This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Growth Outlook: Companies like Google DeepMind, NASA’s Jet Propulsion Lab, and IBM Research actively seek research data scientists for their teams, with salaries typically ranging from $120,000 to $180,000. With the continuous growth in AI, demand for remote data science jobs is set to rise.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. A provisioned or serverless Amazon Redshift data warehouse.
Instead, organizations are increasingly looking to take advantage of transformative technologies like machine learning (ML) and artificial intelligence (AI) to deliver innovative products, improve outcomes, and gain operational efficiencies at scale. Data is presented to the personas that need access using a unified interface.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services.
OMRONs data strategyrepresented on ODAPalso allowed the organization to unlock generative AI use cases focused on tangible business outcomes and enhanced productivity. This tool democratizes data access across the organization, enabling even nontechnical users to gain valuable insights.
The field of data science is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for data science hires peak. Their insights must be in line with real-world goals.
Amazon SageMaker Feature Store provides an end-to-end solution to automate feature engineering for machine learning (ML). For many ML use cases, raw data like log files, sensor readings, or transaction records need to be transformed into meaningful features that are optimized for model training. SageMaker Studio set up.
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. HBase is employed to offer real-time key-based access to data.
Additionally, how ML Ops is particularly helpful for large-scale systems like ad auctions, where high data volume and velocity can pose unique challenges. AMA – Begin a Career in Data Science: In this AMA session, we will cover the essentials of starting a career in data science.
Accordingly, one of the most demanding roles is that of Azure DataEngineer Jobs that you might be interested in. The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. How to Become an Azure DataEngineer?
Businesses are increasingly using machine learning (ML) to make near-real-time decisions, such as placing an ad, assigning a driver, recommending a product, or even dynamically pricing products and services. As a result, some enterprises have spent millions of dollars inventing their own proprietary infrastructure for feature management.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
Customers use Amazon Redshift as a key component of their data architecture to drive use cases from typical dashboarding to self-service analytics, real-time analytics, machine learning (ML), data sharing and monetization, and more. Discover how you can use Amazon Redshift to build a data mesh architecture to analyze your data.
The machine learning systems developed by Machine Learning Engineers are crucial components used across various big data jobs in the data processing pipeline. Additionally, Machine Learning Engineers are proficient in implementing AI or ML algorithms. Is MLengineering a stressful job?
Team Building the right data science team is complex. With a range of role types available, how do you find the perfect balance of Data Scientists , DataEngineers and Data Analysts to include in your team? The DataEngineer Not everyone working on a data science project is a data scientist.
Azure Cognitive Services Named Entity Recognition gets some new types Persontype, product, event, organization, date are just some of them Amazon Aurora PostgreSQL Supports Machine Learning Aurora PostgreSQL can now use SQL to call ML models created with SageMaker. Google Announces BigQuery Data Challenge. Training and Courses.
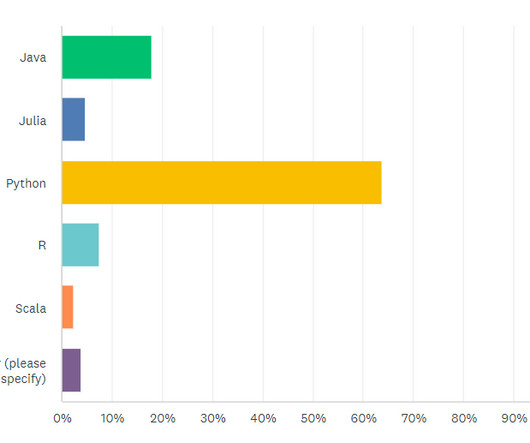
Just as a writer needs to know core skills like sentence structure, grammar, and so on, data scientists at all levels should know core data science skills like programming, computer science, algorithms, and so on. While knowing Python, R, and SQL are expected, you’ll need to go beyond that.
Snowpark is the set of libraries and runtimes in Snowflake that securely deploy and process non-SQL code, including Python , Java, and Scala. As a declarative language, SQL is very powerful in allowing users from all backgrounds to ask questions about data. Why Does Snowpark Matter? Who Should use Snowpark?
Utilizing your Snowflake data in AI and ML applications while keeping the data secure can be challenging. Even if it’s low, there’s always some chance of your data being compromised when it’s taken out of your Snowflake account. We’ll also explore some great AI and ML datasets from the Snowflake Marketplace.
Being one of the largest AWS customers, Twilio engages with data and artificial intelligence and machine learning (AI/ML) services to run their daily workloads. ML models don’t operate in isolation. This necessitates considering the entire ML lifecycle during design and development.
This involves collecting, cleaning, and analyzing large data sets to identify patterns, trends, and relationships that might otherwise be hidden. Skills in manipulating and managing data are also necessary to prepare the data for analysis. Machine learning Machine learning is a key part of data science.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
Amazon Lookout for Metrics is a fully managed service that uses machine learning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required. To learn more, see the documentation.
The ability to quickly build and deploy machine learning (ML) models is becoming increasingly important in today’s data-driven world. However, building ML models requires significant time, effort, and specialized expertise. This is where the AWS suite of low-code and no-code ML services becomes an essential tool.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
Amazon SageMaker Feature Store is a purpose-built service to store and retrieve feature data for use by machine learning (ML) models. Feature Store provides an online store capable of low-latency, high-throughput reads and writes, and an offline store that provides bulk access to all historical record data.
Query allowed customers from a broad range of industries to connect to clean useful data found in SQL and Cube databases. The prototype could connect to multiple data sources at the same time—a precursor to Tableau’s investments in data federation. Another key data computation moment was Hyper in v10.5 (Jan
Key Takeaways Business Analytics targets historical insights; Data Science excels in prediction and automation. Business Analytics requires business acumen; Data Science demands technical expertise in coding and ML. With added skills, professionals can shift between Business Analytics and Data Science.
Cloud Computing, APIs, and DataEngineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. TensorFlow is desired for its flexibility for ML and neural networks, PyTorch for its ease of use and innate design for NLP, and scikit-learn for classification and clustering.
Similarly, Function Pools pertains to the collection of functions or SQL templates that are pre-existing within our code base. Fortunately, the industry now offers easier ways to build UI applications with ML or LLM backends, using tools like Streamlit. For instance, if youre working on a […]
Using Azure ML to Train a Serengeti Data Model, Fast Option Pricing with DL, and How To Connect a GPU to a Container Using Azure ML to Train a Serengeti Data Model for Animal Identification In this article, we will cover how you can train a model using Notebooks in Azure Machine Learning Studio.
It offers magic ( %spark , %sql ) commands to run Spark code, perform SQL queries, and configure Spark settings like executor memory and cores. IT admins can standardize and expedite the provisioning of the solution in the cloud and avoid proliferation of custom development environments for ML projects.
Steamlining model management and deployment with SageMaker Amazon SageMaker is a managed machine learning platform that provides data scientists and dataengineers familiar concepts and tools to build, train, deploy, govern , and manage the infrastructure needed to have highly available and scalable model inference endpoints.
First, there’s a need for preparing the data, aka dataengineering basics. Machine learning practitioners are often working with data at the beginning and during the full stack of things, so they see a lot of workflow/pipeline development, data wrangling, and data preparation.
Navigating the Complex World of Financial DataEngineering Here’s an exploration of a recent podcast, which provides a roadmap for understanding the challenges, opportunities, and future of financial dataengineering. Register now!
Be sure to check out his talk, “ Using Graphs for Large Feature Engineering Pipelines ,” there to learn more about GraphReduce and more! For readers who work in ML/AI, it’s well understood that machine learning models prefer feature vectors of numerical information.
Big data analytics is evergreen, and as more companies use big data it only makes sense that practitioners are interested in analyzing data in-house. Deep learning is a fairly common sibling of machine learning, just going a bit more in-depth, so ML practitioners most often still work with deep learning.
Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare data for machine learning (ML) from weeks to minutes in Amazon SageMaker Studio. Starting today, you can connect to Amazon EMR Hive as a big data query engine to bring in large datasets for ML.
Mini-Bootcamp and VIP Pass holders will have access to four live virtual sessions on data science fundamentals. Confirmed sessions include: An Introduction to Data Wrangling with SQL with Sheamus McGovern, Software Architect, DataEngineer, and AI expert Programming with Data: Python and Pandas with Daniel Gerlanc, Sr.
However, there are some key differences that we need to consider: Size and complexity of the data In machine learning, we are often working with much larger data. Basically, every machine learning project needs data. Given the range of tools and data types, a separate data versioning logic will be necessary.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content