This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
What is datagovernance and how do you measure success? Datagovernance is a system for answering core questions about data. It begins with establishing key parameters: What is data, who can use it, how can they use it, and why? Why is your datagovernance strategy failing?
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of datasilos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage.
Within the Data Management industry, it’s becoming clear that the old model of rounding up massive amounts of data, dumping it into a data lake, and building an API to extract needed information isn’t working. The post Why Graph Databases Are an Essential Choice for Master Data Management appeared first on DATAVERSITY.
Internal and external auditors work with many different systems to ensure this data is protected accordingly. This is where datagovernance comes in: A robust program allows banks and financial institutions to use this data to build customer trust and still meet compliance mandates. What is DataGovernance in Banking?
Insights from data gathered across business units improve business outcomes, but having heterogeneous data from disparate applications and storages makes it difficult for organizations to paint a big picture. How can organizations get a holistic view of data when it’s distributed across datasilos?
However, simply having high-quality data does not, of itself, ensure that an organization will find it useful. That is where data integrity comes into play. Data quality : Data must be complete, unique, valid, timely, and consistent in order to be useful for decision making.
Data virtualization empowers businesses to unlock the hidden potential of their data, delivering real-time AI insights for cutting-edge applications like predictive maintenance, fraud detection and demand forecasting. A data virtualization platform breaks down datasilos by using data virtualization.
Build an Ongoing Discipline for Data Integrity In the earlier stages of data maturity, many organizations view data integrity through the lens of data quality. Moreover, they tend to understand data quality improvement as a one-off exercise. That approach assumes that good data quality will be self-sustaining.
Overall, this partnership enables the retailer to make data-driven decisions, improve supply chain efficiency and ultimately boost customer satisfaction, all in a secure and scalable cloud environment. The platform provides an intelligent, self-service data ecosystem that enhances datagovernance, quality and usability.
Through workload optimization an organization can reduce data warehouse costs by up to 50 percent by augmenting with this solution. [1] 1] It also offers built-in governance, automation and integrations with an organization’s existing databases and tools to simplify setup and user experience.
This is where metadata, or the data about data, comes into play. Having a data catalog is the cornerstone of your datagovernance strategy, but what supports your data catalog? Your metadata management framework provides the underlying structure that makes your data accessible and manageable.
This is due to a fragmented ecosystem of datasilos, a lack of real-time fraud detection capabilities, and manual or delayed customer analytics, which results in many false positives. Snowflake Marketplace offers data from leading industry providers such as Axiom, S&P Global, and FactSet.
This requires access to data from across business systems when they need it. Datasilos and slow batch delivery of data will not do. Stale data and inconsistencies can distort the perception of what is really happening in the business leading to uncertainty and delay.
A data mesh is a decentralized approach to data architecture that’s been gaining traction as a solution to the challenges posed by large and complex data ecosystems. It’s all about breaking down datasilos, empowering domain teams to take ownership of their data, and fostering a culture of data collaboration.
Cloning Capabilities Zero copy cloning in Snowflake refers to the ability to create a clone of a database or table without physically duplicating the underlying data. This would involve adding a prefix or suffix to all databases to determine their environment.
Multiple data applications and formats make it harder for organizations to access, govern, manage and use all their data for AI effectively. Scaling data and AI with technology, people and processes Enabling data as a differentiator for AI requires a balance of technology, people and processes.
While data fabric is not a standalone solution, critical capabilities that you can address today to prepare for a data fabric include automated data integration, metadata management, centralized datagovernance, and self-service access by consumers. Increase metadata maturity.
Analyzing real-world healthcare and life sciences (HCLS) data poses several practical challenges, such as distributed datasilos, lack of sufficient data at any single site for rare events, regulatory guidelines that prohibit data sharing, infrastructure requirement, and cost incurred in creating a centralized data repository.
What Is Data Lake? A Data Lake is a centralized repository that allows businesses to store vast volumes of structured and unstructured data at any scale. Unlike traditional databases, Data Lakes enable storage without the need for a predefined schema, making them highly flexible.
Meaning, data architecture is a foundational element of your business strategy for higher data quality. Perform data quality monitoring based on pre-configured rules. Taking an inventory of existing data assets and mapping current data flows. Learn more about the benefits of data fabric and IBM Cloud Pak for Data.
Exploring technologies like Data visualization tools and predictive modeling becomes our compass in this intricate landscape. Datagovernance and security Like a fortress protecting its treasures, datagovernance, and security form the stronghold of practical Data Intelligence.
Analyzing real-world healthcare and life sciences (HCLS) data poses several practical challenges, such as distributed datasilos, lack of sufficient data at a single site for rare events, regulatory guidelines that prohibit data sharing, infrastructure requirement, and cost incurred in creating a centralized data repository.
. “ This sounds great in theory, but how does it work in practice with customer data or something like a ‘composable CDP’? Well, implementing transitional modeling does require a shift in how we think about and work with customer data. It often involves specialized databases designed to handle this kind of atomic, temporal data.
Although organizations don’t set out to intentionally create datasilos, they are likely to arise naturally over time. This can make collaboration across departments difficult, leading to inconsistent data quality , a lack of communication and visibility, and higher costs over time (among other issues). What Are DataSilos?
The primary objective of this idea is to democratize data and make it transparent by breaking down datasilos that cause friction when solving business problems. What Components Make up the Snowflake Data Cloud? This is “ lift-and-shift,” while it works, it doesn’t take full advantage of the cloud.
Data producers and consumers alike are working from home and hybrid locations more often. And in an increasingly remote workforce, people need to access data systems easily to do their jobs. This might mean that they’re accessing a database from a smartphone, computer, or tablet. Today, data dwells everywhere.
Some of the key benefits of this include: Simplified datagovernanceDatagovernance and data analytics support each other, and a strong datagovernance strategy is integral to ensuring that data analytics are reliable and actionable for decision-makers.
Even if organizations survive a migration to S/4 and HANA cloud, licensing and performance constraints make it difficult to perform advanced analytics on this data within the SAP environment. Additionally, change data markers are not available for many of these tables.
Through this unified query capability, you can create comprehensive insights into customer transaction patterns and purchase behavior for active products without the traditional barriers of datasilos or the need to copy data between systems. Data analysts discover the data and subscribe to the data.
The problem many companies face is that each department has its own data, technologies, and information handling processes. This causes datasilos to form, which can inhibit data visibility and collaboration, and lead to integrity issues that make it harder to share and use data.
They’re where the world’s transactional data originates – and because that essential data can’t remain siloed, organizations are undertaking modernization initiatives to provide access to mainframe data in the cloud. That approach assumes that good data quality will be self-sustaining.
Some of the key benefits of this include: Simplified datagovernanceDatagovernance and data analytics support each other, and a strong datagovernance strategy is integral to ensuring that data analytics are reliable and actionable for decision-makers.
The platform can be quickly deployed to start, but you will want to plan for the future so it’s scalable and performant as the data culture matures. A database storage layer is a central repository for the data, while computing is in another layer. Data democratization is the crux of self-service analytics.
Regulations like GDPR and CCPA, for example, require institutions to permit their customers to remove select types of personal information from internal databases. To achieve that, you need to know where your customer data resides across multiple systems and lines of business. Privacy requirements.
Data ingestion Data ingestion involves collecting various forms of datastructured, unstructured, and semi-structuredfrom multiple sources. This can include data at rest, such as databases, and data in motion, like live streaming data from IoT devices.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























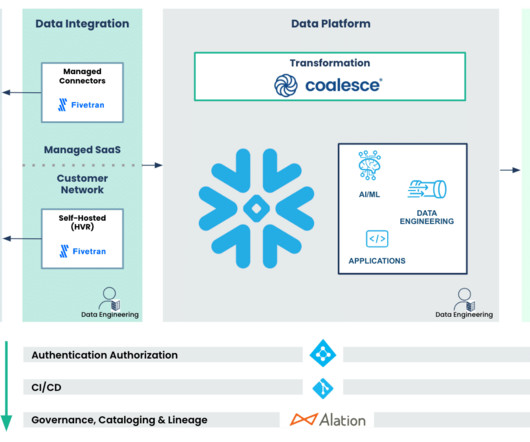




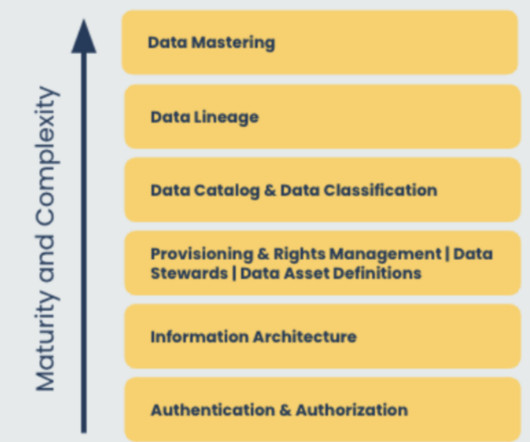








Let's personalize your content