This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Implementing a data fabric architecture is the answer. What is a data fabric? Data fabric is defined by IBM as “an architecture that facilitates the end-to-end integration of various datapipelines and cloud environments through the use of intelligent and automated systems.” This leaves more time for data analysis.
We exist in a diversified era of data tools up and down the stack – from storage to algorithm testing to stunning business insights. appeared first on DATAVERSITY.
Key components include data modelling, warehousing, pipelines, and integration. Effective datagovernance enhances quality and security throughout the data lifecycle. What is Data Engineering? They are crucial in ensuring data is readily available for analysis and reporting. from 2025 to 2030.
It helps companies streamline and automate the end-to-end ML lifecycle, which includes data collection, model creation (built on data sources from the software development lifecycle), model deployment, model orchestration, health monitoring and datagovernance processes.
Additionally, Alation and Paxata announced the new data exploration capabilities of Paxata in the Alation Data Catalog, where users can find trusted data assets and, with a single click, work with their data in Paxata’s Self-Service Data Prep Application. 3) Data professionals come in all shapes and forms.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring.
Automation Automation plays a pivotal role in streamlining ETL processes, reducing the need for manual intervention, and ensuring consistent data availability. By automating key tasks, organisations can enhance efficiency and accuracy, ultimately improving the quality of their datapipelines.
Snowflake AI Data Cloud is one of the most powerful platforms, including storage services supporting complex data. Integrating Snowflake with dbt adds another layer of automation and control to the datapipeline. Snowflake stored procedures and dbt Hooks are essential to modern data engineering and analytics workflows.
Support for Advanced Analytics : Transformed data is ready for use in Advanced Analytics, Machine Learning, and Business Intelligence applications, driving better decision-making. Compliance and Governance : Many tools have built-in features that ensure data adheres to regulatory requirements, maintaining datagovernance across organisations.
Strategies to Improve Data Quality High-quality data is a strategic asset that fuels innovation, drives informed decision-making, and enhances operational efficiency. DataGovernance and Management Effective datagovernance is the cornerstone of data quality.
To establish trust between the data producers and data consumers, SageMaker Catalog also integrates the data quality metrics and data lineage events to track and drive transparency in datapipelines. Data analysts discover the data and subscribe to the data.
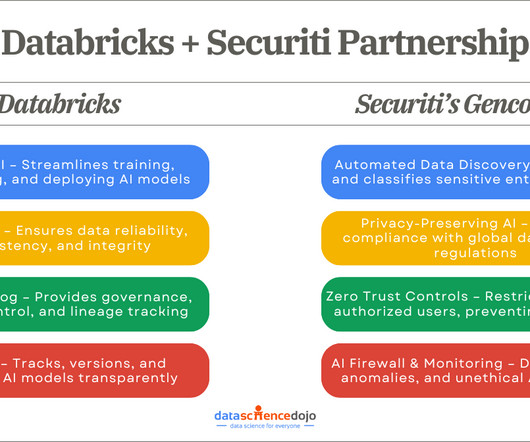
A robust infrastructure, strong datagovernance, and proactive security measures are some key requirements for the process. The partnership between Databricks and Gencore AI enables enterprises to develop AI applications with robust security measures, optimized datapipelines, and comprehensive governance.
This strategic decision was driven by several factors: Efficient datapreparation Building a high-quality pre-training dataset is a complex task, involving assembling and preprocessing text data from various sources, including web sources and partner companies. The team opted for fine-tuning on AWS.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content