This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Von Big Data über Data Science zu AI Einer der Gründe, warum Big Data insbesondere nach der Euphorie wieder aus der Diskussion verschwand, war der Leitspruch “S**t in, s**t out” und die Kernaussage, dass Daten in großen Mengen nicht viel wert seien, wenn die Datenqualität nicht stimme. ChatGPT basiert auf GPT-3.5
This is how we came up with the DataEngine - an end-to-end solution for creating training-ready datasets and fast experimentation. Let’s explain how the DataEngine helps teams do just that. Preparing and organizing data into a format suitable for training models presents significant challenges for ML teams.
Even then, it is no trivial task, as it requires either: Developing custom in-house dev tools, Patching together currently available tools, or A mixture of both The release of DataEngine , however, enables even single developers to implement an active learning pipeline in short order. What is Active Learning?
Another promising approach is reinforcement learning and reasoning models, which allow AI to improve by reflecting on its own thought processes. This method not only expands the available training data but also enhances model efficiency and problem-solving abilities. Another challenge is data integration and consistency.
Given the availability of diverse data sources at this juncture, employing the CNN-QR algorithm facilitated the integration of various features, operating within a supervisedlearning framework. Utilizing Forecast proved effective due to the simplicity of providing the requisite data and specifying the forecast duration.
Playground available at [link] Official PyTorch codebase for the video joint-embedding predictive architecture, V-JEPA, a method for self-supervisedlearning of visual representations from video. The Open-Sora Plan project ‘s aim is to reproduce OpenAI’s Sora.
General and Efficient Self-supervisedLearning with data2vec Michael Auli | Principal Research Scientist at FAIR | Director at Meta AI This session will explore data2vec, a framework for general self-supervisedlearning that uses the same learning method for either speech, NLP, or computer vision. Sign me up!
Other challenges include communicating results to non-technical stakeholders, ensuring data security, enabling efficient collaboration between data scientists and dataengineers, and determining appropriate key performance indicator (KPI) metrics.
This capability allows Deep Learning models to excel in tasks such as image and speech recognition, natural language processing, and more. Job Roles and Responsibilities DataEngineering: Defining data requirements, collecting, cleaning, and preprocessing data for training Deep Learning models.
That said, I don’t think you’d go very far if you simply focused on the quantity of data. Organizations struggle in multiple aspects, especially in modern-day dataengineering practices and getting ready for successful AI outcomes. And in supervisedlearning, it has to be labeled data.
That said, I don’t think you’d go very far if you simply focused on the quantity of data. Organizations struggle in multiple aspects, especially in modern-day dataengineering practices and getting ready for successful AI outcomes. And in supervisedlearning, it has to be labeled data.
That said, I don’t think you’d go very far if you simply focused on the quantity of data. Organizations struggle in multiple aspects, especially in modern-day dataengineering practices and getting ready for successful AI outcomes. And in supervisedlearning, it has to be labeled data.
Our focus will be hands-on, with an emphasis on the practical application and understanding of essential machine learning concepts. Attendees will be introduced to a variety of machine learning algorithms, placing a spotlight on logistic regression, a potent supervisedlearning technique for solving binary classification problems.
In August 2019, Data Works was acquired and Dave worked to ensure a successful transition. David: My technical background is in ETL, data extraction, dataengineering and data analytics. What supervisedlearning methods did you use? David, what can you tell us about your background?
As AI has evolved, data scientists have acknowledged that building AI models takes a lot of data, energy and time, from compiling, labeling and processing data sets the models use to “learn” to the energy is takes to process the data and iteratively train the models.
Elementl / Dagster Labs Elementl and Dagster Labs are both companies that provide platforms for building and managing data pipelines. Elementl’s platform is designed for dataengineers, while Dagster Labs’ platform is designed for data scientists. However, there are some critical differences between the two companies.
Such scoring function can be added to any ML pipeline, including supervisedlearning in which you can add it as another metric to common metrics like AUC or accuracy. Ori has many years of experience as a software engineer and engineering manager, focused on cloud technologies and big data infrastructure.
Text labeling has enabled all sorts of frameworks and strategies in machine learning. Obviously, this is also a weak supervisedlearning approach, because the labels are not guaranteed to be 100% correct. LabelBox LabelBox is an AI-powered dataengine platform that supports text annotation along with other data types.
Text labeling has enabled all sorts of frameworks and strategies in machine learning. Obviously, this is also a weak supervisedlearning approach, because the labels are not guaranteed to be 100% correct. LabelBox LabelBox is an AI-powered dataengine platform that supports text annotation along with other data types.
In addition to incorporating all the fundamentals of Data Science, this Data Science program for working professionals also includes practical applications and real-world case studies. It also assists you in real-world projects and career guidance that eventually catalyzes your professional growth.
There are two main technologies that are empowering these automation labeling tools: Semi-SupervisedLearning: This technique combines the labeled and unlabeled data to improve consistency while reducing manual workload. In this technique, a model is trained on an initial labeled dataset.
Key Features Data Scientists as its core team of instructor Immersive learning experience Capstone Projects Internship opportunity Job guarantee Complete assistant for placement Instant doubt resolution Work on real-world data sets Course Curriculum The Data Mindset Thinking about data Anatomy of data – dimensions, quality, quantity Data manipulation (..)
Other users Some other users you may encounter include: Dataengineers , if the data platform is not particularly separate from the ML platform. Analytics engineers and data analysts , if you need to integrate third-party business intelligence tools and the data platform, is not separate. Allegro.io
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















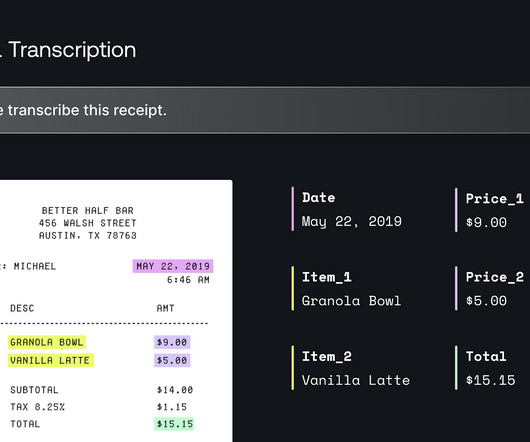
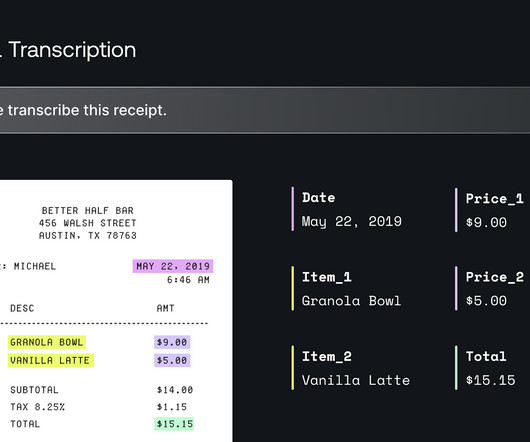










Let's personalize your content