This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In fact, it’s been more than three decades of innovation in this market, resulting in the development of thousands of data tools and a global datapreparation tools market size that’s set […] The post Why Is DataQuality Still So Hard to Achieve? appeared first on DATAVERSITY.
This technological advancement not only empowers data analysts but also enables non-technical users to engage with data effortlessly, paving the way for enhanced insights and agile strategies. Augmented analytics is the integration of ML and NLP technologies aimed at automating several aspects of datapreparation and analysis.
If we asked you, “What does your organization need to help more employees be data-driven?” where would “better datagovernance” land on your list? We’re all trying to use more data to make decisions, but constantly face roadblocks and trust issues related to datagovernance. . A datagovernance framework.
If we asked you, “What does your organization need to help more employees be data-driven?” where would “better datagovernance” land on your list? We’re all trying to use more data to make decisions, but constantly face roadblocks and trust issues related to datagovernance. . A datagovernance framework.
Choose Data Wrangler in the navigation pane. On the Import and prepare dropdown menu, choose Tabular. A new data flow is created on the Data Wrangler console. Choose Get data insights to identify potential dataquality issues and get recommendations. For Analysis name , enter a name.
Select the SQL (Create a dynamic view of data)Tile Explanation: This feature allows users to generate dynamic SQL queries for specific segments without manualcoding. Choose Segment ColumnData Explanation: Segmenting column dataprepares the system to generate SQL queries for distinctvalues.
Read our eBook DataGovernance 101 Read this eBook to learn about the challenges associated with datagovernance and how to operationalize solutions. Read Common Data Challenges in Telecommunications As natural innovators, telecommunications firms have been early adopters of advanced analytics.
Summary: Dataquality is a fundamental aspect of Machine Learning. Poor-qualitydata leads to biased and unreliable models, while high-qualitydata enables accurate predictions and insights. What is DataQuality in Machine Learning? Bias in data can result in unfair and discriminatory outcomes.
Ensuring high-qualitydata A crucial aspect of downstream consumption is dataquality. Studies have shown that 80% of time is spent on datapreparation and cleansing, leaving only 20% of time for data analytics. This leaves more time for data analysis.
Generative AI (GenAI), specifically as it pertains to the public availability of large language models (LLMs), is a relatively new business tool, so it’s understandable that some might be skeptical of a technology that can generate professional documents or organize data instantly across multiple repositories.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. million per year.
With the increasing reliance on technology in our personal and professional lives, the volume of data generated daily is expected to grow. This rapid increase in data has created a need for ways to make sense of it all. The post DataPreparation and Raw Data in Machine Learning: Why They Matter appeared first on DATAVERSITY.
Users: data scientists vs business professionals People who are not used to working with raw data frequently find it challenging to explore data lakes. To comprehend and transform raw, unstructured data for any specific business use, it typically takes a data scientist and specialized tools.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring. Data monitoring tools help monitor the quality of the data.
Key Takeaways Data Engineering is vital for transforming raw data into actionable insights. Key components include data modelling, warehousing, pipelines, and integration. Effective datagovernance enhances quality and security throughout the data lifecycle. What is Data Engineering?
The data catalog also stores metadata (data about data, like a conversation), which gives users context on how to use each asset. It offers a broad range of data intelligence solutions, including analytics, datagovernance, privacy, and cloud transformation. Data Catalog by Type.
Data Collection The process begins with the collection of relevant and diverse data from various sources. This can include structured data (e.g., databases, spreadsheets) as well as unstructured data (e.g., DataPreparation Once collected, the data needs to be preprocessed and prepared for analysis.
By maintaining clean and reliable data, businesses can avoid costly mistakes, enhance operational efficiency, and gain a competitive edge in their respective industries. Best Data Hygiene Tools & Software Trifacta Wrangler Pros: User-friendly interface with drag-and-drop functionality. Provides real-time data monitoring and alerts.
Alation achieves a top-rank for Innovation within the peer group DataGovernance Products , according to BARC’s The Data Management Survey 22. Alation was ranked #1 in two KPIs within the DataGovernance Products peer group: Innovation and Innovation Power. Keen to learn more about the data catalog market?
Best Practices for ETL Efficiency Maximising efficiency in ETL (Extract, Transform, Load) processes is crucial for organisations seeking to harness the power of data. Implementing best practices can improve performance, reduce costs, and improve dataquality.
In part one of this series, I discussed how data management challenges have evolved and how datagovernance and security have to play in such challenges, with an eye to cloud migration and drift over time. These advanced data catalogs can speed the process and discover relationships and entities impossible with manual methods.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machine learning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction.
While data fabric is not a standalone solution, critical capabilities that you can address today to prepare for a data fabric include automated data integration, metadata management, centralized datagovernance, and self-service access by consumers.
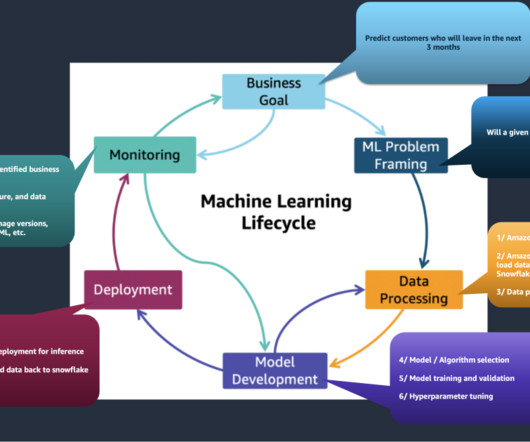
Ensuring dataquality, governance, and security may slow down or stall ML projects. Conduct exploratory analysis and datapreparation. Monitoring setup (model, data drift). Data Engineering Explore using feature store for future ML use cases. Determine the ML algorithm, if known or possible.
Businesses face significant hurdles when preparingdata for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
Important evaluation features include capabilities to preview a dataset, see all associated metadata, see user ratings, read user reviews and curator annotations, and view dataquality information. Benefits of a Data Catalog. Improved data efficiency. Improved data context. Improved data analysis.
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
Data Management – Efficient data management is crucial for AI/ML platforms. Regulations in the healthcare industry call for especially rigorous datagovernance. It should include features like data versioning, data lineage, datagovernance, and dataquality assurance to ensure accurate and reliable results.
The data value chain goes all the way from data capture and collection to reporting and sharing of information and actionable insights. As data doesn’t differentiate between industries, different sectors go through the same stages to gain value from it. Click to learn more about author Helena Schwenk.
Amazon SageMaker Catalog serves as a central repository hub to store both technical and business catalog information of the data product. To establish trust between the data producers and data consumers, SageMaker Catalog also integrates the dataquality metrics and data lineage events to track and drive transparency in data pipelines.
Key Takeaways: Trusted AI requires data integrity. For AI-ready data, focus on comprehensive data integration, dataquality and governance, and data enrichment. Building data literacy across your organization empowers teams to make better use of AI tools.
Unified model governance architecture ML governance enforces the ethical, legal, and efficient use of ML systems by addressing concerns like bias, transparency, explainability, and accountability. Prepare the data to build your model training pipeline.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content