly, one of the most demanding roles is that of Azure DataEngineer Jobs that you might be interested in. The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. How to Become an Azure DataEngineer?
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Python is the top programming language used by dataengineers in almost every industry. Python has proven proficient in setting up pipelines, maintaining data flows, and transforming data with its simple syntax and proficiency in automation. Why Connect Snowflake to Python?
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
Data science bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of data science. They cover a wide range of topics, ranging from Python, R, and statistics to machine learning and data visualization.
Enrich dataengineering skills by building problem-solving ability with real-world projects, teaming with peers, participating in coding challenges, and more. Globally several organizations are hiring dataengineers to extract, process and analyze information, which is available in the vast volumes of data sets.
To keep myself sane, I use Airflow to automate tasks with simple, reusable pieces of code for frequently repeated elements of projects, for example: Web scraping ETL Database management Feature building and data validation And much more! Note that we can use the core python package datetime to help us define our DAGs.
The solution harnesses the capabilities of generative AI, specifically Large Language Models (LLMs), to address the challenges posed by diverse sensor data and automatically generate Python functions based on various data formats. The solution only invokes the LLM for new device data file type (code has not yet been generated).
Team Building the right data science team is complex. With a range of role types available, how do you find the perfect balance of Data Scientists , DataEngineers and Data Analysts to include in your team? The DataEngineer Not everyone working on a data science project is a data scientist.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Choose the plus sign and for Notebook , choose Python 3.
This setup uses the AWS SDK for Python (Boto3) to interact with AWS services. Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines.
Best practices are a pivotal part of any software development, and dataengineering is no exception. This ensures the data pipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently. What Are Matillion Jobs and Why Do They Matter?
Data Scientists and ML Engineers typically write lots and lots of code. From writing code for doing exploratory analysis, experimentation code for modeling, ETLs for creating training datasets, Airflow (or similar) code to generate DAGs, REST APIs, streaming jobs, monitoring jobs, etc.
Snowpark is the set of libraries and runtimes in Snowflake that securely deploy and process non-SQL code, including Python, Java, and Scala. On the server side, runtimes include Python, Java, and Scala in the warehouse model or Snowpark Container Services (public preview).
You can use this notebook job step to easily run notebooks as jobs with just a few lines of code using the Amazon SageMaker Python SDK. Data scientists currently use SageMaker Studio to interactively develop their Jupyter notebooks and then use SageMaker notebook jobs to run these notebooks as scheduled jobs.
Snowflake can not natively read files on these services, so an ETL service is needed to upload the data. Once an ETL process is set up, it is easy for users to break the pipeline by adding fields or modifying the source file in unexpected ways. ETL applications are often expensive and require some level of expertise to run.
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
Our activities mostly revolved around: 1 Identifying data sources 2 Collecting & Integrating data 3 Developing Analytical/ML models 4 Integrating the above into a cloud environment 5 Leveraging the cloud to automate the above processes 6 Making the deployment robust & scalable Who was involved in the project?
It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A data warehouse. Data ingestion/integration services. Reverse ETL tools. Data orchestration tools. A Note on the Shift from ETL to ELT. Data scientists.
Set specific, measurable targets Data science goals to “increase sales” lack the clarity needed to evaluate success and secure ongoing funding. Audit existing data assets Inventory internal datasets, ETL capabilities, past analytical initiatives, and available skill sets.
Finally, Tableau allows you to create custom territories using Tableau groups and overlay data with demographic information, giving you a comprehensive view of your data. To really unlock the full potential of your data, you need to be able to modify it with familiar tools before you analyze it in Tableau.
Airflow for workflow orchestration Airflow schedules and manages complex workflows, defining tasks and dependencies in Python code. An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time.
The Widespread Adoption of Open DataScience The use of open source data science tools has absolutely explodedwere talking a whopping 650% growth over the past five years. Additionally, a clear majority of current projects ( 85% to be exact) leverage open-source programming languages like Python and R rather than proprietary options.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities.
Now that the topic is created let’s generate some data. Instead of manually generating data or using programming languages like Python, we will use a datagen connector already installed as part of the initial configuration. Create the topic with all default settings and a single partition.
ThoughSpot can easily connect to top cloud data platforms such as Snowflake AI Data Cloud , Oracle, SAP HANA, and Google BigQuery. In that case, ThoughtSpot also leverages ELT/ETL tools and Mode, a code-first AI-powered data solution that gives data teams everything they need to go from raw data to the modern BI stack.
May be useful Best Workflow and Pipeline Orchestration Tools: Machine Learning Guide Phase 1—Data pipeline: getting the house in order Once the dust was settled, we got the Architecture Canvas completed, and the plan was clear to everyone involved, the next step was to take a closer look at the architecture. What’s in the box?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content