This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and data engineering. They transform data into a consistent format for users to consume.
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
Suppose you’re in charge of maintaining a large set of datapipelines from cloud storage or streaming data into a datawarehouse. How can you ensure that your data meets expectations after every transformation? That’s where data quality testing comes in.
Datagovernance challenges Maintaining consistent datagovernance across different systems is crucial but complex. When needed, the system can access an ODAP datawarehouse to retrieve additional information. The following diagram shows a basic layout of how the solution works.
ELT advocates for loading raw data directly into storage systems, often cloud-based, before transforming it as necessary. This shift leverages the capabilities of modern datawarehouses, enabling faster data ingestion and reducing the complexities associated with traditional transformation-heavy ETL processes.
That’s why many organizations invest in technology to improve data processes, such as a machine learning datapipeline. However, data needs to be easily accessible, usable, and secure to be useful — yet the opposite is too often the case. These data requirements could be satisfied with a strong datagovernance strategy.
But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? A datapipeline is a series of processing steps that move data from its source to its destination. The answer?
The main goal of a data mesh structure is to drive: Domain-driven ownership Data as a product Self-service infrastructure Federated governance One of the primary challenges that organizations face is datagovernance. What is a Cloud DataWarehouse? Historically, there were big differences.
Cloud datawarehouses provide various advantages, including the ability to be more scalable and elastic than conventional warehouses. Can’t get to the data. All of this data might be overwhelming for engineers who struggle to pull in data sets quickly enough. Datapipeline maintenance.
Key components include data modelling, warehousing, pipelines, and integration. Effective datagovernance enhances quality and security throughout the data lifecycle. What is Data Engineering? It enables reporting and Data Analysis and provides a historical data record that can be used for decision-making.
Collecting, storing, and processing large datasets Data engineers are also responsible for collecting, storing, and processing large volumes of data. This involves working with various data storage technologies, such as databases and datawarehouses, and ensuring that the data is easily accessible and can be analyzed efficiently.
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into datawarehouses or databases for analysis. Loading The transformed data is loaded into the target destination, such as a datawarehouse.
Securing AI models and their access to data While AI models need flexibility to access data across a hybrid infrastructure, they also need safeguarding from tampering (unintentional or otherwise) and, especially, protected access to data. And that makes sense.
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse.
Data democratization instead refers to the simplification of all processes related to data, from storage architecture to data management to data security. It also requires an organization-wide datagovernance approach, from adopting new types of employee training to creating new policies for data storage.
In that sense, data modernization is synonymous with cloud migration. Modern data architectures, like cloud datawarehouses and cloud data lakes , empower more people to leverage analytics for insights more efficiently. What Is the Role of the Cloud in Data Modernization? DataPipeline Automation.
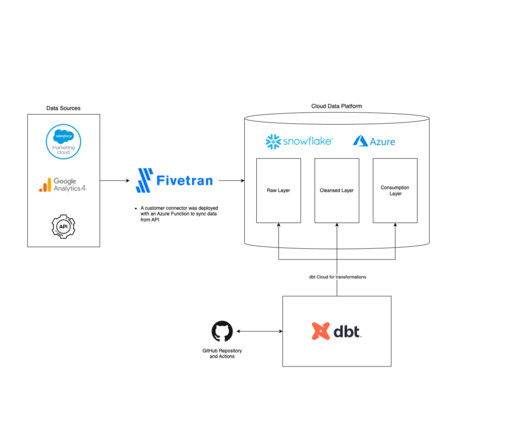
Understanding Fivetran Fivetran is a popular Software-as-a-Service platform that enables users to automate the movement of data and ETL processes across diverse sources to a target destination. The phData team achieved a major milestone by successfully setting up a secure end-to-end datapipeline for a substantial healthcare enterprise.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
Designing New DataPipelines Takes a Considerable Amount of Time and Knowledge Designing new ingestion pipelines is a complex undertaking that demands significant time and expertise. Engineering teams must maintain a complex web of ingestion pipelines capable of supporting many different sources, each with its own intricacies.
Wide support for enterprise-grade sources and targets Large organizations with complex IT landscapes must have the capability to easily connect to a wide variety of data sources. Whether it’s a cloud datawarehouse or a mainframe, look for vendors who have a wide range of capabilities that can adapt to your changing needs.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Read more to know. Cloud Platforms: AWS, Azure, Google Cloud, etc.
With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based datawarehouse.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for business intelligence and data science use cases. What does a modern data architecture do for your business?
Semantics, context, and how data is tracked and used mean even more as you stretch to reach post-migration goals. This is why, when data moves, it’s imperative for organizations to prioritize data discovery. Data discovery is also critical for datagovernance , which, when ineffective, can actually hinder organizational growth.
It is a data integration process that involves extracting data from various sources, transforming it into a suitable format, and loading it into a target system, typically a datawarehouse. ETL is the backbone of effective data management, ensuring organisations can leverage their data for informed decision-making.
When the data or pipeline configuration needs to be changed, tools like Fivetran and dbt reduce the time required to make the change, and increase the confidence your team can have around the change. These allow you to scale your pipelines quickly. Governance doesn’t have to be scary or preventative to your cloud datawarehouse.
It uses metadata and data management tools to organize all data assets within your organization. It synthesizes the information across your data ecosystem—from data lakes, datawarehouses, and other data repositories—to empower authorized users to search for and access business-ready data for their projects and initiatives.
It’s common to have terabytes of data in most datawarehouses, data quality monitoring is often challenging and cost-intensive due to dependencies on multiple tools and eventually ignored. To assign the DMF to the table, we must first add a data metric schedule to the table CUSTOMERS.
In data vault implementations, critical components encompass the storage layer, ELT technology, integration platforms, data observability tools, Business Intelligence and Analytics tools, DataGovernance , and Metadata Management solutions. Data Acquisition: Extracting data from source systems and making it accessible.
This individual is responsible for building and maintaining the infrastructure that stores and processes data; the kinds of data can be diverse, but most commonly it will be structured and unstructured data. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable.
We already know that a data quality framework is basically a set of processes for validating, cleaning, transforming, and monitoring data. DataGovernanceDatagovernance is the foundation of any data quality framework. It primarily caters to large organizations with complex data environments.
Fivetran includes features like data movement, transformations, robust security, and compatibility with third-party tools like DBT, Airflow, Atlan, and more. Its seamless integration with popular cloud datawarehouses like Snowflake can provide the scalability needed as your business grows.
ETL (Extract, Transform, Load) is a core process in data integration that involves extracting data from various sources, transforming it into a usable format, and loading it into a target system, such as a datawarehouse. Apache Nifi Apache Nifi is an open-source ETL tool that automates data flow between systems.
Snowflake enables organizations to instantaneously scale to meet SLAs with timely delivery of regulatory obligations like SEC Filings, MiFID II, Dodd-Frank, FRTB, or Basel III—all with a single copy of data enabled by data sharing capabilities across various internal departments.
The goal of digital transformation remains the same as ever – to become more data-driven. We have learned how to gain a competitive advantage by capturing business events in data. Events are data snap-shots of complex activity sourced from the web, customer systems, ERP transactions, social media, […].
Flow-Based Programming : NiFi employs a flow-based programming model, allowing users to create complex data flows using simple drag-and-drop operations. This visual representation simplifies the design and management of datapipelines. Its visual interface allows users to design complex ETL workflows with ease.
It accurately recognizes diverse data types and supports various table structures, excluding certain data types like GEOGRAPHY and BINARY. The process computes costs based on data volume. It enhances datagovernance by introducing a tagging mechanism.
Writing technical documents on database content Mapping the various databases used in an organisation Developing, designing and analysing data architecture and datawarehouses. BI Developers should be familiar with relational databases, data warehousing, datagovernance, and performance optimization techniques.
In the data-driven world we live in today, the field of analytics has become increasingly important to remain competitive in business. In fact, a study by McKinsey Global Institute shows that data-driven organizations are 23 times more likely to outperform competitors in customer acquisition and nine times […].
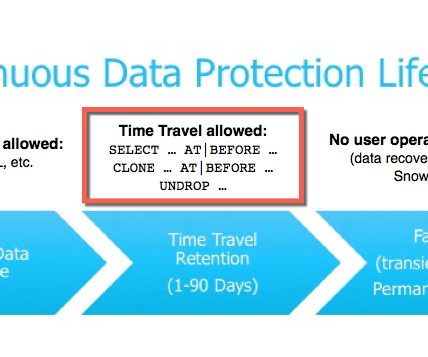
Cost Savings: If you want to reduce the cost of storing data in Snowflake, you can use external stages to unload data from Snowflake and store it in lower-cost external storage systems. The Snowflake STREAMS feature can create a stream, and an internal stage can be leveraged to store the data as it is being ingested.
Datagovernance: Ensure that the data used to train and test the model, as well as any new data used for prediction, is properly governed. For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, datagovernance becomes crucial.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. The existing Data Catalog becomes the Default catalog (identified by the AWS account number) and is readily available in SageMaker Lakehouse.
Practitioners and hands-on data users were thrilled to be there, and many connected as they shared their progress on their own data stack journeys. People were familiar with the value of a data catalog (and the growing need for datagovernance ), though many admitted to being somewhat behind on their journeys.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content