This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The collection includes free courses on Python, SQL, Data Analytics, Business Intelligence, DataEngineering, MachineLearning, Deep Learning, Generative AI, and MLOps.
4 Useful Intermediate SQL Queries for Data Science • How to Select Rows and Columns in Pandas Using [ ],loc, iloc,at and.iat • 3 Free MachineLearning Courses for Beginners • 7 Essential Cheat Sheets for DataEngineering • 7 Techniques to Handle Imbalanced Data.
SQL and Python Interview Questions for Data Analysts • LearnMachineLearning From These GitHub Repositories • LearnDataEngineering From These GitHub Repositories • The ChatGPT Cheat Sheet • 5 Free Tools For Detecting ChatGPT, GPT3, and GPT2
Introduction Dear DataEngineers, this article is a very interesting topic. Let me give some flashback; a few years ago, Mr.Someone in the discussion coined the new word how ACID and BASE properties of DATA. The post Understand the ACID and BASE in Morden DataEngineering appeared first on Analytics Vidhya.
Research Data Scientist Description : Research Data Scientists are responsible for creating and testing experimental models and algorithms. Key Skills: Mastery in machinelearning frameworks like PyTorch or TensorFlow is essential, along with a solid foundation in unsupervised learning methods.
By Josep Ferrer , KDnuggets AI Content Specialist on June 10, 2025 in Python Image by Author DuckDB is a fast, in-process analytical database designed for modern data analysis. Its tight integration with Python and R makes it ideal for interactive data analysis. EXCLUDE, REPLACE, and ALL) to simplify query writing.
Machinelearning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Basic knowledge of a SQL query editor.
In the modern, cloud-centric business landscape, data is often scattered across numerous clouds and on-site systems. This fragmentation can complicate efforts by organizations to consolidate and analyze data for their machinelearning (ML) initiatives. You can now use the connector in your Athena queries.
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
Data Scientist Data scientists are responsible for designing and implementing data models, analyzing and interpreting data, and communicating insights to stakeholders. They require strong programming skills, knowledge of statistical analysis, and expertise in machinelearning.
By Cornellius Yudha Wijaya , KDnuggets Technical Content Specialist on June 10, 2025 in Python Image by Author | Ideogram Python has become a primary tool for many data professionals for data manipulation and machinelearning purposes because of how easy it is for people to use.
Abid Ali Awan ( @1abidaliawan ) is a certified data scientist professional who loves building machinelearning models. Currently, he is focusing on content creation and writing technical blogs on machinelearning and data science technologies.
What is Chebychev's Theorem and How Does it Apply to Data Science? Linux for Data Science Cheatsheet • The Complete DataEngineering Study Roadmap • 10 Amazing MachineLearning Visualizations You Should Know in 2023 • 7 SQL Concepts Needed for Data Science.
They allow data processing tasks to be distributed across multiple machines, enabling parallel processing and scalability. It involves various technologies and techniques that enable efficient data processing and retrieval. Stay tuned for an insightful exploration into the world of Big DataEngineering with Distributed Systems!
What to build : Develop a script that pulls data from a source (spreadsheet, database, or API), generates a report, and emails it to a predefined list of recipients on a schedule.
The data is obtained from the Internet via APIs and web scraping, and the job titles and the skills listed in them are identified and extracted from them using Natural Language Processing (NLP) or more specific from Named-Entity Recognition (NER). Over the time, it will provides you the answer on your questions related to which tool to learn!
Blog Top Posts About Topics AI Career Advice Computer Vision DataEngineeringData Science Language Models MachineLearning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Selling Your Side Project?
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. This can be overwhelming for nontechnical users who lack proficiency in SQL. This application allows users to ask questions in natural language and then generates a SQL query for the users request.
If you enjoy working with data, or if you’re just interested in a career with a lot of potential upward trajectory, you might consider a career as a dataengineer. But what exactly does a dataengineer do, and how can you begin your career in this niche? What Is a DataEngineer?
In an effort to learn more about our community, we recently shared a survey about machinelearning topics, including what platforms you’re using, in what industries, and what problems you’re facing. For currently-used machinelearning frameworks, some of the usual contenders were popular as expected.
This article was published as a part of the Data Science Blogathon Overview Databricks in simple terms is a data warehousing, machinelearning web-based platform developed by the creators of Spark. But Databricks is much more than that.
The data is stored in a data lake and retrieved by SQL using Amazon Athena. The following figure shows a search query that was translated to SQL and run. Data is normally stored in databases, and can be queried using the most common query language, SQL. The challenge is to assure quality.
Also: Highest paid positions in 2019 are DevOps, Data Scientist, DataEngineer (all over $100K) - Stack Overflow Salary Calculator, Updated; A neural net solves the three-body problem 100 million times faster; The Last SQL Guide for Data Analysis You’ll Ever Need; How YouTube is Recommending Your Next Video.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machinelearning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
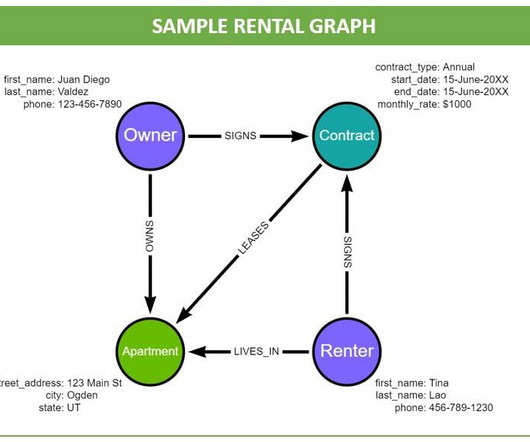
If you know SQL, you can easily learn Cypher and open up a huge opportunity for data analysis. Graph databases are quickly becoming a core part of the analytics toolset for enterprise IT organizations.
Summary: Dataengineering tools streamline data collection, storage, and processing. Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. What Does a DataEngineer Do?
The field of data science is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for data science hires peak.
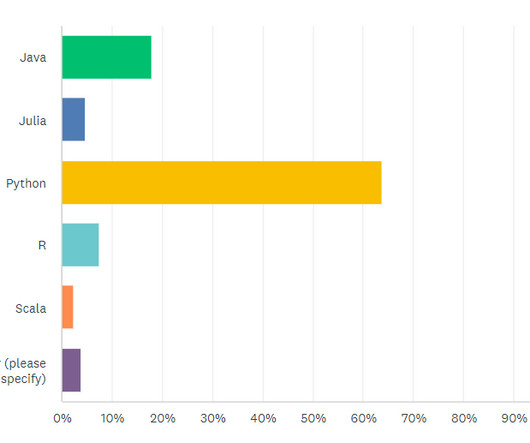
Recently, we posted the first article recapping our recent machinelearning survey. There, we talked about some of the results, such as what programming languages machinelearning practitioners use, what frameworks they use, and what areas of the field they’re interested in. As the chart shows, two major themes emerged.
In this panel, we will discuss how MLOps can help overcome challenges in operationalizing machinelearning models, such as version control, deployment, and monitoring. Additionally, how ML Ops is particularly helpful for large-scale systems like ad auctions, where high data volume and velocity can pose unique challenges.
OMRONs data strategyrepresented on ODAPalso allowed the organization to unlock generative AI use cases focused on tangible business outcomes and enhanced productivity. This tool democratizes data access across the organization, enabling even nontechnical users to gain valuable insights.
What is Chebychev's Theorem and How Does it Apply to Data Science? • Git for Data Science Cheatsheet • 7 SQL Concepts Needed for Data Science • The Complete DataEngineering Study Roadmap •.
Amazon SageMaker Feature Store is a purpose-built service to store and retrieve feature data for use by machinelearning (ML) models. Feature Store provides an online store capable of low-latency, high-throughput reads and writes, and an offline store that provides bulk access to all historical record data.
Repeat the steps to add another Aurora MySQL data source, called aggregated_sales , for the same database but with the following details in the Sync scope This data source will be used by Amazon Q for answering questions on aggregated sales. DataEngineer at Amazon Ads. For IAM role , choose Create a new service role.
The ability to quickly build and deploy machinelearning (ML) models is becoming increasingly important in today’s data-driven world. From data collection and cleaning to feature engineering, model building, tuning, and deployment, ML projects often take months for developers to complete.
Overview of core disciplines Data science encompasses several key disciplines including dataengineering, data preparation, and predictive analytics. Dataengineering lays the groundwork by managing data infrastructure, while data preparation focuses on cleaning and processing data for analysis.
While data science and machinelearning are related, they are very different fields. In a nutshell, data science brings structure to big data while machinelearning focuses on learning from the data itself. What is data science? What is machinelearning?
Dataengineering startup Prophecy is giving a new turn to data pipeline creation. Known for its low-code SQL tooling, the California-based company today announced data copilot, a generative AI assistant that can create trusted data pipelines from natural language prompts and improve pipeline quality …
Customers use Amazon Redshift as a key component of their data architecture to drive use cases from typical dashboarding to self-service analytics, real-time analytics, machinelearning (ML), data sharing and monetization, and more.
Data Science intertwines statistics, problem-solving, and programming to extract valuable insights from vast data sets. This discipline takes raw data, deciphers it, and turns it into a digestible format using various tools and algorithms. Tools such as Python, R, and SQL help to manipulate and analyze data.
Coding skills are essential for tasks such as data cleaning, analysis, visualization, and implementing machinelearning algorithms. You might be asking, “How to become a data scientist with a background in a different field?” MachinelearningMachinelearning is a key part of data science.
Azure Cognitive Services Named Entity Recognition gets some new types Persontype, product, event, organization, date are just some of them Amazon Aurora PostgreSQL Supports MachineLearning Aurora PostgreSQL can now use SQL to call ML models created with SageMaker. Google Announces BigQuery Data Challenge.
Data science bootcamps are intensive short-term educational programs designed to equip individuals with the skills needed to enter or advance in the field of data science. They cover a wide range of topics, ranging from Python, R, and statistics to machinelearning and data visualization.
Descriptive analytics is a fundamental method that summarizes past data using tools like Excel or SQL to generate reports. Techniques such as data cleansing, aggregation, and trend analysis play a critical role in ensuring data quality and relevance. Data Scientists require a robust technical foundation.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content