This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post is part of an ongoing series about governing the machinelearning (ML) lifecycle at scale. This post dives deep into how to set up datagovernance at scale using Amazon DataZone for the data mesh. To view this series from the beginning, start with Part 1.
Research Data Scientist Description : Research Data Scientists are responsible for creating and testing experimental models and algorithms. Key Skills: Mastery in machinelearning frameworks like PyTorch or TensorFlow is essential, along with a solid foundation in unsupervised learning methods.
Ready to revolutionize the way you deploy machinelearning? MachineLearning (ML) has become an increasingly valuable tool for businesses and organizations to gain insights and make data-driven decisions. Here are some of the key advantages: Advantages of MLOps – Data Science Dojo 1.
Ready to revolutionize the way you deploy machinelearning? MachineLearning (ML) has become an increasingly valuable tool for businesses and organizations to gain insights and make data-driven decisions. Here are some of the key advantages: Advantages of ML Ops – Data Science Dojo 1.
Artificial Intelligence (AI) stands at the forefront of transforming datagovernance strategies, offering innovative solutions that enhance data integrity and security. In this post, let’s understand the growing role of AI in datagovernance, making it more dynamic, efficient, and secure.
This article explores the critical role of datagovernance in ensuring the accuracy, compliance, and integrity of data throughout AI model development and deployment.
Datagovernance is going to be one of the most crucial things in the future as we work towards more adoption of artificial intelligence and machinelearning. A huge component of artificial intelligence is machinelearning. This will only work if they have access to that unlimited data.
With rapid advancements in machinelearning, generative AI, and big data, 2025 is set to be a landmark year for AI discussions, breakthroughs, and collaborations. MachineLearning & AI Applications Discover the latest advancements in AI-driven automation, natural language processing (NLP), and computer vision.
Amazon DataZone makes it straightforward for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization so they can discover, use, and collaborate to derive data-driven insights. He supports enterprise customers migrate and modernize their workloads on AWS cloud.
While DevOps and MLOps share many similarities, MLOps requires a more specialized set of tools and practices to address the unique challenges posed by data-driven and computationally intensive ML workflows. ZenML is intended to be a highly extensible and adaptable MLOps framework.
What is datagovernance and how do you measure success? Datagovernance is a system for answering core questions about data. It begins with establishing key parameters: What is data, who can use it, how can they use it, and why? Why is your datagovernance strategy failing?
The practitioner asked me to add something to a presentation for his organization: the value of datagovernance for things other than data compliance and data security. Now to be honest, I immediately jumped onto data quality. Data quality is a very typical use case for datagovernance.
DataOps practices help organizations overcome challenges caused by fragmented teams and processes and delays in delivering data in consumable forms. So how does datagovernance relate to DataOps? Datagovernance is a key data management process. Continuous Improvement Applied to DataGovernance.
In this blog, we will share the list of leading data science conferences across the world to be held in 2023. This will help you to learn and grow your career in data science, AI and machinelearning. Top data science conferences 2023 in different regions of the world 1.
However, the increasing complexity of the data landscape is making it a huge challenge to provide users and applications with fast access required, while ensuring regulatory compliance.
The post DataGovernance at the Edge of the Cloud appeared first on DATAVERSITY. With that, I’ve long believed that for most large cloud platform providers offering managed services, such as document editing and storage, email services and calendar […].
generally available on May 24, Alation introduces the Open Data Quality Initiative for the modern data stack, giving customers the freedom to choose the data quality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and DataGovernance application.
But the widespread harnessing of these tools will also soon create an epic flood of content based on unstructured data – representing an unprecedented […] The post Navigating the Risks of LLM AI Tools for DataGovernance appeared first on DATAVERSITY.
Key Takeaways: Data integrity is essential for AI success and reliability – helping you prevent harmful biases and inaccuracies in AI models. Robust datagovernance for AI ensures data privacy, compliance, and ethical AI use. Proactive data quality measures are critical, especially in AI applications.
Modern data quality practices leverage advanced technologies, automation, and machinelearning to handle diverse data sources, ensure real-time processing, and foster collaboration across stakeholders.
In Ryan’s “9-Step Process for Better Data Quality” he discussed the processes for generating data that business leaders consider trustworthy. To be clear, data quality is one of several types of datagovernance as defined by Gartner and the DataGovernance Institute. Frequency of data?
Despite its many benefits, the emergence of high-performance machinelearning systems for augmented analytics over the last 10 years has led to a growing “plug-and-play” analytical culture, where high volumes of opaque data are thrown arbitrarily at an algorithm until it yields useful business intelligence.
The best way to build a strong foundation for data success is through effective datagovernance. Access to high-quality data can help organizations start successful products, defend against digital attacks, understand failures and pivot toward success.
Augmented analytics is revolutionizing how organizations interact with their data. By harnessing the power of machinelearning (ML) and natural language processing (NLP), businesses can streamline their data analysis processes and make more informed decisions.
Predictive healthcare analytics refers to the use of advanced data analytics techniques, such as artificial intelligence, machinelearning, data mining, and statistical modeling, to forecast future health outcomes based on historical data. What is predictive healthcare analytics?
Data has become a driving force behind change and innovation in 2025, fundamentally altering how businesses operate. Across sectors, organizations are using advancements in artificial intelligence (AI), machinelearning (ML), and data-sharing technologies to improve decision-making, foster collaboration, and uncover new opportunities.
Here are some of the key trends and challenges facing telecommunications companies today: The growth of AI and machinelearning: Telecom companies use artificial intelligence and machinelearning (AI/ML) for predictive analytics and network troubleshooting. Data integration and data integrity are lacking.
Because of this, when we look to manage and govern the deployment of AI models, we must first focus on governing the data that the AI models are trained on. This datagovernance requires us to understand the origin, sensitivity, and lifecycle of all the data that we use. and watsonx.data.
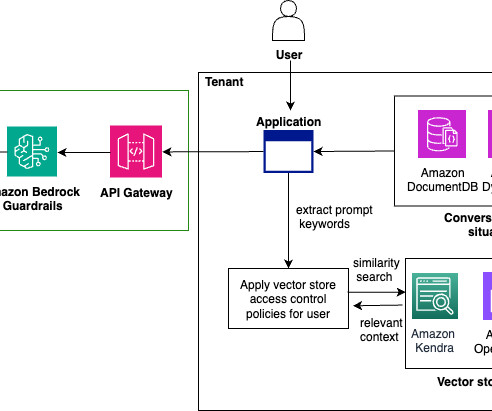
Here you also have the data sources, processing pipelines, vector stores, and datagovernance mechanisms that allow tenants to securely discover, access, andthe data they need for their specific use case. At this point, you need to consider the use case and data isolation requirements.
Attendees will learn about key LLM strategies, proven techniques, and real-world examples of how LLMs are being used to transform data processes. Bhatti is a hands-on practitioner of machinelearning and has extensive experience in applying AI to solve real-world problems. Registration will open in November 2023.
In this blog, we’ll unpack the differences between data and AI governance, examining the new factors leaders must consider when designing their AI governance programs. What makes AI governance different from datagovernance?
Datagovernance is rapidly shifting from a leading-edge practice to a must-have framework for today’s enterprises. Although the term has been around for several decades, it is only now emerging as a widespread practice, as organizations experience the pain and compliance challenges associated with ungoverned data.
As firms mature their transformation efforts, applying Artificial Intelligence (AI), machinelearning (ML) and Natural Language Processing (NLP) to the data is key to putting it into action quickly and effecitvely. Using bad data, or the incorrect data can generate devastating results. between 2022 and 2029.
Summary: Data quality is a fundamental aspect of MachineLearning. Poor-quality data leads to biased and unreliable models, while high-quality data enables accurate predictions and insights. What is Data Quality in MachineLearning? What is Data Quality in MachineLearning?
Datagovernance is no trivial undertaking. When executed correctly, datagovernance transitions businesses from guesswork to data-informed strategies. For those who follow the right roadmap on their datagovernance journey, the payoff can be enormous.
The state of datagovernance is evolving as organizations recognize the significance of managing and protecting their data. With stricter regulations and greater demand for data-driven insights, effective datagovernance frameworks are critical. What is a data architect?
Data observability continuously monitors data pipelines and alerts you to errors and anomalies. Datagovernance ensures AI models have access to all necessary information and that the data is used responsibly in compliance with privacy, security, and other relevant policies. stored: where is it located?
You can perform analytics with Data Lakes without moving your data to a different analytics system. 4. Additionally, unprocessed, raw data is pliable and suitable for machinelearning. Healthcare: Unstructured data is stored in data lakes. References: Data lake vs data warehouse
Data is the foundation for machinelearning (ML) algorithms. One of the most common formats for storing large amounts of data is Apache Parquet due to its compact and highly efficient format. In this post, we show you how to import Parquet data to Canvas from Athena, where Lake Formation enables datagovernance.
Data privacy and security matter. Given this, it will be a big deal if machinelearning can make them easier to implement. So, how do CIOs and other security thought leaders think machinelearning applies to privacy and security?
Introduction Machinelearning models learn patterns from data and leverage the learning, captured in the model weights, to make predictions on new, unseen data. Data, is therefore, essential to the quality and performance of machinelearning models. million per year.
Companies use MachineLearning to make their processes smooth, fast, and convenient. However, there are barriers to machinelearning, and the journey to adopting these kind of projects can be challenging. The extraction of data is another thing to consider. These phases are essential for having good data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content