This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and data engineering. They transform data into a consistent format for users to consume.
In part one of this article, we discussed how data testing can specifically test a data object (e.g., table, column, metadata) at one particular point in the datapipeline.
Implementing a data fabric architecture is the answer. What is a data fabric? Data fabric is defined by IBM as “an architecture that facilitates the end-to-end integration of various datapipelines and cloud environments through the use of intelligent and automated systems.”
The acronym ETL—Extract, Transform, Load—has long been the linchpin of modern data management, orchestrating the movement and manipulation of data across systems and databases. This methodology has been pivotal in data warehousing, setting the stage for analysis and informed decision-making. Image credit ) 5.
This trust depends on an understanding of the data that inform risk models: where does it come from, where is it being used, and what are the ripple effects of a change? Moreover, banks must stay in compliance with industry regulations like BCBS 239, which focus on improving banks’ risk data aggregation and risk reporting capabilities.
Key components include data modelling, warehousing, pipelines, and integration. Effective datagovernance enhances quality and security throughout the data lifecycle. What is Data Engineering? This section explores essential aspects of Data Engineering. from 2025 to 2030.
Connecting directly to this semantic layer will help give customers access to critical business data in a safe, governed manner. This partnership makes data more accessible and trusted. Your data in the cloud. Tableau Prep allows you to combine, reshape, and clean data using an easy-to-use, visual, and direct interface.
Alation’s deep integration with tools like MicroStrategy and Tableau provides visibility into the complete datapipeline: from storage through visualization. Get the latest data cataloging news and trends in your inbox. In creating a single source of truth, MicroStrategy has reduced the risk of error or misinterpretation.
Collecting, storing, and processing large datasets Data engineers are also responsible for collecting, storing, and processing large volumes of data. This involves working with various data storage technologies, such as databases and data warehouses, and ensuring that the data is easily accessible and can be analyzed efficiently.
It integrates with Git and provides a Git-like interface for data versioning, allowing you to track changes, manage branches, and collaborate with data teams effectively. Dolt Dolt is an open-source relational database system built on Git. It could help you detect and prevent datapipeline failures, data drift, and anomalies.
We believe that this offering, Alation Tableau Edition, realizes the full promise of self-service analytics by allowing analysts to self-serve without making any of the errors of omission or commission that traditionally accompany an ungoverned data environment. We characterize this offering as Governance for Insight.
Data enrichment adds context to existing information, enabling business leaders to draw valuable new insights that would otherwise not have been possible. Managing an increasingly complex array of data sources requires a disciplined approach to integration, API management, and data security.
Data producers and consumers alike are working from home and hybrid locations more often. And in an increasingly remote workforce, people need to access data systems easily to do their jobs. This might mean that they’re accessing a database from a smartphone, computer, or tablet. Today, data dwells everywhere.
Snowflake AI Data Cloud is one of the most powerful platforms, including storage services supporting complex data. Integrating Snowflake with dbt adds another layer of automation and control to the datapipeline. Snowflake stored procedures and dbt Hooks are essential to modern data engineering and analytics workflows.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Warehousing: Amazon Redshift, Google BigQuery, etc.
Understanding Fivetran Fivetran is a popular Software-as-a-Service platform that enables users to automate the movement of data and ETL processes across diverse sources to a target destination. The phData team achieved a major milestone by successfully setting up a secure end-to-end datapipeline for a substantial healthcare enterprise.
Connecting directly to this semantic layer will help give customers access to critical business data in a safe, governed manner. This partnership makes data more accessible and trusted. Your data in the cloud. Tableau Prep allows you to combine, reshape, and clean data using an easy-to-use, visual, and direct interface.
Pipelines must have robust data integration capabilities that integrate data from multiple data silos, including the extensive list of applications used throughout the organization, databases and even mainframes. Changes to one database must also be reflected in any other database in real time.
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into data warehouses or databases for analysis. The goal is to retrieve the required data efficiently without overwhelming the source systems.
Who should have access to sensitive data? How can my analysts discover where data is located? All of these questions describe a concept known as datagovernance. The Snowflake AI Data Cloud has built an entire blanket of features called Horizon, which tackles all of these questions and more.
From structured data sources like ERPs, CRM, and relational data stores to unstructured data such as PDFs, images, and videos, enterprises are confronted with the daunting challenge of keeping up with their ever-expanding data ecosystem.
It’s common to have terabytes of data in most data warehouses, data quality monitoring is often challenging and cost-intensive due to dependencies on multiple tools and eventually ignored. This results in poor credibility and data consistency after some time, leading businesses to mistrust the datapipelines and processes.
Semantics, context, and how data is tracked and used mean even more as you stretch to reach post-migration goals. This is why, when data moves, it’s imperative for organizations to prioritize data discovery. Data discovery is also critical for datagovernance , which, when ineffective, can actually hinder organizational growth.
The audience grew to include data scientists (who were even more scarce and expensive) and their supporting resources (e.g., After that came datagovernance , privacy, and compliance staff. Power business users and other non-purely-analytic data citizens came after that. Data engineers want to catalog datapipelines.
Whether you’re bringing a new system online or connecting an existing database with your analytics platform, the process should be simple and straightforward. It synthesizes all the metadata around your organization’s data assets and arranges the information into a simple, easy-to-understand format.
Data democratization instead refers to the simplification of all processes related to data, from storage architecture to data management to data security. It also requires an organization-wide datagovernance approach, from adopting new types of employee training to creating new policies for data storage.
Because Alex can use a data catalog to search all data assets across the company, she has access to the most relevant and up-to-date information. She can search structured or unstructured data, visualizations and dashboards, machine learning models, and database connections. Protected and compliant data.
They created each capability as modules, which can either be used independently or together to build automated datapipelines. Alation’s governance capabilities include automated classification, profiling, data quality, lineage, stewardship, and deep policy integration with leading cloud-native databases like Snowflake.
When the data or pipeline configuration needs to be changed, tools like Fivetran and dbt reduce the time required to make the change, and increase the confidence your team can have around the change. These allow you to scale your pipelines quickly. Governance doesn’t have to be scary or preventative to your cloud data warehouse.
A broken datapipeline might bring operational systems to a halt, or it could cause executive dashboards to fail, reporting inaccurate KPIs to top management. Is your datagovernance structure up to the task? Read What Is Data Observability? Complexity leads to risk.
This oftentimes leads to shadow IT processes and duplicated datapipelines. Data is siloed, and there is no singular source of truth but fragmented data spread across the organization. Establishing a data culture changes this paradigm. The business will find other means to answer their questions.
The phData Toolkit continues to have additions made to it as we work with customers to accelerate their migrations , build a datagovernance practice , and ensure quality data products are built. This includes things like creating and modifying databases, schemas, and permissions. But what does this actually mean?
What does a modern data architecture do for your business? A modern data architecture like Data Mesh and Data Fabric aims to easily connect new data sources and accelerate development of use case specific datapipelines across on-premises, hybrid and multicloud environments.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date. mp4,webm, etc.), and audio files (.wav,mp3,acc,
Here are steps you can follow to pursue a career as a BI Developer: Acquire a solid foundation in data and analytics: Start by building a strong understanding of data concepts, relational databases, SQL (Structured Query Language), and data modeling. Knowledge of tools like D3.js
The main goal of a data mesh structure is to drive: Domain-driven ownership Data as a product Self-service infrastructure Federated governance One of the primary challenges that organizations face is datagovernance. This is “ lift-and-shift,” while it works, it doesn’t take full advantage of the cloud.
The required architecture includes a datapipeline, ML pipeline, application pipeline and a multi-stage pipeline. Let’s dive into the data management pipeline. What are the Key Elements of Data Management in Gen AI? The third is substituting names and SSNs with masked data.
Flow-Based Programming : NiFi employs a flow-based programming model, allowing users to create complex data flows using simple drag-and-drop operations. This visual representation simplifies the design and management of datapipelines. Its visual interface allows users to design complex ETL workflows with ease.
In data vault implementations, critical components encompass the storage layer, ELT technology, integration platforms, data observability tools, Business Intelligence and Analytics tools, DataGovernance , and Metadata Management solutions. The most important reason for using DBT in Data Vault 2.0
Access Controls and User Authentication Access control regulates who can interact with various database objects, such as tables, views, and functions. In Snowflake, securable objects (representing database resources) are controlled through roles. The process computes costs based on data volume.
Top Use Cases of Snowpark With Snowpark, bringing business logic to data in the cloud couldn’t be easier. Transitioning work to Snowpark allows for faster ML deployment, easier scaling, and robust datapipeline development. ML Applications For data scientists, models can be developed in Python with common machine learning tools.
Manage data with a seamless, consistent design experience – no need for complex coding or highly technical skills. Simply design datapipelines, point them to the cloud environment, and execute. What does all this mean for your business?
Data storage is a vital aspect of any Snowflake Data Cloud database. Within Snowflake, data can either be stored locally or accessed from other cloud storage systems. In Snowflake, there are three different storage layers available, Database, Stage, and Cloud Storage.
This process enables businesses to consolidate data from different platforms, ensuring it’s ready for analysis and decision-making. The first step in the ETL process is extraction, where data is gathered from different sources, such as databases, cloud services, or flat files.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








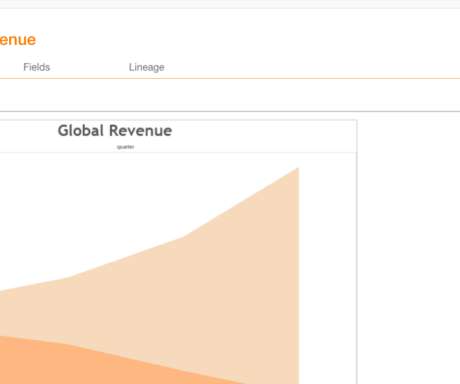






















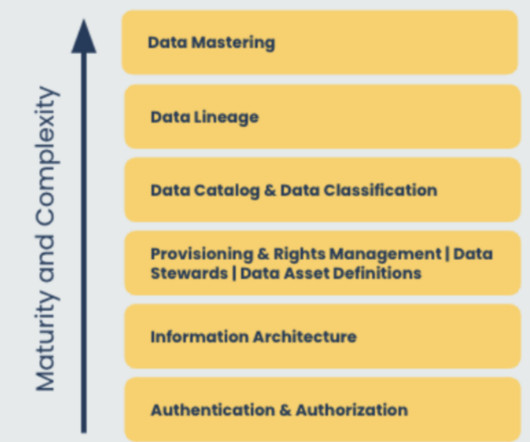





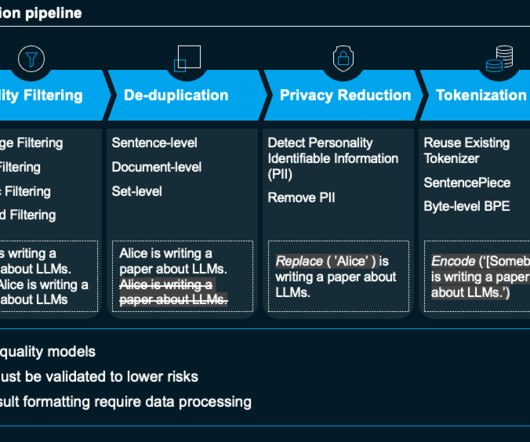


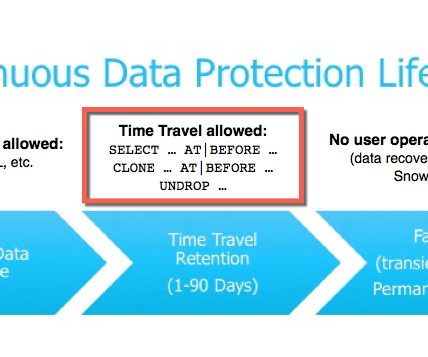










Let's personalize your content