This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
DataEngineer. In this role, you would perform batch processing or real-time processing on data that has been collected and stored. As a dataengineer, you could also build and maintain data pipelines that create an interconnected data ecosystem that makes information available to data scientists.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machinelearning (ML) or generative AI. The following graphic shows how Amazon Bedrock is incorporated to support generative AI capabilities in the fraud detection systemarchitecture.
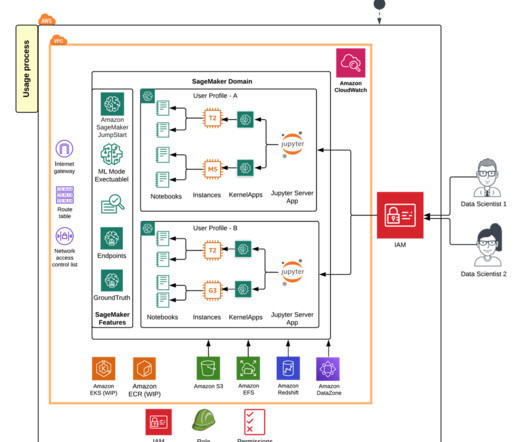
With organizations increasingly investing in machinelearning (ML), ML adoption has become an integral part of business transformation strategies. Architecture overview The inclusion of cloud-native serverless services from AWS is prioritized into the architecture of the PwC MLOps accelerator.
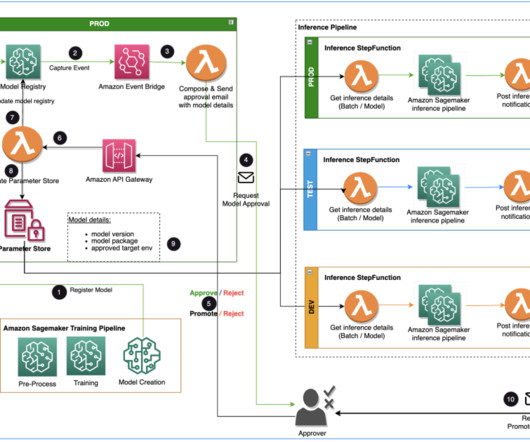
Specialist DataEngineering at Merck, and Prabakaran Mathaiyan, Sr. ML Engineer at Tiger Analytics. The large machinelearning (ML) model development lifecycle requires a scalable model release process similar to that of software development. This post is co-written with Jayadeep Pabbisetty, Sr.
Imagine this: we collect loads of data, right? Data Intelligence takes that data, adds a touch of AI and MachineLearning magic, and turns it into insights. It’s not just about having data; it’s about turning that data into real wisdom for better products and services. These insights?
It requires checking many systems and teams, many of which might be failing, because theyre interdependent. Developers need to reason about the systemarchitecture, form hypotheses, and follow the chain of components until they have located the one that is the culprit.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











Let's personalize your content