This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Overview Learn about viewing data as streams of immutable events in contrast to mutable containers Understand how Apache Kafka captures real-time data through event. The post Apache Kafka: A Metaphorical Introduction to Event Streaming for Data Scientists and DataEngineers appeared first on Analytics Vidhya.
Introduction A data model is an abstraction of real-world events that we use to create, capture, and store data in a database that user applications require, omitting unnecessary details. The post Data Abstraction for DataEngineering with its Different Levels appeared first on Analytics Vidhya.
Whether you’re a researcher, developer, startup founder, or simply an AI enthusiast, these events provide an opportunity to learn from the best, gain hands-on experience, and discover the future of AI. If youre serious about staying at the forefront of AI, development, and emerging tech, DeveloperWeek 2025 is a must-attend event.
In this four-part blog series "Lessons learned from building Cybersecurity Lakehouses," we will discuss a number of challenges organizations face with dataengineering.
AI conferences and events are organized to talk about the latest updates taking place, globally. Why must you attend AI conferences and events? Attending global AI-related virtual events and conferences isn’t just a box to check off; it’s a gateway to navigating through the dynamic currents of new technologies. billion by 2032.
They allow data processing tasks to be distributed across multiple machines, enabling parallel processing and scalability. It involves various technologies and techniques that enable efficient data processing and retrieval. Stay tuned for an insightful exploration into the world of Big DataEngineering with Distributed Systems!
EventsData + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
These experiences facilitate professionals from ingesting data from different sources into a unified environment and pipelining the ingestion, transformation, and processing of data to developing predictive models and analyzing the data by visualization in interactive BI reports. In the menu bar on the left, select Workspaces.
New big data architectures and, above all, data sharing concepts such as Data Mesh are ideal for creating a common database for many data products and applications. The Event Log Data Model for Process Mining Process Mining as an analytical system can very well be imagined as an iceberg.
Introduction to Apache Flume Apache Flume is a data ingestion mechanism for gathering, aggregating, and transmitting huge amounts of streaming data from diverse sources, such as log files, events, and so on, to a centralized data storage. It has a simplistic and adaptable […].
Initially, it was designed to handle log data solely, but later, it was developed to process eventdata. Introduction Apache Flume, a part of the Hadoop ecosystem, was developed by Cloudera. The Apache Flume tool is designed mainly for ingesting a high volume […]. The post Get to Know Apache Flume from Scratch!
Introduction Azure Functions is a serverless computing service provided by Azure that provides users a platform to write code without having to provision or manage infrastructure in response to a variety of events. Azure functions allow developers […] The post How to Develop Serverless Code Using Azure Functions?
After this inspiring start, mentees had the opportunity to participate in speed mentoring sessions, where they engaged with some of the best leaders in data science, AI, big data-driven solutions, sales, business development, dataengineering, partnerships, and more.
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. Thats where dataengineering tools come in!
Obstacles for dataengineers & developers Collection and maintenance of data from different sources is itself a hectic task for dataengineers and developers. Connectors are packaged as Docker images, which allows total flexibility over the technologies used to implement them.
Now that we’re in 2024, it’s important to remember that dataengineering is a critical discipline for any organization that wants to make the most of its data. These data professionals are responsible for building and maintaining the infrastructure that allows organizations to collect, store, process, and analyze data.
This article was published as a part of the Data Science Blogathon. convenient Introduction AWS Lambda is a serverless computing service that lets you run code in response to events while having the underlying compute resources managed for you automatically.
Join DataRobot and leading organizations June 7 and 8 at DataRobot AI Experience 2022 (AIX) , a unique virtual event that will help you rapidly unlock the power of AI for your most strategic business initiatives. Join the virtual event sessions in your local time across Asia-Pacific, EMEA, and the Americas. Join DataRobot AIX June 7–8.
All these sites use some event streaming tool to monitor user activities. […]. Introduction Have you ever wondered how Instagram recommends similar kinds of reels while you are scrolling through your feed or ad recommendations for similar products that you were browsing on Amazon?
Introduction Apache Flume is a tool/service/data ingestion mechanism for gathering, aggregating, and delivering huge amounts of streaming data from diverse sources, such as log files, events, and so on, to centralized data storage. Flume is a tool that is very dependable, distributed, and customizable.
Specializing as a Data Scientist or DataEngineer Over time, you can pivot into roles focusing on machine learning and predictive modeling (Data Scientist) or building and maintaining data infrastructure (DataEngineer). This role builds a foundation for specialization.
In this webinar, Jan 15 @ 12PM EST, we'll offer solutions to the common challenges data scientists and dataengineers face when building a machine learning pipeline. Register now to attend live or to watch a recording afterwards.
We couldn’t be more excited to announce two events that will be co-located with ODSC East in Boston this April: The DataEngineering Summit and the Ai X Innovation Summit. These two co-located events represent an opportunity to dive even deeper into the topics and trends shaping these disciplines. Register for free today!
For the first time ever, the DataEngineering Summit will be in person! Co-located with the leading Data Science and AI Training Conference, ODSC East, this summit will gather the leading minds in DataEngineering in Boston on April 23rd and 24th. Interested in attending an ODSC event? Sign me up!
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Dataengineering is a hot topic in the AI industry right now. And as data’s complexity and volume grow, its importance across industries will only become more noticeable. But what exactly do dataengineers do? So let’s do a quick overview of the job of dataengineer, and maybe you might find a new interest.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
Dataengineering has become an integral part of the modern tech landscape, driving advancements and efficiencies across industries. So let’s explore the world of open-source tools for dataengineers, shedding light on how these resources are shaping the future of data handling, processing, and visualization.
Here are nine of the top AI conferences happening in North America in 2023 and 2024 that you must attend: Top AI events and conferences in North America attend in 2023 Big Data and AI TORONTO 2023: Big Data and AI Toronto is the premier event for data professionals in Canada.
ABOUT EVENTUAL Eventual is a data platform that helps data scientists and engineers build data applications across ETL, analytics and ML/AI. OUR PRODUCT IS OPEN-SOURCE AND USED AT ENTERPRISE SCALE Our distributed dataengine Daft [link] is open-sourced and runs on 800k CPU cores daily.
While speaking at AIMs event DES 2025, Manjunatha G, engineering and site leader at the 3M Global Technology Centre, laid out a practical path to integrate AI agents into dataengineering workflows.
We couldn’t be more excited to announce the first sessions for our second annual DataEngineering Summit , co-located with ODSC East this April. Join us for 2 days of talks and panels from leading experts and dataengineering pioneers. Is Gen AI A DataEngineering or Software Engineering Problem?
Come for the hands-on AI deep dives, but stay for the immersive events! DataEngineering Summit The DataEngineering Summit , co-located with ODSC West, is your ticket to optimizing efficiency, enhancing scalability, and successfully tackling the toughest data challenges. Check them out below!
Be sure to check out his talk, “ Building Data Contracts with Open Source Tools ,” there! Dataengineering is a critical function in all industries. However, dataengineering grows exponentially as the company grows, acquires, or merges with others. He is passionate about software engineering and all things data.
Dataengineering in healthcare is taking a giant leap forward with rapid industrial development. However, data collection and analysis have been commonplace in the healthcare sector for ages. DataEngineering in day-to-day hospital administration can help with better decision-making and patient diagnosis/prognosis.
Dataengineering is a rapidly growing field that designs and develops systems that process and manage large amounts of data. There are various architectural design patterns in dataengineering that are used to solve different data-related problems.
Welcome to April’s employee series, Beyond the Data! We’re featuring DataEngineer Franco Borgiani from our LATAM office. I was born there but left when I decided to pursue a career as a Software Engineer. What do you actually do on any given day as a DataEngineer? As a DataEngineer, my daily tasks vary.
Data science and dataengineering are incredibly resource intensive. By using cloud computing, you can easily address a lot of these issues, as many data science cloud options have databases on the cloud that you can access without needing to tinker with your hardware.
Well, with the Open Pass, youll also enjoy a full series of networking events; the perfect way to unwind after a day after a full day of learning. At these networking events, youll be able to meet some of your fellow data practitioners who have come from all across the country. Theyre running out quickly, so dont missout!
Prescriptive analytics is a branch of data analytics that focuses on advising on optimal future actions based on data analysis. It transcends merely describing past events and predicting future occurrences by providing actionable recommendations that guide decision-making processes in organizations.
Welcome to Beyond the Data, a curious series that investigates the people behind the talent of phData. In this article, we’re featuring Deepa Ganiger, who serves as a Solution Architect/Lead DataEngineer at phData. On the weekends, I volunteer and take part in community events. Describing Deepa in just a few paragraphs?
In this representation, there is a separate store for events within the speed layer and another store for data loaded during batch processing. The serving layer acts as a mediator, enabling subsequent applications to access the data. This architectural concept relies on event streaming as the core element of data delivery.
Getting Started with AI in High-Risk Industries, How to Become a DataEngineer, and Query-Driven Data Modeling How To Get Started With Building AI in High-Risk Industries This guide will get you started building AI in your organization with ease, axing unnecessary jargon and fluff, so you can start today.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















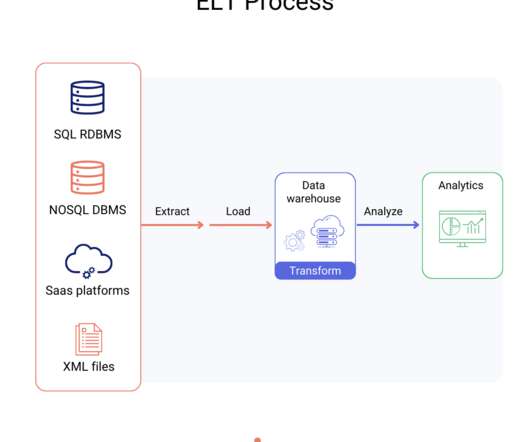




























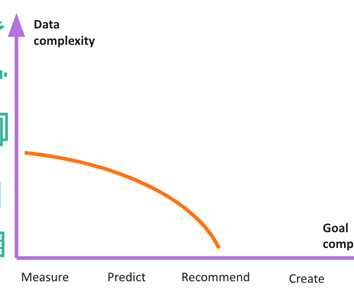






Let's personalize your content